
Kafka學習總結(三)——Kafka的message儲存資料結構
引言
Kafka中的Message是以topic為基本單位組織的,不同的topic之間是相互獨立的。每個topic又可以分成幾個不同的partition(每個topic有幾個partition是在建立topic時指定的),每個partition儲存一部分Message。借用官方的一張圖,可以直觀地看到topic和partition的關係。
partition是以檔案的形式儲存在檔案系統中,比如,建立了一個名為page_visits的topic,其有5個partition,那麼在Kafka的資料目錄中(由配置檔案中的log.dirs指定的)中就有這樣5個目錄: page_visits-0, page_visits-1,page_visits-2,page_visits-3,page_visits-4,其命名規則為<topic_name>-<partition_id>,裡面儲存的分別就是這5個partition的資料。
接下來,本文將分析partition目錄中的檔案的儲存格式和相關的程式碼所在的位置。
3.1、Partition的資料檔案
Partition中的每條Message由offset來表示它在這個partition中的偏移量,這個offset不是該Message在partition資料檔案中的實際儲存位置,而是邏輯上一個值,它唯一確定了partition中的一條Message。因此,可以認為offset是partition中Message的id。partition中的每條Message包含了以下三個屬性:
- offset
- MessageSize
- data
其中offset為long型,MessageSize為int32,表示data有多大,data為message的具體內容。它的格式和
Partition的資料檔案則包含了若干條上述格式的Message,按offset由小到大排列在一起。它的實現類為FileMessageSet,類圖如下:
它的主要方法如下:
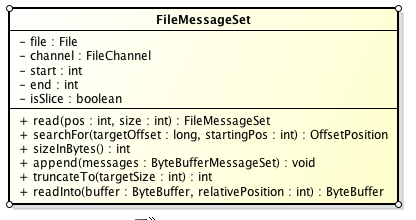
- append: 把給定的ByteBufferMessageSet中的Message寫入到這個資料檔案中。
- searchFor: 從指定的startingPosition開始搜尋找到第一個Message其offset是大於或者等於指定的offset,並返回其在檔案中的位置Position。它的實現方式是從startingPosition開始讀取12個位元組,分別是當前MessageSet的offset和size。如果當前offset小於指定的offset,那麼將position向後移動LogOverHead+MessageSize(其中LogOverHead為offset+messagesize,為12個位元組)。
- read:準確名字應該是slice,它擷取其中一部分返回一個新的FileMessageSet。它不保證擷取的位置資料的完整性。
- sizeInBytes: 表示這個FileMessageSet佔有了多少位元組的空間。
- truncateTo: 把這個檔案截斷,這個方法不保證截斷位置的Message的完整性。
- readInto: 從指定的相對位置開始把檔案的內容讀取到對應的ByteBuffer中。
我們來思考一下,如果一個partition只有一個數據檔案會怎麼樣?
- 新資料是新增在檔案末尾(呼叫FileMessageSet的append方法),不論檔案資料檔案有多大,這個操作永遠都是O(1)的。
- 查詢某個offset的Message(呼叫FileMessageSet的searchFor方法)是順序查詢的。因此,如果資料檔案很大的話,查詢的效率就低。
那Kafka是如何解決查詢效率的的問題呢?有兩大法寶:1) 分段 2) 索引。
3.2、資料檔案的分段
Kafka解決查詢效率的手段之一是將資料檔案分段,比如有100條Message,它們的offset是從0到99。假設將資料檔案分成5段,第一段為0-19,第二段為20-39,以此類推,每段放在一個單獨的資料檔案裡面,資料檔案以該段中最小的offset命名。這樣在查詢指定offset的Message的時候,用二分查詢就可以定位到該Message在哪個段中。
3.3、為資料檔案建索引
資料檔案分段使得可以在一個較小的資料檔案中查詢對應offset的Message了,但是這依然需要順序掃描才能找到對應offset的Message。為了進一步提高查詢的效率,Kafka為每個分段後的資料檔案建立了索引檔案,檔名與資料檔案的名字是一樣的,只是副檔名為.index。
索引檔案中包含若干個索引條目,每個條目表示資料檔案中一條Message的索引。索引包含兩個部分(均為4個位元組的數字),分別為相對offset和position。
- 相對offset:因為資料檔案分段以後,每個資料檔案的起始offset不為0,相對offset表示這條Message相對於其所屬資料檔案中最小的offset的大小。舉例,分段後的一個數據檔案的offset是從20開始,那麼offset為25的Message在index檔案中的相對offset就是25-20 = 5。儲存相對offset可以減小索引檔案佔用的空間。
- position,表示該條Message在資料檔案中的絕對位置。只要開啟檔案並移動檔案指標到這個position就可以讀取對應的Message了。
index檔案中並沒有為資料檔案中的每條Message建立索引,而是採用了稀疏儲存的方式,每隔一定位元組的資料建立一條索引。這樣避免了索引檔案佔用過多的空間,從而可以將索引檔案保留在記憶體中。但缺點是沒有建立索引的Message也不能一次定位到其在資料檔案的位置,從而需要做一次順序掃描,但是這次順序掃描的範圍就很小了。
在Kafka中,索引檔案的實現類為OffsetIndex,它的類圖如下:

主要的方法有:
- append方法,新增一對offset和position到index檔案中,這裡的offset將會被轉成相對的offset。
- lookup, 用二分查詢的方式去查詢小於或等於給定offset的最大的那個offset
小結
我們以幾張圖來總結一下Message是如何在Kafka中儲存的,以及如何查詢指定offset的Message的。
Message是按照topic來組織,每個topic可以分成多個的partition,比如:有5個partition的名為為page_visits的topic的目錄結構為:

partition是分段的,每個段叫LogSegment,包括了一個數據檔案和一個索引檔案,下圖是某個partition目錄下的檔案:
可以看到,這個partition有4個LogSegment。

展示是如何查詢Message的。
比如:要查詢絕對offset為7的Message:
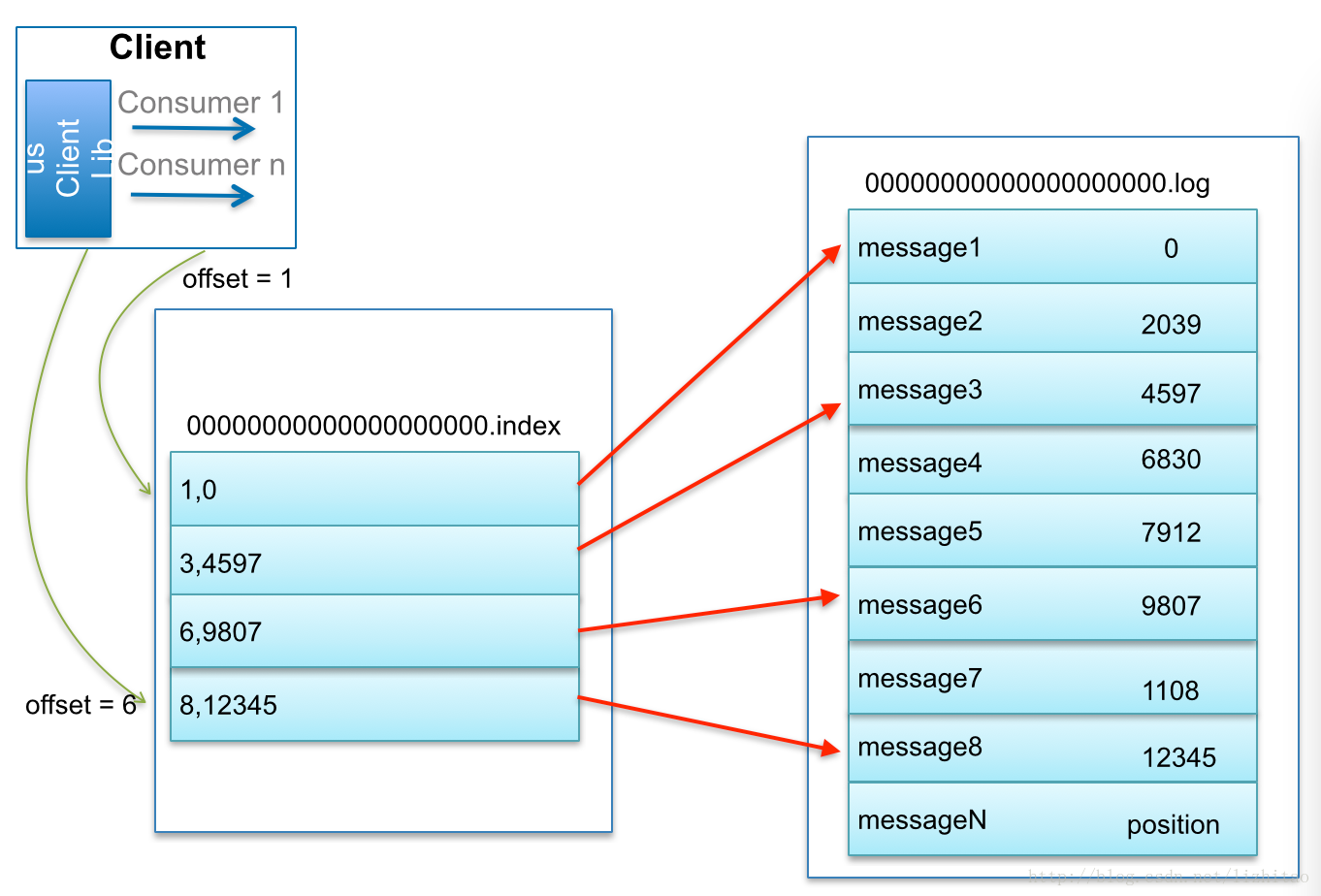
- 首先是用二分查詢確定它是在哪個LogSegment中,自然是在第一個Segment中。
- 開啟這個Segment的index檔案,也是用二分查詢找到offset小於或者等於指定offset的索引條目中最大的那個offset。自然offset為6的那個索引是我們要找的,通過索引檔案我們知道offset為6的Message在資料檔案中的位置為9807。
- 開啟資料檔案,從位置為9807的那個地方開始順序掃描直到找到offset為7的那條Message。
這套機制是建立在offset是有序的。索引檔案被對映到記憶體中,所以查詢的速度還是很快的。
一句話,Kafka的Message儲存採用了分割槽(partition),分段(LogSegment)和稀疏索引這幾個手段來達到了高效性。
相關推薦
Kafka學習總結(三)——Kafka的message儲存資料結構
引言 Kafka中的Message是以topic為基本單位組織的,不同的topic之間是相互獨立的。每個topic又可以分成幾個不同的partition(每個topic有幾個partition是在建立topic時指定的),每個partition儲存一部分Message。
Python學習筆記 Day12 json儲存資料及階段總結
Day 12 json儲存資料 及 階段總結 json格式化 JSON(JavaScript Object Notation) 是一種輕量級的資料交換格式。它基於 ECMAScript (歐洲計算機協會制定的js規範)的一個子集,採用完全獨立於程式語言的文字
3、Kafka的message儲存資料結構
轉載自:http://blog.csdn.net/gongxinju/article/details/72672375 Kafka中的Message是以topic為基本單位組織的,不同的topic之間是相互獨立的。每個topic又可以分成幾個不同的partition(每
《資料結構》第三篇、資料結構中儲存結構
創:戰紀.jpeg資料結構除了按照邏輯結構來分,還可以按照儲存結構來分。儲存結構反應的是資料元素在計算機中的儲存形式,如何在計算機中正確的描述資料元素之間的邏輯關係,才是資料結構的關鍵和重點。常用的儲存結構有1、順序儲存結構2、鏈式儲存結構3、索引儲存結構4、散列表4種,接下
Odoo10學習筆記三:模型(結構化的應用數據)、視圖(用戶界面設計)
其他 描述 用戶界面 列表 支持 字段 界面設計 允許 學習 一:模型 1:創建模型 模型屬性:模型類可以使用一些屬性來控制它們的一些行為: _name :創建odoo模型的內部標識符,必含項。 _description :當用戶界面顯示模型時,一個方便用戶的模型記錄標題。
dubbo學習總結三 消費端
註意 服務端 註意點 發送 blog dubbo tro http ref 消費端跟服務端類似 註意點是dubbo:reference 和服務端的dubbo:service做區分 消費端主要是處理發送過來的請求 dubbo學習總結三 消費端
kafka學習總結
.com es2017 alt images nbsp src blog ima logs kafka啟動流程: kafka學習總結
Orleans學習總結(三)--持久化篇
cor ttr ssa cati write lob conf div love 經過上篇Orleans學習總結(二)--創建工程的介紹,我們的工程已經跑起來了,下面我們來介紹下持久化相關。 關於持久化的文檔地址在這http://dotnet.github.io/orlea
《javascript 高級程序設計》學習總結 三(1)
java 關鍵字 下一個 引用 global 討論 其他瀏覽器 而後 rom 引言:任何語言的核心都必然會描述這門語言的最基本的工作原理,而描述的內容通常都要涉及這門語言的語法、操作符、數據類型、內置功能等用於構建復雜解決方案的基本概念。 今天我就這些基本的概念開始進
Spring Boot學習總結三
() 無配置文件 select 就會 配置文件 配置 模式 mysq pre 1,mybatis在spring boot下的2種使用模式 無配置文件註解版 application.properties添加相關配置 mybatis.type-aliases-package=c
redis學習(二) redis資料結構介紹以及常用命令
redis資料結構介紹 我們已經知道redis是一個基於key-value資料儲存的資料結構資料庫,這裡的key指的是string型別,而對應的value則可以是多樣的資料結構。其中包括下面五種型別: 1.string 字串 string字串型別是redis最基礎的資料儲存型別。
MyBatis學習——第三篇(資料批量處理)
1:資料批量處理方法有兩種 第一種:傳統的sqlsession的批量處理方法 第二種:ExecutorType.BATCH 介面程式碼如下: //批量新增資料 public int addPersons(@Param("persons1") List<Per
Kafka學習(三)簡單例項(可以簡單做測試)
java客戶端連線kafka簡單測試 本案例kafka版本是kafka_2.11-0.9.0.1,用java來實現kafka生產者、消費者的示例 在測試的過程中遇到的特別的問題以及解決辦法,其他小問題就不一一列舉了。 1 . 使用kafka-clients進行測試,maven依賴
Servlet3.0學習總結(三)——基於Servlet3.0的檔案上傳
在Servlet2.5中,我們要實現檔案上傳功能時,一般都需要藉助第三方開源元件,例如Apache的commons-fileupload元件,在Servlet3.0中提供了對檔案上傳的原生支援,我們不需要藉助任何第三方上傳元件,直接使用Servlet3.0提供的API就能夠實現檔案上傳功能了。
結構體基礎知識總結以及在高階資料結構中的寫法
在寫了幾種資料結構之後覺得結構體非常重要,但自己掌握得並不好,需要一點小總結。 以下基礎知識大多來自網站菜鳥教程: http://www.runoob.com/cprogramming/c-structures.html 格式: struct tag {
MyBatis的學習總結三——輸入對映和輸出對映以及多表關聯查詢
關於MyBatis的輸入對映和輸出對映,可輸入的型別很多,輸出型別亦是如此。如圖所示: 一、輸入型別是通過引數parameterType來設定的,引數型別有基本資料型別、包裝型別pojo、Map 基礎型別(String,int,long,double...) pojo型別
Redis 第三章 1資料結構—字串
Key的定義注意點: 不要太長,或者太短。 統一的命名規範。 儲存String,以二進位制儲存 。最大儲存長度512M。 儲存String常用命令 賦值 取值 刪除 數值增減 擴充套件命令 連線到redis控制檯: //切換到bin目錄 cd /usr/local/bin /
Mybatis學習總結三之簡化sql對映xml檔案中的引用及解決欄位名與實體類屬性名不相同的衝突
一、為實體類定義別名,簡化sql對映xml檔案中的引用 我們在sql對映xml檔案中的引用實體類時,需要寫上實體類的全類名(包名+類名),如下:parameterType="com.aiit.pojo.User"這裡寫的實體類User的全類名com.aiit.pojo.User, <i
Redis知識總結--五種基礎資料結構
string string應該是redis最常被用到的資料結構,簡單的get、set即可操作。 為了避免記憶體空間不夠造成頻繁擴容,通常會分配一塊大於value長度的記憶體空間,空間大小使用capicity表示,value長度使用length表示,capicity>length,底層實
docker學習總結三
獲取映象docker pull 預設從docker hub映象源下載映象格式為docker pull NAME:TAG //:TAG可寫可不寫,不寫預設最新版$ docker pull ubuntu:16.04$ docker pull centos建立容器$ docker run -it centos