
基於R統計分析——樣本與分佈
1 資料抽樣
(1) 簡單隨機抽樣
sample(x,size,replace=FALSE,prob=NULL)其中,x表示待抽取物件,一般情況下以向量形式表示;size為非負整數,表示想要抽取樣本的個數;replace表示是否為可放回抽樣,預設不放回;prob用於設定各個抽樣樣本的抽樣概率,預設等概率抽樣。
例子:
library(MASS)
data(Insurance)
sub1=sample(nrow(Insurance),10,replace=T)
sub2=sample(nrow(Insurance),10)
sub3=sample(nrow(Insurance 備註:sample為自帶函式
(2) 分層抽樣
strata(data, stratanames=NULL, size, method=c(“srswor”,”srswr”,”poisson”,”systematic”), description=FALSE)其中,data為待抽樣資料集;stratanames中放置進行分層所依據的變數名稱;size用於設定各層中將要抽出的觀測樣本數,其順序應該與資料集中變數各水平出現順序一致,且在使用該函式前,應當首先對資料集按照該變數進行升序排列;method引數用於選擇抽樣方法,分別對應於無放回、有放回、泊松、系統抽樣,預設無放回;pik用於設定各層中各樣本的抽樣概率;description引數用於選擇是否輸出含有各層基本資訊的結果。
sub4=strata(Insurance,stratanames="District",size=c(1,2,3,4),method="srswor")
#按照街區進行分層,且1~4個街區中無放回抽取1-4個樣本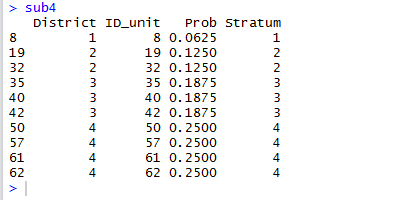
(3) 整群抽樣
cluster(data, clustername, size, method=c(“srswor”,”srswr”,”poisson”,”systematic”), description=FALSE)與分層抽樣稍微不同的是,clustername指用來劃分群的變數的名稱,而size不再為分層抽樣中的一個向量,這裡僅為一個正整數,表示需要抽取的群數。
sub5=cluster(Insurance,clustername="District",size=2,method="srswor")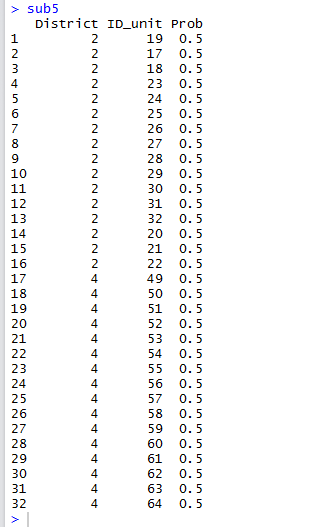
備註:strata和cluster函式需要載入sampling包
2 概率分佈
R中提供了18個分佈函式
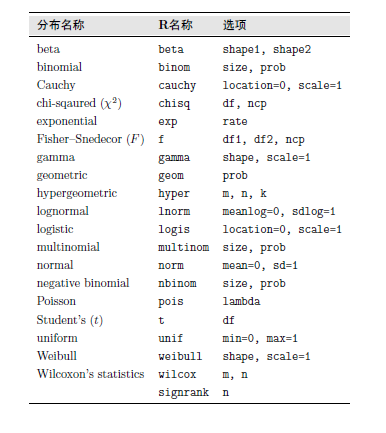
對於所給的分佈名稱,加字首“d”(代表密度函式, density)就得到R的密度函式(對於離散分佈, 指分佈律); 加字首“p”(代表分佈函式或概率, CDF)就得到R的分佈函式; 加字首“q”(代表分位函式, quantile)就得到R的分位數函式; 加字首“r”(代表隨機模擬, random)就得到R的隨機數發生函式.
相關推薦
基於R統計分析——樣本與分佈
1 資料抽樣 (1) 簡單隨機抽樣 sample(x,size,replace=FALSE,prob=NULL) 其中,x表示待抽取物件,一般情況下以向量形式表示;size為非負整數,表示想要抽取樣本的個數;replace表示是否為可放回抽樣,預設不放
統計分析與R軟件-chapter2-2
元素 5.6 2.2.3 zhang labs date() 賦值 line max 2.2 數字、字符與向量 2.2.1 向量 1.向量的賦值 x<-c(10.4,5.6,3.1,6.4,21.7) 2.向量的運算 x<-c(-1,0,2);y&l
【R統計】基於相似系數的聚類分析
ant 建模 sub plc str 選擇 pre light 均值 題目: 對48名應聘者數據的自變量作聚類分析,選擇變量的相關系數作為變量間的相似系數(cij),距離定義為dij=1-cij。分別用最長距離法、均值法、重心法和Ward法作聚類分析,並畫出相應的譜系圖。
統計分析之引數檢驗與非引數檢驗、匹配樣本與獨立樣本、2樣本與K樣本介紹----附SPSS操作指南
最近幾天博主需要做一些計算生物學分析,重新溫習了一遍統計學的知識。由於博主此次使用的是非引數檢驗,將重點介紹非引數檢驗相關內容,仍然是深入淺出的風格,先放一些概念,再總結實際使用的技巧。寫在這裡,供大家參考學習。
分享《機器學習與資料科學(基於R的統計學習方法)》高清中文PDF+原始碼
下載:https://pan.baidu.com/s/1Lrgtp7bnVeLoUO46qPHFJg 更多資料:http://blog.51cto.com/3215120 高清中文PDF,299頁,帶書籤目錄,文字可以複製。配套原始碼。 本書指導讀者利用R語言完成涉及機器學習的資料科學專案。作者: Da
分享《機器學習與數據科學(基於R的統計學習方法)》高清中文PDF+源代碼
data 圖片 intro enc proc 文字 目錄 baidu fff 下載:https://pan.baidu.com/s/1Lrgtp7bnVeLoUO46qPHFJg 更多資料:http://blog.51cto.com/3215120 高清中文PDF,299頁
分享《機器學習與數據科學(基於R的統計學習方法)》+PDF+源碼+Daniel+施翔
目錄 intro r語言 ges ati href ext 學習方法 learn 下載:https://pan.baidu.com/s/1TBuxErDDcKQi4oJO3L-fEA 更多資料:http://blog.51cto.com/14087171 高清中文PDF,2
基於R的資料探勘方法與實踐(3)——決策樹分析
決策樹構建的目的有兩個——探索與預測。探索方面,參與決策樹聲場的資料為訓練資料,待樹長成後即可探索資料所隱含的資訊。預測方面,可以藉助決策樹推匯出的規則預測未來資料。由於需要考慮未來資料進入該模型的分類表現,因此在基於訓練資料構建決策樹之後,可以用測試資料來衡量該模型的穩健
Excel在統計分析中的應用—第六章—抽樣分佈-小樣本的抽樣分佈(F分佈概率密度函式圖)
F分佈的概率密度函式圖看上去還是比較平易近人的,不像卡方分佈那樣章亂無序。 Excel計算公式: C362==GAMMA((C$360+C$361)/2)*POWER(C$360,C$360/2)*POWER(C$361,C$361/2)*POWER($B362,C$360
Excel在統計分析中的應用—第六章—抽樣分佈-小樣本的抽樣分佈(t分佈)
貌似t分佈是比較有意思的一種概率分佈。 “ 在概率論和統計學中,學生t-分佈(t-distribution),可簡稱為t分佈,用於根據小樣本來估計呈正態分佈且方差未知的總體的均值。如果總體方差已知(例如在樣本數量足夠多時),則應該用正態分佈來估計總體均值。 t分佈曲線形態
機器學習與資料科學 基於R的統計學習方法(一)-第1章 機器學習綜述
1.1 機器學習的分類 監督學習:線性迴歸或邏輯迴歸, 非監督學習:是K-均值聚類, 即在資料點集中找出“聚類”。 另一種常用技術叫做主成分分析(PCA) , 用於降維, 演算法的評估方法也不盡相同。 最常用的方法是將均方根誤差(RMSE) 的值降到最小, 這一數值用於評價測試集的預測結果是否準確。 R
R資料探勘技術-基於R語言的資料探勘和統計分析技術
培訓要點 網際網路點選資料、感測資料、日誌檔案、具有豐富地理空間資訊的移動資料和涉及網路的各類評論,成為了海量資訊的多種形式。當資料以成百上千TB不斷增長的時候,我們在內部交易系統的歷史資訊之外,需要一種基於大資料分析的決策模型和技術支援。 目前對大資料的分析工具,有Had
R語言與統計分析---湯銀才
關於R中的函式或關鍵字元 命令 > help(fun) 或 ?fun 會立即顯示名為“fun”函式的幫助頁 > apropos(fun) 或 apropos("fun") 找出所有在名字中含有指定字串“fun”的函式,但只會在被載入
數據的統計分析與描述
統計量 mea median 擬合 fit skew hist uci 出現的次數 統計的任務 --> 由樣本推斷總體 1.頻數表與直方圖 -->將數據取值劃分區間,統計每個區間出現的次數 1)讀入數據並轉換為向量 2)[N,X]=hist(Y,M
bug統計分析續(一)基於SQL的Bug統計方法
擴展 span tom div info 依據 desc pos title 本文由 @lonelyrains 出品。轉載請註明出處。 文章鏈接: http://blog.csdn.net/lonelyrains/article/details/44225533
R語言統計分析技術研究——嶺回歸技術的原理和應用
gts 根據 誤差 med 分享 jce not -c rt4 嶺回歸技術的原理和應用
基於MapReduce的手機流量統計分析
methods ica spec err reduce same new form sel 1,代碼 package mr; import java.io.IOException; import org.apache.commons.lang.StringUtils;
BioNano生物納米分子的“原始數據到完成裝配和組裝分析”管線與基於序列的基因組FASTA映射
mach read code tar 文本文 項目目錄 基本 組合 erl 生物納米分子的“原始數據到完成裝配和組裝分析”管線與基於序列的基因組FASTA映射 您完成本實驗以及示例數據集所需的所有腳本將按照以下說明復制到計算機。您應該按照以下說明,將米色代碼塊中的文本鍵入
R語言實戰 - 基本統計分析(1)- 描述性統計分析
4.3 summary eas 方法 func -- 4.4 1.0 6.5 > vars <- c("mpg", "hp", "wt") > head(mtcars[vars]) mpg hp wt Maz
基於HBase的MapReduce實現大量郵件信息統計分析
inittab 寫入 img implement system return dea 比較 tco 一:概述 在大多數情況下,如果使用MapReduce進行batch處理,文件一般是存儲在HDFS上的,但這裏有個很重要的場景不能忽視,那就是對於大量的小文件的處理(此處小文件