
Kubernetes資源管理之--資源預留
1. 概述
1.1 問題
系統資源可分為兩類:可壓縮資源(CPU)和不可壓縮資源(memory、storage)。可壓縮資源比如CPU超配後,在系統滿負荷時會劃分時間片分時執行程序,系統整體會變慢(一般不會導致太大的問題)。但不可壓縮資源如Memory,當系統記憶體不足時,就有可能觸發系統 OOM;這時候根據 oom score 來確定優先殺死哪個程序,而 oom_score_adj 又是影響 oom score 的重要引數,其值越低,表示 oom 的優先順序越低。在計算節點中,程序的 oom_score_adj 如下:
| Name | Score |
|---|---|
| sshd等(sshd/dmevented / systemd-udevd) | -1000 |
| K8S 管理程序(kubelet / docker / journalctl) | -999 |
| Guaranteed Pod | -998 |
| 其它程序(核心 init 程序等) | 0 |
| Burstable Pod | min(max(2, 1000 – (1000 * memoryRequestBytes) / machineMemoryCapacityBytes), 999) |
| BestEffort Pod | 1000 |
所以,OOM 的優先順序如下:
BestEffort Pod > Burstable Pod > 其它程序 > Guaranteed Pod > kubelet/docker 等 > sshd 等
在Kubernetes平臺,預設情況下Pod能夠使用節點全部可用資源。如果節點上的Pod負載較大,那麼這些Pod可能會與節點上的系統守護程序和k8s元件爭奪資源並導致節點資源短缺,甚至引發系統OOM,導致某些程序被Linux系統的OOM killer機制殺掉,假如被殺掉的程序是系統程序或K8S元件,會導致比較嚴重的問題。
1.2 解決方案
針對這種問題,主要有兩種解決方案(兩種也可以結合使用):
本篇文章主要介紹如何正確配置資源預留,Pod的驅逐以後介紹。
2. 資源預留簡介
2.1 Node Allocatable簡介
kubelet的啟動配置中有一個Node Allocatable
節點計算資源的分配如下圖所示:
Node Capacity
---------------------------
| kube-reserved |
|-------------------------|
| system-reserved |
|-------------------------|
| eviction-threshold |
|-------------------------|
| |
| allocatable |
| (available for pods) |
| |
| |
---------------------------其中各個部分的含義如下:
- Node Capacity:Node的硬體資源總量
- kube-reserved:給k8s系統程序預留的資源(包括kubelet、container runtime、node problem detector等,但不會給以pod形式起的k8s系統程序預留資源)
- system-reserved:給linux系統守護程序預留的資源
- eviction-threshold:通過--eviction-hard引數為節點預留記憶體,當節點可用記憶體值低於此值時,kubelet會進行pod的驅逐
- allocatable:是真正可供節點上Pod使用的容量,kube-scheduler排程Pod時的參考此值(kubectl describe node可以看到,Node上所有Pods的request量不超過Allocatable)
節點可供Pod使用資源總量的計算公式如下:
allocatable = NodeCapacity - [kube-reserved] - [system-reserved] - [eviction-threshold]從公式可以看出,預設情況下(不設定kube-reserved、system-reserved、eviction-threshold)節點上預設可以讓Pod使用的資源總量等於節點的總容量,會導致Pod與系統程序和k8s元件爭搶資源的情況發生。
2.2 配置引數
kubelet的啟動引數中涉及資源預留的主要有如下幾個:
--cgroups-per-qos--cgroup-driver--cgroup-root--enforce-node-allocatable=pods[,][system-reserved][,][kube-reserved]--kube-reserved=[cpu=100m][,][memory=100Mi][,][ephemeral-storage=1Gi]--kube-reserved-cgroup--system-reserved=[cpu=100mi][,][memory=100Mi][,][ephemeral-storage=1Gi]--system-reserved-cgroup--eviction-hard
2.2.1 引數詳解
--cgroups-per-qos
可選,預設開啟。開啟這個引數後,kubelet會將所有的pod建立在kubelet管理的cgroup層次結構下(這樣才有了限制所有Pod使用資源總量的基礎)。要想啟用Node Allocatable特性,這個引數必須開啟。
--cgroup-driver
可選。指定kubelet使用的cgroup driver。預設為cgroupfs,還可以是systemd,但是這個值需要和docker runtime所使用的cgroup driver保持一致。
--cgroup-root
可選。指定給pod使用的根cgroup,容器執行時會盡量將pod的資源限制在這個根cgroup下面。預設為空,即使用容器執行時作為根cgroup。
--enforce-node-allocatable
指定kubelet為哪些程序做硬限制,可選的值有:pods,kube-reserved,system-reserve。
這個引數開啟並指定pods後kubelet會為所有pod的總cgroup做資源限制(通過cgroup中的kubepods.limit_in_bytes),限制為公式計算出的allocatable的大小。
之所以排程器可以限制節點上所有建立的pod的request量不會超過allocatable,已可以保證不會有超過allocatable的pod跑在該節點上,這裡還要用cgroup再做硬限制的意義可能是:pod可使用的資源是可以大於request的,所以,雖然在排程階段限制了所有request的總量不會超過allocatable的值,但不能保證真正執行起來後所有pod的資源使用量不會超過allocatable;而用cgroup做了硬限制後,當所有pod使用量達到allocatable後,會有pod被OOM killer機制殺掉,以保證實際使用量不會超過allocatable。(後面會有實驗驗證)
假如想為系統程序和k8s程序也做cgroup級別的硬限制,還可以在限制列表中再加system-reserved和kube-reserved,同時還要分別加上--kube-reserved-cgroup和--system-reserved-cgroup以指定分別限制在哪個cgroup裡。
--kube-reserved
指定為k8s系統元件(kubelet、kube-proxy、dockerd等)預留的資源量,如:--kube-reserved=cpu=1,memory=2Gi,ephemeral-storage=1Gi。
這裡需要注意一點的是這裡的kube-reserved只為非pod形式啟動的kube元件預留資源,假如元件要是以static pod形式啟動的,那並不在這個kube-reserved管理並限制的cgroup中,而是在kubepod這個cgroup中。
--kube-reserved-cgroup
這個引數用來指定k8s系統元件所使用的cgroup。注意,這裡指定的cgroup及其子系統需要預先建立好,kubelet並不會為你自動建立好。
--system-reserved
為系統守護程序(sshd, udev等)預留的資源量,如:--system-reserved=cpu=500m,memory=1Gi,ephemeral-storage=1Gi。注意,除了考慮為系統程序預留的量之外,還應該為kernel和使用者登入會話預留一些記憶體。
--system-reserved-cgroup
這個引數用來指定系統守護程序所使用的cgroup。注意,這裡指定的cgroup及其子系統需要預先建立好,kubelet並不會為你自動建立好。
--eviction-hard
設定進行pod驅逐的閾值,這個引數只支援記憶體和磁碟。通過--eviction-hard標誌預留一些記憶體後,當節點上的可用記憶體降至保留值以下時,kubelet 將會對pod進行驅逐。
3 實踐
根據是否對system和kube做cgroup上的硬限制進行劃分,資源預留主要有兩種方式:
- 只對所有pod使用的資源總量做cgroup級別的限制,對system和kube不做cgroup級別限制
- 對pod、system、kube均分別做cgroup級別限制
3.1 方式1—只限制pod資源總量
3.1.1 配置
1.將以下內容新增到kubelet的啟動引數中:
--enforce-node-allocatable=pods \
--cgroup-driver=cgroupfs \
--kube-reserved=cpu=1,memory=1Gi,ephemeral-storage=10Gi \
--system-reserved=cpu=1,memory=2Gi,ephemeral-storage=10Gi \
--eviction-hard=memory.available<500Mi,nodefs.available<10%按以上設定,
節點上可供Pod所request的資源總和allocatable計算如下:
allocatable=capacity-kube-reserved-system-reserved-eviction-hard節點上所有Pod實際使用的資源總和不會超過:
capacity-kube-reserved-system-reserved
2.重啟kubelet
3.1.2 驗證
1.驗證公式計算的allocatable與實際一致
通過kubectl describe node檢視節點實際capacity及allocatable的值
Capacity:
cpu: 8
memory: 32930152Ki(約31.4G)
pods: 110
Allocatable:
cpu: 6
memory: 29272424Ki(約27.9G)
pods: 110根據公式capacity - kube-reserved - system-reserved - eviction-hard,memory的allocatable的值為31.4G - 1G - 2G - 0.5G = 27.9G,與Allocatable的值一致。
2.驗證公式計算的總使用量限制與實際值一致
檢視kubepods控制組中對記憶體的限制值memory.limit_in_bytes(memory.limit_in_bytes值決定了Node上所有的Pod實際能使用的記憶體上限)
$ cat /sys/fs/cgroup/memory/kubepods/memory.limit_in_bytes
30499250176(約28.4G)根據公式capacity - kube-reserved - system-reserved,Node上Pod能實際使用的資源上限值為:31.4G - 1G -2G = 28.4G,與實際一致。
3.2 方式2—同時限制pod、k8s系統元件、linux系統守護程序資源
3.2.1 配置
1.將以下內容新增到kubelet的啟動引數中:
--enforce-node-allocatable=pods,kube-reserved,system-reserved \
--cgroup-driver=cgroupfs \
--kube-reserved=cpu=1,memory=1Gi,ephemeral-storage=10Gi \
--kube-reserved-cgroup=/system.slice/kubelet.service \
--system-reserved cpu=1,memory=2Gi,ephemeral-storage=10Gi \
--system-reserved-cgroup=/system.slice \
--eviction-hard=memory.available<500Mi,nodefs.available<10%至於如何設定cgroup結構,請參考官方建議。
2.為system.slice建立cpuset子系統:
$ sudo mkdir -p /sys/fs/cgroup/cpuset/system.slice備註:
可以看到未建立前system.slice這個cgroup是沒有cpuset子系統的:
find /sys/fs/cgroup -name system.slice
/sys/fs/cgroup/devices/system.slice
/sys/fs/cgroup/memory/system.slice
/sys/fs/cgroup/blkio/system.slice
/sys/fs/cgroup/cpu,cpuacct/system.slice
/sys/fs/cgroup/systemd/system.slice而kubelet(1.11)啟動時會去檢視如下圖所示這些cgroup子系統是否存在,會報找不到相應cgroup的錯誤。
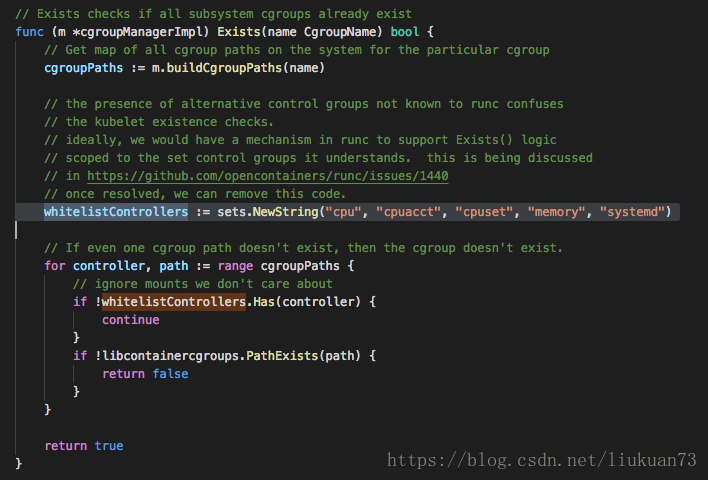
所以這一步需要手工建立相應cpuset子系統。
3.同樣的也需要為kubelet.service建立cpuset子系統:
$ sudo mkdir -p /sys/fs/cgroup/cpuset/system.slice/kubelet.service4.重啟kubelet
3.2.2 驗證
這種情況下pod可分配的資源和實際可使用資源理論上與方法一的計算方式和結果是一樣的,實際實驗中也是一樣的,在這裡不做贅述。重點驗證此情況下是否對k8s系統元件和linux系統守護程序做了cgroup硬限制。
檢視system.slice控制組中對記憶體的限制值memory.limit_in_bytes:
$ cat /sys/fs/cgroup/memory/system.slice/memory.limit_in_bytes
2147483648(2G)檢視kubelet.service控制組中對記憶體的限制值memory.limit_in_bytes:
$ cat /sys/fs/cgroup/memory/system.slice/kubelet.service/memory.limit_in_bytes
1073741824(1G)可以看到,方法2這種預留方式,對k8s元件和系統程序也做了cgroup硬限制,當k8s元件和系統元件資源使用量超過這個限制時,會出現這些程序被殺掉的情況。
更多精彩內容,請訂閱本人微信公眾號:K8SPractice

如果覺得我的文章對您有用,請隨意打賞。您的支援將鼓勵我繼續創作!
支付寶: 微信:


相關推薦
Kubernetes資源管理之--資源預留
1. 概述 1.1 問題 系統資源可分為兩類:可壓縮資源(CPU)和不可壓縮資源(memory、storage)。可壓縮資源比如CPU超配後,在系統滿負荷時會劃分時間片分時執行程序,系統整體會變慢(一般不會導致太大的問題)。但不可壓縮資源如Memory,
簡練軟考知識點整理-項目人力資源管理之馬斯洛需要層次理論
itl 自我 考題 ado pro 人力資源管理 51cto 養老保險 size 馬斯洛需求層次理論,將人類需求像階梯一樣從低到高按層次分為五種: 生理需求(員工宿舍,工作餐,工作服,班車,工資,補貼,獎金); 安全需求(養老保險,醫療保障,長期勞動合同
Impala源碼之資源管理與資源隔離
查詢 圖片 src 阻塞隊列 AI 詳細 利用 生成 獨立 本文由 網易雲 發布。 前言 Impala是一個MPP架構的查詢系統,為了做到平臺化服務,首先需要考慮就是如何做到資源隔離,多個產品之間盡可能小的甚至毫無影響。對於這種需求,最好的隔離方案無疑是物理機器上
unity 資源管理之AssetBundle
上一篇講了unity 資源管理的總體結構連結,這裡主要講unity AssetBundle 相關的記憶體管理內部機制 AssetBundle 由header 和data segment兩部分組成 header包含AssetBundle 一些相關資訊 唯一
Impala原始碼之資源管理與資源隔離
前言 Impala是一個MPP架構的查詢系統,為了做到平臺化服務,首先需要考慮就是如何做到資源隔離,多個產品之間儘可能小的甚至毫無影響。對於這種需求,最好的隔離方案無疑是物理機器上的隔離,A產品使用這幾臺機器,B產品使用那幾臺機器,然後前端根據產品路由到不同叢
Linux系統資源檢視 之 資源資訊
Linux系統資源檢視 之 資源資訊 1. 系統 版本資訊 核心版本 使用 uname 命令: -a : 檢視所有系統資訊 -r : 檢視核心版本資訊 -s : 檢視核心名稱
kubernetes叢集管理之通過jq來擷取屬性
系列目錄 首先要宣告,這裡的jq並不是批前端框架裡的jquery,而是一個處理json的命令列工具. jq工具相比yq,它更加成熟,功能也更加強大,主要表現在以下幾個方面 支援遞迴查詢(我點對我們平時檢視檔案很方便) 支援條件過濾 支援控制語句 支援陣列範圍索引 這個工具在macos和windows都
kubernetes之計算機資源管理
系列目錄 當你編排一個pod的時候,你也可以可選地指定每個容器需要多少CPU和多少記憶體(RAM).當容器請求特定的資源時,排程器可以更好地根據資源請求來確定把pod排程到哪個節點上.當容器請求限制特定資源時,特定節點會以指定方式對容器的資源進行限制. 對於資源請求和資源限制的區別,可以檢視QoS 資源型
深入解析 kubernetes 資源管理,容器雲牛人有話說
系統 關系 充足 sig 配置信息 解釋 進行 解決 由於 資源,無論是計算資源、存儲資源、網絡資源,對於容器管理調度平臺來說都是需要關註的一個核心問題。 ? 如何對資源進行抽象、定義?? 如何確認實際可以使用的資源量?? 如何為容器分配它所申請的資源? 這些問題都是平
Kubernetes學習之路(十一)之資源清單定義
map latest dem kubectl 服務發現 bject 均衡 ima limit 一、Kubernetes常用資源 以下列舉的內容都是 kubernetes 中的 Object,這些對象都可以在 yaml 文件中作為一種 API 類型來配置。 類別 名稱
Sql Server2008 中的活動監視器、物件資源管理器詳細資訊、搜尋、查詢編輯器之IntelliSense (轉)
Management Studio首次出現在MSSQL2005中,到MSSQL2008中已經成為了一個更成功的產品。其中在SSMS2008中最重要的特性如下: 1.活動監視器 2.物件資源管理器詳細資訊 3.搜尋 4.查詢編輯器之IntelliSense &nb
Android原始碼解析之應用程式資源管理器(Asset Manager)的建立過程分析
轉載自:https://blog.csdn.net/luoshengyang/article/details/8791064 我們分析了Android應用程式資源的編譯和打包過程,最終得到的應用程式資源就與應用程式程式碼一起打包在一個APK檔案中。Android應用程式在執行的過程中,是通過一個
【kubernetes/k8s原始碼分析】kubelet原始碼分析之資源上報
0. 資料流 路徑: pkg/kubelet/kubelet.go Run函式() -> syncNodeStatus () -> registerWithAPIServer() ->
資源管理模式之Unity3D的Prefab與電子表格
最近在專案中進行資源優化. 我們的專案一直以來都是以傳統的電子表格配置為中心的資源驅動載入方法, 拿角色攜帶的特效要播放出來這個case來具體點說就是: 1. 技能部分的特效可以遍歷動作表播放的所有特效id, 提前預載 2. buff類特效是動態確定的,無法分析. 需要通過角色表新增資源id在載入角色
kubernetes學習筆記之十二:資源指標API及自定義指標API
第一章、前言 以前是用heapster來收集資源指標才能看,現在heapster要廢棄了從1.8以後引入了資源api指標監視 資源指標:metrics-server(核心指標) 自定義指標:prometheus,k8s-prometheus-adapter(將Prometheus採集的資料轉換為指
如何擴充套件Kubernetes管理的資源物件?
Kubernetes是一套容器化解決方案,也是一套資源管理的架構和標準;本次分享是基於我在餓了麼現階段容器化經驗和理念的總結,探討深化Kubernetes在企業內部的應用的方法,介紹如何利用開源的API Server框架在企業內部打造和擴充套件Kubernetes管理的資源物件。 Kubernet
kubernetes資源管理
週末和友人聊天,友人問及“搜尋是計算密集型”,如果使用docker技術,如何資源管理? 本文來解釋一下如何使用kubernetes來進行資源分配(主要包括cpu和mem) 可能很多人還不瞭解資源設定的意義在哪,為什麼要進行資源設定?
kubernetes federation 工作機制之資源物件同步
01 前言希望通過本文最簡單的方式向熟悉k8s的人說明白其上的federation是幹什麼的,如何工作的。關於federation,比較官方的說法是:叢集聯邦可以讓租戶/企業根據需要擴充套件或伸縮所需要的叢集;可以讓租戶/企業在跨地區甚至跨地域的多個叢集上部署、排程、監測管理應用。通過叢集聯邦,租戶/企業可以
SAP-HR技術系列之二:人力資源管理系統專案實施經驗談
轉載:http://wenku.baidu.com/view/c7d2ebda7f1922791688e8c8.html 首先需要說明的是HRMS(e-HR)系統實施專注於人力資源管理系統的設計、實現和應用推廣,而不是進行人力資源管理諮詢,如薪酬體系、考核方案、指標及兌
unity3D學習筆記之九 資源管理
遊戲中通常有大量資源,如網格、材質、紋理、動畫、著色器程式和音樂等,遊戲引擎作為做遊戲的工具,自然要提供良好的資源管理,讓遊戲開發者用最簡單的方式使用資源。遊戲引擎的資源管理包括兩大部分:離線資源管理和執行時資源管理。本文僅對前者進行簡要介紹,並結合Unity3D和OGRE進行分析。 資源創作與匯出 遊