
使用requests和scrapy模擬知乎登入
獲取登入傳遞的引數
可以看到,這裡當登入的時候,是傳遞紅色部分標註出來的四個引數的,並且訪問的是https://www.zhihu.com/login/phone_num地址,但是這裡驗證碼需要使用者點選倒立的字,目前我還沒有辦法,但是可以使用手機端登入看看,其實是讓使用者輸入登入驗證碼的,因此,可以使用手機端的user-agent
使用requests模擬登入
手機端登入時候需要傳遞下面四個引數
data = {
'_xsrf': _xsrf,
'password': password,
'phone_num': phonenumber,
'captcha' 其中password和phone_num是密碼和使用者名稱,_xsrf和captcha_type是瀏覽器自己帶的hidden值
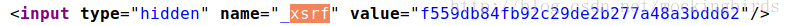
獲取xsrf引數
由於使用者名稱和密碼已經知道,下面就定義兩個方法,分別用來獲取_xsrf和captcha_type引數,從上面的分析可知,只需要獲取網頁內容,然後通過正則表示式解析對應的內容即可獲得
獲取網頁內容
import requests
def get_xsrf():
response = requests.get('https://www.zhihu.com')
print(response.text) 
這是因為沒有配置請求頭,新增請求頭即可
header = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36',
'Host': 'www.zhihu.com',
'Referer': 'https://www.zhihu.com/',
}
def get_xsrf():
response = requests.get('https://www.zhihu.com' 此時就可以正常訪問了
獲取xsrf引數
text = '<input type="hidden" name="_xsrf" value="f559db84fb92c29de2b277a48a3bdd62"/>'
response = session.get('https://www.zhihu.com', headers=header)
soup = BeautifulSoup(response.text)
crsf = soup.select('input[name="_xsrf"]')[0]['value']
print(crsf)
上面可以正確獲取到xsrf引數,所以只需要將text替換為網頁內容即可
def get_xsrf():
response = session.get('https://www.zhihu.com', headers=header)
soup = BeautifulSoup(response.text)
crsf = soup.select('input[name="_xsrf"]')[0]['value']
print(soup.select('input[name="_xsrf"]')[0]['value'])
return crsf獲取驗證碼
def get_captcha():
t = str(int(time.time() * 1000))
captcha_url = 'https://www.zhihu.com/captcha.gif?r=' + t + "&type=login"
print(captcha_url)
response = session.get(captcha_url, headers=header)
with open('captcha.gif', 'wb') as f:
f.write(response.content)
f.close()
from PIL import Image
try:
im = Image.open('captcha.gif')
im.show()
im.close()
except:
pass
captcha = input('請輸入驗證碼: ')
return captcha這裡獲取驗證碼,然後人工識別,手動輸入賦值給captcha
使用requests登入
import requests
from http import cookiejar
session = requests.session()
session.cookies = cookiejar.LWPCookieJar(filename='cookies.txt')
try:
session.cookies.load(ignore_discard=True)
except:
print ("cookie未能載入")
def zhihu_login(username, passwd):
login_url = 'https://www.zhihu.com/login/phone_num'
login_data = {
'_xsrf': get_xsrf(),
'phone_num': username,
'password': passwd,
'captcha': get_captcha()
}
response = session.post(login_url, data=login_data, headers=header)
print(response.text)
session.cookies.save() # 儲存cookie
zhihu_login('手機號','密碼')此時執行結果如下:

已經登入成功
判斷是否登入成功
另外,當用戶登入成功以後,可以訪問私信介面
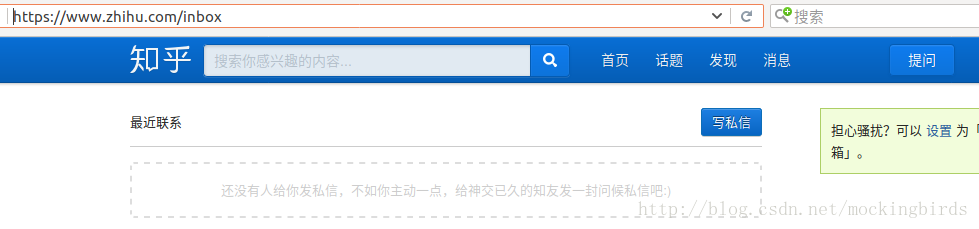
如果退出登入,或者沒有登入成功,則會跳轉到登入介面,並且返回302的狀態碼,後面會自動跳轉到https://www.zhihu.com/?next=%2Finbox,返回200狀態碼

使用requests登入完整程式碼
# -*- coding: utf-8 -*-
import requests
from http import cookiejar
from bs4 import BeautifulSoup
import time
# 獲取session
session = requests.session()
# 獲取cookies
session.cookies = cookiejar.LWPCookieJar(filename='cookies.txt')
# 獲取cookie,如果之前登入成功,並且已經cookie,則可以獲取到
try:
session.cookies.load(ignore_discard=True)
except:
print ("cookie未能載入")
# 設定請求頭
header = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36',
'Host': 'www.zhihu.com',
"Referer": "https://www.zhihu.com/",
}
# 獲取xsrf
def get_xsrf():
response = session.get('https://www.zhihu.com', headers=header)
soup = BeautifulSoup(response.text)
crsf = soup.select('input[name="_xsrf"]')[0]['value']
print(soup.select('input[name="_xsrf"]')[0]['value'])
return crsf
# 獲取驗證碼
def get_captcha():
t = str(int(time.time() * 1000))
captcha_url = 'https://www.zhihu.com/captcha.gif?r=' + t + "&type=login"
print(captcha_url)
response = session.get(captcha_url, headers=header)
with open('captcha.gif', 'wb') as f:
f.write(response.content)
f.close()
from PIL import Image
try:
im = Image.open('captcha.gif')
im.show()
im.close()
except:
pass
captcha = input('請輸入驗證碼: ')
return captcha
# 判斷是否登入成功
def is_login():
inbox_url = 'https://www.zhihu.com/inbox'
response = session.get(inbox_url, headers=header, allow_redirects=False)
if response.status_code == 200:
print('登入成功')
else:
print('登入失敗')
# 登入方法
def zhihu_login(username, passwd):
login_url = 'https://www.zhihu.com/login/phone_num'
login_data = {
'_xsrf': get_xsrf(),
'phone_num': username,
'password': passwd,
'captcha': get_captcha()
}
response = session.post(login_url, data=login_data, headers=header)
print(response.text)
session.cookies.save() # 儲存cookie
# get_captcha()
# get_xsrf()
# zhihu_login('18710840098','這裡輸入密碼')
is_login()使用scrapy模擬登入
在正式開始前,先建立工程和spider
scrapy startproject zhihu
cd zhihu
scrapy genspider zhihu www.zhihu.com完整程式碼如下:
# -*- coding: utf-8 -*-
import scrapy
from bs4 import BeautifulSoup
import json
class ZhihuspiderSpider(scrapy.Spider):
name = 'zhihuspider'
allowed_domains = ['www.zhihu.com']
start_urls = ['https://www.zhihu.com/']
# 定義請求頭
header = {
# 使用手機的User-Agent
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36',
'Host': 'www.zhihu.com',
"Referer": "https://www.zhihu.com/",
}
def parse(self, response):
print(response.text)
pass
# spider入口方法
def start_requests(self):
# 訪問https://www.zhihu.com/login/phone_num登入頁面,在do_login回撥中處理
return [scrapy.Request('https://www.zhihu.com/login/phone_num', headers=self.header, callback=self.do_login)]
def do_login(self, response):
response_text = response.text
soup = BeautifulSoup(response.text)
# 解析獲取xsrf
xsrf = soup.select('input[name="_xsrf"]')[0]['value']
if xsrf:
login_data = {
'_xsrf': xsrf,
'phone_num': '手機號',
'password': '密碼',
'captcha': ''
}
# 由於登入需要驗證碼,因此需要先獲取驗證碼,在do_login_after_captcha回撥獲取驗證碼,封裝傳遞的login_data引數
import time
t = str(int(time.time() * 1000))
captcha_url = 'https://www.zhihu.com/captcha.gif?r=' + t + "&type=login"
yield scrapy.Request(captcha_url, headers=self.header, meta={'login_data': login_data},
callback=self.do_login_after_captcha)
def do_login_after_captcha(self, response):
# 獲取驗證碼操作
with open('captcha.gif', 'wb') as f:
f.write(response.body)
f.close()
from PIL import Image
try:
im = Image.open('captcha.gif')
im.show()
im.close()
except:
pass
captcha = input('請輸入驗證碼: ')
# 登入
login_data = response.meta.get("login_data", {})
login_data['captcha'] = captcha
login_url = 'https://www.zhihu.com/login/phone_num'
# FormRequest可以完成表單提交,在check_login回撥中驗證登入是否成功
return [scrapy.FormRequest(
url=login_url,
formdata=login_data,
headers=self.header,
callback=self.check_login
)]
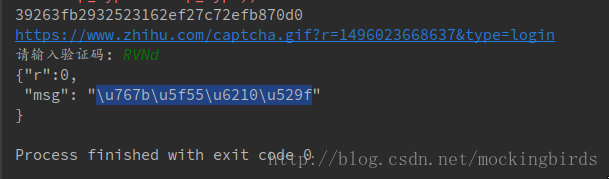
def check_login(self, response):
#驗證登入是否成功
text_json = json.loads(response.text)
if "msg" in text_json and text_json["msg"] == "登入成功":
for url in self.start_urls:
yield scrapy.Request(url, dont_filter=True, headers=self.header)
此時結果response.text中的內容儲存到本地網頁,效果如下:
相關推薦
使用requests和scrapy模擬知乎登入
獲取登入傳遞的引數 可以看到,這裡當登入的時候,是傳遞紅色部分標註出來的四個引數的,並且訪問的是https://www.zhihu.com/login/phone_num地址,但是這裡驗證碼需要使用者點選倒立的字,目前我還沒有辦法,但是可以使用手機端登入看
菜鳥寫Python實戰:Scrapy完成知乎登入並儲存cookies檔案用於請求他頁面(by Selenium)
一、前言 現在知乎的登入請求越來越複雜了,通過f12調出瀏覽器網路請求情況分析request引數,似乎不再簡單可知了,因為知乎很多請求引數都字元加密顯示了,如下圖,我們很難再知道發起請求時要傳遞什麼引數給它。 二、思路 我們知道知乎一些內容是需要登入才能看到,因
python爬蟲scrapy框架——人工識別知乎登入知乎倒立文字驗證碼和數字英文驗證碼
import requests try: import cookielib except: import http.cookiejar as cookielib import re import time def get_xsrf(): # 獲取xsrf code res
scrapy 爬取知乎登入認證部分(採用cookie登入)
scrapy 爬蟲,為非同步io框架;因此此處選擇,先用requests請求,儲存cookie檔案,然後scrapy爬取前,在入口處載入cookie。 * 登入,儲存cookie方法見前兩節,此處展示的是scrapy讀取cookie * 首先要明確,
怎麽及時掌握/把握深度學習的發展動向和狀態?(知乎)
ref com 深度學習 掌握 http 發展 targe 狀態 tar https://www.zhihu.com/question/65646397 機器學習 知乎專欄 https://www.zhihu.com/topic/19559450/hot怎麽及時掌握/把握深
python 模擬知乎登錄,包含驗證碼(轉)
mozilla log 5.0 color att pos head one 成功 #!/usr/bin/env python3 # -*- coding: utf-8 -*- ‘‘‘ Required - requests (必須) - pillow (可選) Info
知乎登入出現Miss argument grant_type 無法成功登入解決方法
知乎的模擬登入,出現Miss argument grant_type 無法成功登入, 根據網上的說法,需要進行chrome版本降級,要使用用Chrome 60版本,chromedriver2.3( 1. chrome瀏覽器降到60版本,下載地址: https://www.s
scrapy 登陸知乎
參考 https://github.com/zkqiang/Zhihu-Login # -*- coding: utf-8 -*- import scrapy import time import re import base64 import hmac import hashlib import jso
requests 和 scrapy 在不同的爬蟲應用中,各自有什麼優勢?
equests 是一個http框架,可以用來做爬蟲scrapy 是一個專業的爬蟲框架我是個python新手,研究怎麼爬人家網站,朋友推薦我學requests,果然看了下文件,幾分鐘就能開始爬了但是我看scrapy 這個爬蟲框架,被很多人喜歡,我想這個東西一定有他的獨特之處,
新版知乎登入request登入(2)(類程式設計)
接上一篇,用類重構了程式碼,方法是一致的,但是看起來更整潔些。 不多說了,上程式碼: #! /usr/local/bin python3.6 """ @Time : 2018/4/17 20:00 @Author : ysj @Site :
知乎登入以及改版後的知乎登入(小知識點)
1. 關於cookie和session 2. 英文驗證碼登入知乎(零碎知識點...喔喔...自己怕忘隨意整理一下, 有點亂) ---判斷驗證碼是否存在時, 請求的網址相對路徑為圖中:path(captcha?lang=en 請求的是英文的驗證碼) ---圖中的{
Requests 和 Scrapy 新增動態IP代理
Requests import requests # 要訪問的目標頁面 targetUrl = "http://test.abuyun.com/proxy.php" #targetUrl = "ht
scrapy知乎模擬登入和cookie登入
模擬登入# -*- coding: utf-8 -*- import scrapy from scrapy import cmdline #from scrapy.spiders import CrawlSpider import scrapy from scrap
selenium 模擬登入知乎和微博
sleep https epo element select selenium clas .com -c pip install selenium __author__ = ‘admin‘ __date__ = 2017 / 11 / 3 from selenium im
Python-requests-知乎模擬登入
繼續我的python爬蟲旅程,開始寫部落格的時候,說一天一篇,真的只是動動嘴皮子,做起來還真的難,其實是自己給自己找理由… 不管怎樣,今天來更新一篇,寫個知乎的模擬登入,感覺最開始學習爬蟲的時候,大家都期盼著可以寫那種需要登入的網站,或者有各種驗證碼的,那時
Python3 模擬登入知乎(requests)
# -*- coding: utf-8 -*- """ 知乎登入分為兩種登入 一是手機登入 API : https://www.zhihu.com/login/phone_num 二是郵箱登入 API : https://www.zhihu.c
python爬蟲scrapy框架——人工識別登入知乎倒立文字驗證碼和數字英文驗證碼(2)
import scrapy import re import json class ZhihuSpider(scrapy.Spider): name = 'zhihu' allowed_domains = ['www.zhihu.com'] start_urls = ['http
通過scrapy,從模擬登入開始爬取知乎的問答資料
這篇文章將講解如何爬取知乎上面的問答資料。 首先,我們需要知道,想要爬取知乎上面的資料,第一步肯定是登入,所以我們先介紹一下模擬登入: 先說一下我的思路: 1.首先我們需要控制登入的入口,重寫start_requests方法。來控制到這個入口之後,使用
Scrapy基礎(十四)————知乎模擬登陸
odin cookie page 表單 word sca -a 實例 登錄限制 #-*-coding:utf-8 -*-__author__ = "ruoniao"__date__ = "2017/5/31 20:59" 之前我們通過爬取伯樂在線的文章,伯樂在線對爬取沒有
爬蟲入門到精通-headers的詳細講解(模擬登入知乎)
直接開始案例吧。 本次我們實現如何模擬登陸知乎。 1.抓包 首先開啟知乎登入頁 知乎 - 與世界分享你的知識、經驗和見解 注意開啟開發者工具後點擊“preserve log”,密碼記得故意輸入錯誤,然後點選登入 我們很簡單的就找到了 我們需要的請