
JAVA工程師面試技術點彙總(持續更新中)
一:mysql
1、mysql Nested-Loop演算法,Block-Nested-Loop演算法,join優化
答:Nested-Loop:選取(mysql自動優化選擇)一個表作為驅動表,迴圈驅動表結果集,查詢下一個表的資料,然後合併結果集。如果是多表join,則將前一次合併的結果作為迴圈資料,查詢下一個表。
Block-Nested-Loop(預設開啟):在NL演算法的基礎上,將外層迴圈的結果快取起來,內層迴圈一次比較多條資料,減少總迴圈次數。比如,外層查詢有100條結果,快取10條,每次內層迴圈比較10條資料,則只需要迴圈10次。
優化:
- 使用小結果集作為驅動表,減少總迴圈次數(自動優化)
- 優先優化內層查詢,減少每一次迴圈的時間
- 關聯查詢條件建立索引
- 設定適當的join_buffer_size,當join_buffer_size大於外層結果集時,再增大join_buffer_size不會變得更快
2、mysql索引原理
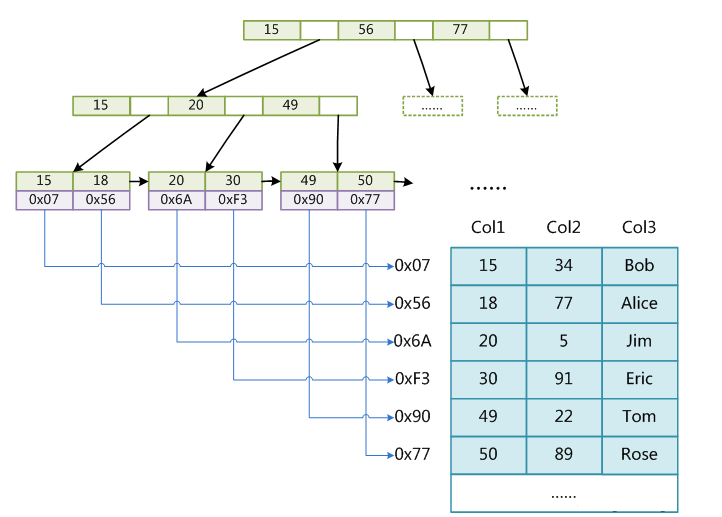
答:mysql使用B+Tree(平衡多路查詢樹)作為索引的資料結構,而innoDB和MyIsAm對索引的實現方式略有不同。使用B+Tree而不使用平衡二叉樹、紅黑樹等結構的原因和計算機物理結構有關。索引本身需要儲存,而索引一般比較大,因此索引往往存在磁碟中。而磁碟IO效率非常低,所以判斷索引結構好壞的一個重要指標就是磁碟IO次數。計算機為提高磁碟IO效率,在讀取資料時會進行預讀,預讀的大小為頁的整數倍。資料庫系統將B+Tree結點的大小剛好設定為一頁的大小,因此一次IO就能完全載入一個結點。因為B+Tree的一個結點中會儲存多個關鍵字,所以B+Tree的高度相比其他幾種樹會低很多,IO次數也會少很多。 MyIsAm索引:索引檔案與資料檔案是分離的。索引的葉子結點儲存資料行的地址。因為相鄰的葉子節點分配的實體地址並不一定相鄰,所以這種索引是非聚簇索引。
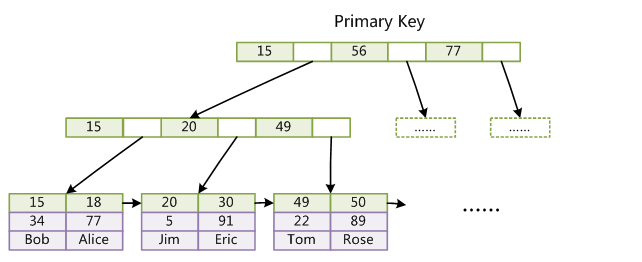
InnoDB的主鍵索引:資料檔案就是索引檔案。索引的葉子結點儲存完整的資料記錄。邏輯相鄰的資料行在物理上的儲存也是相鄰的,屬於聚簇索引。若沒有定義主鍵,則mysql選取第一個唯一非空的索引作為聚簇索引。若也沒有唯一非空的索引,則會建立一個隱藏的聚簇索引。建表時最好使用無意義的自增列作為主鍵,每次插入資料只需要按順序往後排即可。如果主鍵不是自增的,插入新結點時可能導致結點分裂(一個結點儲存的資料記錄超過一定大小就會分裂),進而導致後序其他的結點分裂,在資料量大的時候,效率非常低下。
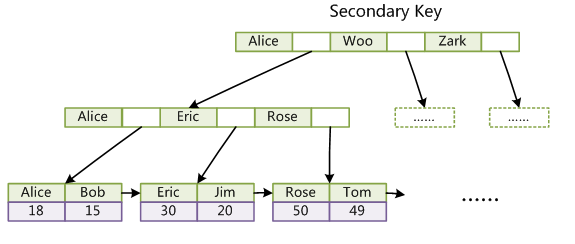
InnoDB的普通索引:葉子結點儲存主鍵值,普通索引的順序與主鍵索引不一定一樣,所以是非聚簇索引。
3、索引的選擇性
答:索引的選擇性=不重複的值得個數/總記錄數,取值範圍為(0,1]。索引的選擇性越小,使用索引的效果越不明顯(越接近全表掃描)。極端情況下,假設只有一種不重複的值,使用索引(需要掃描整個B+Tree或hash值查出的記錄為所有記錄)和全表掃描完全一樣。4、hash索引和B+Tree索引的區別
答:
- hash索引只能用於=、in和!=的查詢,不能用於範圍查詢,不能用於排序。因為hash索引通過查詢hash值一樣的資料來進行索引,而hash之前的值大小與hash值大小不一定存在對應關係。
- 對於組合索引,不能利用前面的一個或多個索引查詢
- hash存在衝突的情況,因此查到一個hash值之後,還需要在多個數據記錄之間選擇
- 除上述情況外,hash索引效率遠高於B+Tree
5、mvcc(多版本併發控制)機制
答:mvcc只有在Read Commited和Repeatable Read隔離級別下有效。在Read Uncommited下,每次讀都是當前讀(讀最新行,而不是符合系統版本號的行),在Sirializable級別下,所有讀都加鎖,因此這兩種級別不適用mvcc。在InnoDB的 mvcc是通過在每行記錄後面儲存兩個隱藏的列來實現的。這兩個列一個儲存了行的建立時系統版本號,一個儲存了行的刪除時系統版本號。每開始一個新事務,系統版本號都會遞增。事務開始時的系統版本號就是事務版本號。下面是crud的mvcc實現(注:在事務a、b併發執行的情況下,假設事務a讀取行,事務b插入(更新、刪除)行。若事務b先執行,則會鎖行,事務a會等b執行完之後讀取最新結果,這種情況與mvcc機制無關。若事務a先執行,b是插入操作時,b的版本號大於a,a不能查到新增的行;b是更新操作時,新增的行版本號大於a,讀到的仍是原始行;b是刪除操作時,刪除版本號大於a的版本號,仍能查到b刪除的這行。以上情況無論b是否已經提交都成立,這樣就解決了快照讀下的髒讀、不可重複讀以及幻讀):
- select:只有符合以下兩個條件的記錄才會作為返回結果
- 行的建立版本號小於或等於事務版本號。這可以確保事務讀取的行,要麼是事務開始前已經存在的,要麼是事務自身插入或者修改過得。。
- 行的刪除版本要麼未定義,要麼大於當前事務版本號。這可以確保事務讀到的行,在事務開始之前未被刪除。
- insert:新插入的每一行儲存當前系統版本號作為行版本號。
- delete:刪除的每一行儲存當前系統版本號作為行刪除版本號。
- update:插入一條新紀錄,儲存當前系統版本號作為行版本號,同時儲存當前系統版本號作為原來的行的刪除版本號。
6、如何解決當前讀引起的幻讀
答:mvcc無法解決因當前讀(增、刪、改均先有一次當前讀)引起的幻讀。示例:1、3之間雖然被事務b插入了一條資料,但這兩次查詢結果是一樣的,這符合mvcc的規則,此時沒有出現幻讀。執行4的時候,由於update是當前讀,會讀到事務b提交的最新資料,這次更新操作會把新行的版本號和原始行的刪除版本號設定為事務a的版本號。因此,執行查詢5的時候,不能查到b新增的行(刪除版本號相等),卻查出了更新之後的新行(行版本號相等)。同一個事務裡面的三次查詢,第三次查到的結果和第一第二次查詢結果不同,也可以算是幻讀。 解決方法:為查詢加共享鎖LOCK IN SHARE MODE或排它鎖FOR UPDATE,如select * from table_name lock in share mode,若欄位a沒有唯一索引,還需要使用RR隔離級別(在InnoDB中,由於mvcc的存在,RR與RC的唯一區別就是RR使用間隙鎖解決了當前讀的幻讀問題)。
- 事務a:select * from table_name
- 事務b:insert into table_name (a) values (1),commit b
- 事務a:select * from table_name
- 事務a:update table_name set a=1 where a=1
- 事務a:select * from table_name,commit a
7、InnoDB的鎖
答:根據鎖的獲取許可權,可以分為共享鎖s,排它鎖x,以及意向共享鎖is,意向排它鎖ix。根據鎖的範圍,可以分為Record Lock:鎖定一行記錄的索引;Gap Lock:鎖定所在記錄行的索引兩側的不存在的索引;Next-Key Lock:上述兩種加起來。
- 共享鎖和排它鎖鎖定行,意向鎖鎖定表。加鎖順序為先加意向鎖,獲得意向鎖之後再加其他鎖。這四種鎖的相容關係如下:
由圖可知,一個事務獲取了意向鎖,其他事務也可以獲取該表的意向鎖。一個事務獲取了共享鎖之後,其他事務只能獲取意向共享鎖和共享鎖。一個事務獲取排它鎖之後,其他事務不能獲取任何型別的鎖。
- 鎖是加在索引上的,不同型別的索引加的鎖型別不同,示例語句delete from table_name where a = 8;
- a是主鍵索引,在這條記錄的索引上加行鎖
- a是非主鍵唯一索引,這條記錄的唯一索引和主鍵索引均加行鎖
- a是非唯一索引,在RC隔離級別下,所有滿足條件的記錄均加行鎖。在RR隔離級別下,除行鎖外,還會加間隙鎖(滿足條件的值兩側的間隙),這兩個鎖合起來即Next-Key Lock。如資料庫有記錄5,8,9,則鎖的範圍是(5,9),因為如果再插入一條8,則新結點一定插入在(5,9)這個間隙的結點上。正是間隙鎖解決了當前讀的幻讀問題。唯一索引不需要間隙鎖是因為唯一索引下的同一個值只會插入一次。
- a無索引,在RC隔離級別下,表的所有行加行鎖。在RR隔離級別下,所有行加行鎖和間隙鎖。
8、如何避免死鎖
答:死鎖產生的原因是不同的事務獲取鎖的順序相反(不一定非要多條sql語句才會形成死鎖,如兩個事務分別通過兩個非主鍵索引更新資料,這兩個索引對應的主鍵順序剛好相反時就形成了死鎖)。常見的避免死鎖的方法有:
- 儘量以相同的順序訪問表,若某兩個事務因使用不同的非主鍵索引引起死鎖,可以嘗試拆分sql語句,通過非主鍵索引查出主鍵,再用主鍵更新記錄。
- 嘗試升級鎖定的顆粒度,通過表鎖減少死鎖的概率

二:java
1、記憶體模型
答:執行緒共享部分:方法區(在Hotspot中實現為永久代)、堆。執行緒獨佔部分:虛擬機器棧、本地方法棧、程式計數器。在jdk1.8中,元資料區取代了永久代,類資訊存放在本地記憶體中,常量和靜態變數放在堆中。
2、CopyOnWriteArrayList和Vector或通過Collections.synchronizedList()獲取到的SynchronizedList的區別
答:SynchronizedList和Vector屬於同步容器,所有方法均加鎖,併發效能很差。而CopyOnWriteArrayList只對寫操作加鎖,修改操作並不直接修改原始陣列的內容,而是建立一個新陣列並把原陣列的引用指向新陣列。由於該陣列引用是volatile的並且更新和新增操作直接替換引用,因此不需要對讀加鎖。CopyOnWriteArrayList體現了讀寫分離的思想,對於併發讀取的效能遠高於SynchronizedList。CopyOnWriteArrayList沒加讀鎖,因此獲取到的資料不能保證實時一致,比如正在執行add操作,但還沒有執行到陣列賦值的那一行,則讀到的還是add之前的資料。另外,CopyOnWriteArrayList佔用記憶體較多,只有在遍歷、獲取操作遠多於寫操作是才考慮使用。SynchronizedList無法在遍歷時修改(可以使用iterator的方法修改,但需要額外的同步處理),而CopyOnWriteArrayList可以(但不能通過iterator方法修改,其iterator沒有提供相應的方法),但遍歷時不會獲取到修改的部分(遍歷的是那一刻的陣列副本)。3、ConcurrentHashMap和HashTable或通過Collections.synchronizedMap()獲取到的SynchronizedMap的區別
答:HashTable和SynchronizedMap屬於同步容器,所有方法均加鎖。ConcurrentHashMap不對整個方法加鎖。get操作直接獲取記憶體最新值,put操作若table的當前位置為空,則使用CAS插入新結點,若不為空,則對當前位置加鎖後插入。ConcurrentHashMap相對同步容器大大增加了併發度。由於get、size等方法是無鎖的,因此不能實時的獲取(如get一個key的同時put,get獲取不到但put操作完成後這個key是存在的),size計算的也不是準確值。同步容器只能在使用iterator遍歷時,使用iterator的remove方法做刪除操作,ConcurrentHashMap可以在遍歷的同時呼叫put或remove。4、HashMap的容量為什麼是2的k次冪
答:HashMap的結構是一個連結串列(或紅黑樹)陣列,不同的Node根據hash值雜湊在table陣列中,hash值相同的Node組成一個連結串列(或紅黑樹)。table.length>64並且連結串列長度>8時,會將連結串列結構轉化成紅黑樹,以此來提升hash值相同時的查詢效率。當table.length>threshold(容量*負載因子),或者table.length<=64並且連結串列長度>8時,會發生擴容,每次擴容之後的容量都是2的k次冪(左移一位)。Node的hash值對table.length取模就可以得到Node在table中的下標,但取模運算%是非常耗時的。我們把table.length記為n,當n=2^k(2的k次冪)時滿足下列等式:hash%n=hash&(2^k-1)=hash&(n-1),因此將table.length設定為2的k次冪即可把低效的取模運算轉化成高效的位運算。
5、HashMap resize原理
答:
- 該連結串列只有一個連結串列結點,直接rehash
- 該結點是樹結點,略。。
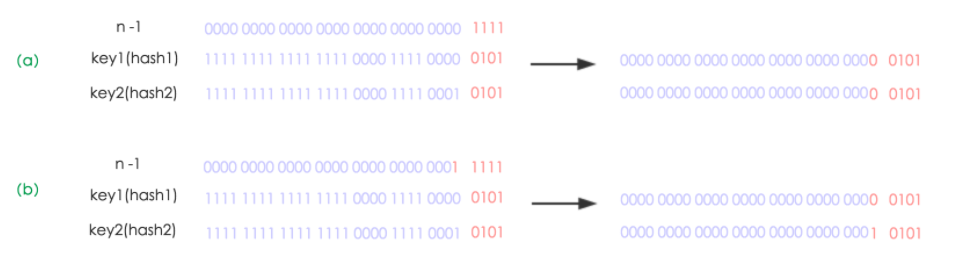
- 該連結串列有多個結點:由於是根據取模操作計算位置,而不同的hash值取模可能相同,因此不同的hash值也可能存在同一個連結串列上。而擴容之後hash值對newCap取模與原來不一定相同,因此不能簡單的移動整個連結串列。HashMap根據hash&(n-1)計算key在table中的位置,其中n=2^k,擴容後n=2^(k+1),因此n-1與擴容前相比在高位多了一個1.若hash在對應的位置為0,則&操作之後與擴容前相同;若hash在對應的位置為1,則&操作之後相當於增加了100....(等於oldCap的值)。即原連結串列上的結點在擴容之後的位置只有兩種可能,要麼還在原位置,要麼在原位置+oldCap的位置。遍歷原連結串列,根據hash對應oldCap的最高位是0還是1分成兩個連結串列。下圖a為擴容前兩個hash值對n-1做&操作的過程,圖b為擴容後的過程。
6、JAVA的CAS(compare and swap)
答:cpu在計算的時候,並不總是從記憶體讀取資料,它的資料讀取順序優先順序 是:暫存器-快取記憶體-記憶體。多個執行緒併發執行時,快取裡面的值可能和記憶體值不一致,因此導致計算結果錯誤。以下幾種方式可以確保執行緒安全
- synchronized是悲觀鎖,在鎖定範圍內無論未來是否會發生衝突都同時只能有一個執行緒可以執行。獲取鎖的時候把讀取記憶體值到快取,釋放鎖的時候把快取寫入記憶體。
- 使用volatile關鍵字,每次更新操作都寫入記憶體,因此可以保證更新操作對其他執行緒可見,但不能保證複合操作的原子性,如i++這種讀-改-寫操作。如果修飾的是物件或者陣列,只能保證引用的可見性,不能保證物件的屬性或陣列元素可見性。
- 使用CAS。CAS操作:只有當記憶體值V和預期值A相同時,才將記憶體值V修改成新值B,否則不修改。下圖是Unsafe類中的一個方法,這個方法使用CAS實現了i+=n的操作。這種使用死迴圈進行cas操作代替互斥鎖(如synchronize,需要進行掛起操作)的方式也稱為cas自旋鎖。這個方法相當於樂觀鎖,並不在一開始就加鎖,而是發生衝突時等待直到衝突解決。CAS通常與volatile或getIntVolatile()一起使用,先獲取記憶體值,然後在CAS中判斷剛剛獲取到的值是否過期,沒過期則修改。使用CAS演算法可以保證單個變數的複合操作也是原子的,但不能保證多個變數的操作原子性,多個變數的原子性只能使用synchronize。JAVA中可以通過Unsafe類執行CAS操作(Unsafe封裝了很多直接操作記憶體的方法,類似C語言),但並不建議直接使用Unsafe類。jdk併發相關的類中大量使用了Unsafe類。
7、執行緒池原理
答:執行緒池ExecutorService可以通過Executors的工廠方法建立,返回一個ThreadPoolExecutor物件。ThreadPoolExecutor中儲存了兩個資料結構,即BlockingQueue和HashSet。BlockingQueue中儲存的是通過submit()或execute()方法生產的任務,HashSet中儲存的是消費者Worker。每個Worker都會新建一個執行緒,並無限迴圈呼叫BlockingQueue的take()方法獲取任務執行。當Worker執行任務被中斷時跳出無限迴圈,並將該worker從HashSet中清除。呼叫shutdown()方法會把執行緒池狀態設定為SHUTDOWN,並中斷空閒的Worker(worker執行任務時加鎖,shutdown()時會嘗試獲取鎖,獲取不到鎖則不中斷)。shutdownNow()方法把執行緒池狀態設定為STOP,並中斷所有Worker。只有RUNNING狀態才能提交任務,因此呼叫shutdown()和shutdownNow()之後不能繼續新增任務。而中斷worker是通過呼叫worker中儲存的Thread的interrupt()方法做到的,如果任務中沒有因wait、join、sleep、可中斷的I/O操作(NIO)等而阻塞,並且沒有人為地判斷執行緒中斷標誌,則執行緒仍會繼續執行,因此執行shutdownNow()之後程式並不一定會立即停止執行。由於執行緒池建立的執行緒是使用者執行緒並在執行緒內部無限迴圈,不會主動結束,因此如果不呼叫shutdown()或shutdownNow()程式將永遠不會停止。
- 固定大小的執行緒池(如newFixedThreadPool())中的BlockingQueue是LinkedBlockingQueue,提交任務時,若Worker沒有達到最大數量,則新建一個Worker並儲存到HashSet中,同時在該Worker物件中執行本次任務,否則將任務放入BlockQueue,BlockQueue的大小沒有限制。
- 計劃任務執行緒池newScheduledThreadPool()與固定大小執行緒池類似,只是BlockingQueue的型別為DelayedWorkQueue。
- cache型別的執行緒池(如newCachedThreadPool())中的BlockingQueue是SynchronousQueue,提交新任務時首先判斷能否將任務放入阻塞佇列中(即有空閒的Worker在等待任務。對於SynchronousQueue,只有當存在消費者呼叫take()方法等待生產者時,offer()或add()方法才返回true;反之亦然,只有當生產者呼叫put()方法等待消費者時,poll()方法才不返回null。生產者和消費者一一匹配執行,佇列中可以儲存的任務數量為0),放入佇列失敗則新建Worker並儲存在HashSet中,Worker數量沒有限制。
8、線上程池中使用ThreadLocal
答:ThreadLocal為每一個執行緒儲存一個變數副本,線上程池中由於執行緒會重複利用,並不是一個執行緒對應一個任務,而是一個執行緒對應多個任務,因此在任務中使用完ThreadLocal之後必須將值清除掉以避免多個任務獲取到的值是相同的。


三:web
1、get和post的區別
答:
- get只讀,gost非只讀
- get冪等(多次請求和一次請求效果一樣),post非冪等
- get可快取,post不可快取
- get請求會出現在url中
- get只能傳送普通字元,post可以傳送二進位制
- get請求長度有限制(2k),post無限制
2、http1.0,1.1,2.0區別
答:
- 1.0預設不是長連線,如果需要長連線需手動設定keep-alive,1.1預設長連線。
- 1.1比1.0多了host欄位
- 1.1可以只發送頭資訊,不帶body(伺服器返回100或者401)
- 2.0使用多路複用技術,一個連結可以同時處理多個請求。
- 2.0支援header資料壓縮
- 2.0支援伺服器推送:一個請求可以有多個響應,可以提前快取其他頁面需要的內容
3、tcp三次握手四次揮手
四:演算法&資料結構
1、根據二叉樹的兩種(前中,後中)遍歷結果畫出二叉樹
答:先序遍歷為根左右,中序遍歷為左根右,後序遍歷為左右根。先序遍歷的第一個值就是根結點,後序遍歷最後一個值是根結點,在中序遍歷中找到根結點,左邊的是左子樹,右邊的是右子樹。分別在左右子樹中列出前中(後中)序列,重複上述方法直到所有結點都找到位置。如先序4,2,1,0,3,5,9,7,6,8,中序0,1,2,3,4,5,6,7,8,9。根據先序確定根結點是4,根據中序確定左子樹為0123,右子樹為56789。左子樹0123(中序)的先序為2103,確定2為根結點,左子樹為01,右子樹為3。一直迴圈下去即可畫出完整的樹。再如後序0,1,3,2,6,8,7,9,5,4,根據後序知道根為4,根據中序知道左子樹為0123,左子樹的後序為0132,則左子樹的根為2,依次迴圈即可。
2、根據二叉樹給出先(中、後)序遍歷結果
答:
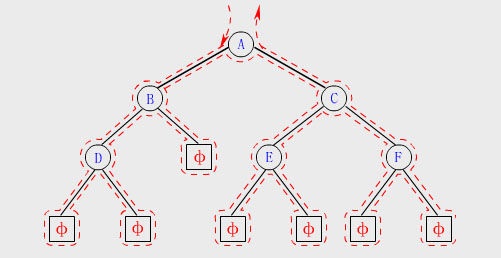
根據箭頭流向,第一次經過的結點序列就是先序結果,第二次經過的結點序列是中序結果,第三次經過的結點序列是後序結果
3、二叉排序樹的刪除
答:二叉排序樹滿足左結點比根小,右結點比根大,因此整個樹最左邊的結點是最小的,最右邊的結點是最大的。刪除結點分三種情況:
- 該結點p是葉子結點:刪除葉子結點不影響樹的性質,直接刪掉即可。
- 該結點p只有一個子節點c,用c替換該結點即可。如:p是父結點f的左孩子,則把c設定為f的左孩子;p是f的右孩子,則把c設定為f的右孩子。
- 該結點有兩個子結點。用左結點cl替換該結點,然後將右結點cr設定為cl的最右邊子樹的右結點cmax(cr大於cl中最大的子結點cmax)。
4、一致性hash演算法
5、連結串列轉紅黑樹
6、B+Tree與B-Tree
答:
- n階(叉)B+Tree包含n個關鍵字,而B-Tree是n-1個
- b-的關鍵字在結點中只出現一次,而b+可能出現多次。b+的非葉子結點只是葉子結點的索引,葉子結點增加一個臉指標,中包含所有的關鍵字
- b-可以在非葉子結點命中,b+只能在葉子結點命中

五:linux
1、io模型
相關推薦
JAVA工程師面試技術點彙總(持續更新中)
一:mysql 1、mysql Nested-Loop演算法,Block-Nested-Loop演算法,join優化 答:Nested-Loop:選取(mysql自動優化選擇)一個表作為驅動表,迴圈驅動表結果集,查詢下一個表的資料,然後合併結果集。如果是多表join,則
web前端工程師具備經驗和知識點(持續更新中)
web前端工程師必備 1、瞭解 DNS 解析,充分利用 CDN,使用多個域名來完成資源的請求以縮短載入時間; 2、設定 HTTP Headers(Expires, Cache-Control, If-Modified-Since); 3、遵循 Steve Souders 給出的全部規
UVM_USERS_GUIDE學習彙總(持續更新中)
1.overview 本章節通過典型的testbench架構和引入相關術語提供一個uvm的基本概述。 1.1 the typical uvm testbench architecture 1.1.1 uvm testbench UVM Testbench 例化了Des
2018年阿里巴巴重要開源專案彙總(持續更新中)
摘要: 雲棲社群特在2018年年末,將阿里巴巴的一些重要的開源專案進行整理,希望對大家有所幫助。 開源展示了人類共同協作,成果分享的魅力,每一次技術發展都是站在巨人的肩膀上,技術諸多創新和發展往往就是基於開源發展起來的,沒有任何一家網路公司可以不使用開源技術,僅靠自身技術而發展起來。阿里巴巴各個團
Android 系統中,那些能大幅提高工作效率的 API 彙總(持續更新中...)
前言 “條條大路通羅馬。”工作中,實現某個需求的方式往往不是唯一的,這些不同實現方式不僅表現在程式碼質量上,還影響著我們的工作效率。就像,在 Android 系統中,總有那麼一些鮮為人知的 API 能夠減少我們很多零碎的工作量。於是,就想憑著一些經
Hadoop技術資料彙總(不斷更新中)
這些資料都是我在工作中學習、解決問題的資料彙總,我不能保證這裡羅列的所有資料對看到的人有用,但大部分都經過我的實際驗證。在不斷學
Java:面試技術點彙總
ssm SSM(Spring+SpringMVC+MyBatis)框架集由Spring、MyBatis兩個開源框架整合而成(SpringMVC是Spring中的部分內容)。常作為資料來源較簡單的web專案的框架。 頁面傳送請求給控制器,控制器呼叫業務層處理邏輯,邏輯層向持久層傳送請
java基礎知識匯總(持續更新中....)
方法區 管理 執行 中間 inter print method arch end 1.java四大特性:抽象、繼承、封裝,多態 構造函數: http://blog.csdn.net/qq_33642117/article/details/51909346
Java常見異常總結(持續更新中......)
1.類未找到 Exception in thread "main" java.lang.NoClassDefFoundError:類名 Caused by: java.lang.ClassNotFoundException:類名 這種異常未未發現類異常,是由於編譯的時候未找到該類而報異常
java面試題(持續更新中)
1、寫出內部類的特點 Java中的內部類共分為四種: 靜態內部類:只可以訪問外部類的靜態成員和靜態方法,包括了私有的靜態成員和方法生成靜態內部類物件的方式為: OuterClass.InnerClass inner = new OuterClass.InnerClass(); 成
Java知識小結(持續更新中)
1、在Java中資料型別主要分為: 基本資料型別 引用資料型別 2、++放在後面先賦值再自增 ++放在前面先自增再賦值 3、方法名:一般採用駝峰命名法 4、變數: 如果變數的資料型別是類型別,則可以把該變數讀成是該類型別的一個物件或引用(沒有例項化之前) 5、呼叫方法的三種方
java+selenium的使用方法歸納總結(持續更新中)
selenium的使用 第一步:獲取selenium的jar包及驅動瀏覽器的驅動 在獲取selenium的jar包和瀏覽器的驅動包時,要對照她們的版本號 通過下面可檢視谷歌的版本對應 java+selenium的入門 案例 selenium包 谷歌驅動包 火狐驅動包 IE驅動包
React Native常見問題彙總(持續更新ing)
1.建立新專案,react-native init AwesomeProject命令長時間無響應,或報錯shasum check failed react-native命令列從npm官方源拖程式碼時會遇上麻煩。請將npm倉庫源替換為國內映象: npm config set registr
Redis的java客戶端Jedis Client介紹(持續翻譯中)
1. 概覽 This article is an introduction to Jedis, a client library in Java for Redis – the popular in-memory data structure store that can persis
總結Spring框架擴充套件點(二)bean生命週期中的擴充套件點(持續更新中...)
面向業務開發的時候,程式設計師需要明白業務的邏輯,並設計程式碼結構。而在進行中介軟體開發的時候,則需要明白框架的邏輯,進行開發。 所以要開發提供給spring的中介軟體,需要知道spring中有哪些擴充套件點,好在對應的地方插入我們的功能。 1. Spring容器初始化b
2018年Android面試題彙總一(持續更新中)
隨著Android從業人員的增多,當下Android面試不再侷限幾年前ListView如何使用,Android生命週期等入門級知識,而是逐漸形成一套體系,從多角度考察應聘者。雖然很多知識在平時工作中用不到,但是以此提升Android應聘門檻,也是眾多公司樂於採用
【2019年大資料福利推薦】MaxCompute教程、案例視訊合集彙總(持續更新20190111)
大資料計算服務(MaxCompute,原名ODPS,產品地址:https://www.aliyun.com/product/odps)是一種快速、完全託管的TB/PB級資料倉庫解決方案。MaxCompute向用戶提供了完善的資料匯入方案以及多種經典的分散式計算模型,能夠更快速的解決使用者海量資料計算問題,有
【機器學習】演算法面試知識點整理(持續更新中~)
1、監督學習(SupervisedLearning):有類別標籤的學習,基於訓練樣本的輸入、輸出訓練得到最優模型,再使用該模型預測新輸入的輸出;代表演算法:決策樹、樸素貝葉斯、邏輯迴歸、KNN、SVM、
2018年Android面試題彙總四(持續更新中)
面試系列,推薦先讀我的心得:十二、ThreadLocal12.1、四大方法:set、get、remove和initialValue。 1、initialValue在第一次呼叫get或set時執行,只執行一次,初始化內部類Values中Oject陣列。 2、JDK5.0
劍指Offer——面試小提示(持續更新中)
(1)應聘者在電話面試的時候應儘可能用形象的語言把細節說清楚。 (2)如果在英語面試時沒有聽清或沒有聽懂面試官的問題,應聘者要敢於說Pardon。 (3)在共享桌面遠端面試中,面試官最關心的是應聘者的程式設計習慣與除錯能力。 (4)在介紹專案經驗時(包括在簡歷上介紹和麵試時