
《機器學習實戰》第二章——K-近鄰演算法
1.K-近鄰演算法(kNN)
1.1K-近鄰演算法概述
簡單的說,K-近鄰演算法採用測量不同特徵值之間的距離方法進行分類
優點:精度高、對異常值不敏感、無資料輸入假定
缺點:計算複雜度高、空間複雜度高
適用資料範圍:數值型和標稱型
1.2KNN演算法原理
存在一個樣本訓練資料集合,並且每個樣本資料都存在標籤,即我們知道樣本集中每一位資料和所屬分類的對應關係。輸入沒有新標籤的資料集後,將新資料的每個特徵與資料集樣本中的對應的特徵進行比較,然後演算法提取樣本集中特徵最相近的資料(最近鄰)的分類標籤。一般來說,我們只選擇資料集中前k個最相似的資料,這就是K-近鄰演算法中k的出處。通常K是不大於20的整數。最後選擇最相似資料中出現次數最多的分類,作為新資料的分類。
電影型別評估程式碼(本書所需的資料集可到這位大神的GitHub下載)
import numpy as np import operator def createDataSet(): group=np.array([[3,104],[2,100],[101,10],[99,5]]) #四組二維特徵 labels=['愛情片','愛情片','動作片','動作片'] #四組二維特徵對應的標籤 return group,labels def classify0(inX,dataSet,labels,k): dataSetSize=dataSet.shape[0] #numpy函式shape[0]返回dataSet的行數 diffMat=np.tile(inX,(dataSetSize,1))-dataSet #np.tile()函式,把陣列沿各個方向複製,此例中是沿橫向複製一倍(其實是沒有增加),縱向複製dataSetSize次 sqDiffMat=diffMat**2 sqDistances=sqDiffMat.sum(axis=1) #sum(0)列相加,sum(1)行相加 distances=sqDistances**0.5 sortedDistIndicies=distances.argsort() #返回distance中元素從小到大的排列值 classCount={} for i in range(k): votelabel=labels[sortedDistIndicies[i]] #取出前k個元素的類別 classCount[votelabel]=classCount.get(votelabel,0)+1 #dict.get(key,default=None),字典的get方法,返回指定鍵的值,如果不在字典中返回預設值 #計算類別次數 sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) #字典函式items(),函式以列表返回可遍歷的鍵和值 #python3中用items()替換python2中的iteritems() #key=operator.itemgetter[1]根據字典的值進行排序 #key=operator.itemgetter[0 ]根據字典的鍵進行排序 #reverse降序排序字典 return sortedClassCount[0][0] #返回次數最多的類別 if __name__=='__main__': group,labels=createDataSet() test=[3,100] result=classify0(test,group,labels,2) print(result)
執行結果:

在約會網站上使用K—近鄰演算法尋找合適海倫的人
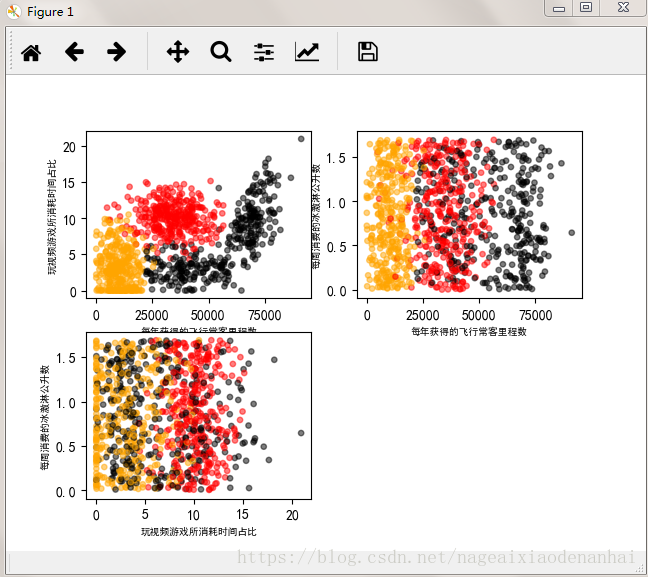
分析資料:使用Matplotlib建立散點圖
執行結果:import numpy as np import matplotlib import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['SimHei'] #用來正常顯示中文標籤 plt.rcParams['axes.unicode_minus']=False #用來正常顯示負號 def file2matrix(filename): fr=open(filename) arrayOlLines=fr.readlines() #讀取檔案所有內容 numberOfLines=len(arrayOlLines) returnMat=np.zeros((numberOfLines,3)) #np.zeros()函式生成矩陣中的值全為0 classLabelVector=[] index=0 for line in arrayOlLines: line=line.strip() #strip(),括號為空時,預設刪除空白符(包括\n,\r,\t) listFromline=line.split('\t') returnMat[index,:]=listFromline[0:3] if listFromline[-1]=='didntLike': classLabelVector.append(1) elif listFromline[-1]=='smallDoses': classLabelVector.append(2) elif listFromline[-1]=='largeDoses': classLabelVector.append(3) index+=1 return returnMat,classLabelVector def showdata(data,classla): fig=plt.figure() #產生一個空視窗 ax=fig.add_subplot(221)#221的意思是把一張圖片分為兩行兩列,把ax要顯示的放在第一張圖上 bx=fig.add_subplot(222) cx=fig.add_subplot(223) #將fig畫布分隔成1行1列,不共享x軸和y軸,fig畫布的大小為(13,8) #當nrow=2,nclos=2時,代表fig畫布被分為四個區域,axs[0][0]表示第一行第一個區域 #fig, axs = plt.subplots(nrows=2, ncols=2,sharex=False, sharey=False, figsize=(13,8)) #number0fLabels=len(data) labelsColors=[] for i in classla: if i==1: labelsColors.append('black') if i==2: labelsColors.append('orange') if i==3: labelsColors.append('red') #print(type(data),type(classla)) ax.scatter(data[:,0],data[:,1],color=labelsColors,s=15,alpha=.5) bx.scatter(data[:,0],data[:,2],color=labelsColors,s=15,alpha=.5) cx.scatter(data[:,1],data[:,2],color=labelsColors,s=15,alpha=.5) ax_xlabel_text = ax.set_xlabel(u'每年獲得的飛行常客里程數') ax_ylabel_text = ax.set_ylabel(u'玩視訊遊戲所消耗時間佔比') bx_xlabel_text = bx.set_xlabel(u'每年獲得的飛行常客里程數') bx_ylabel_text = bx.set_ylabel(u'每週消費的冰激淋公升數') cx_xlabel_text = cx.set_xlabel(u'玩視訊遊戲所消耗時間佔比') cx_ylabel_text = cx.set_ylabel(u'每週消費的冰激淋公升數') plt.setp(ax_xlabel_text, size=7, weight='bold', color='black') plt.setp(bx_xlabel_text, size=7, weight='bold', color='black') plt.setp(cx_xlabel_text, size=7, weight='bold', color='black') plt.setp(ax_ylabel_text, size=7, weight='bold', color='black') plt.setp(bx_ylabel_text, size=7, weight='bold', color='black') plt.setp(cx_ylabel_text, size=7, weight='bold', color='black') plt.show() if __name__=="__main__": data,classla=file2matrix('./datingTestSet.txt') showdata(data,classla)
準備資料,這裡使用了歐式距離來計算兩個點之間的距離:
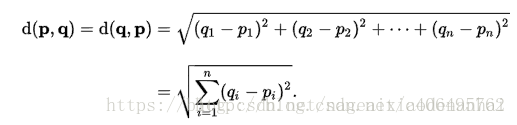
然後對資料做了歸一化處理
歸一化程式碼:
#準備資料,歸一化資料
# -*- coding: utf-8 -*-
"""
Created on Sun Apr 1 20:11:04 2018
@author: Administrator
"""
import operator
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
def classify0(inX,dataSet,labels,k):
dataSetSize=dataSet.shape[0]
#numpy函式shape[0]返回dataSet的行數
diffMat=np.tile(inX,(dataSetSize,1))-dataSet
#np.tile()函式,把陣列沿各個方向複製,此例中是沿橫向複製一倍(其實是沒有增加),縱向複製dataSetSize次
sqDiffMat=diffMat**2
sqDistances=sqDiffMat.sum(axis=1)
#sum(0)列相加,sum(1)行相加
distances=sqDistances**0.5
sortedDistIndicies=distances.argsort()
#返回distance中元素從小到大的排列值
classCount={}
for i in range(k):
votelabel=labels[sortedDistIndicies[i]]
#取出前k個元素的類別
classCount[votelabel]=classCount.get(votelabel,0)+1
#dict.get(key,default=None),字典的get方法,返回指定鍵的值,如果不在字典中返回預設值
#計算類別次數
sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#字典函式items(),函式以列表返回可遍歷的鍵和值
#python3中用items()替換python2中的iteritems()
#key=operator.itemgetter[1]根據字典的值進行排序
#key=operator.itemgetter[0 ]根據字典的鍵進行排序
#reverse降序排序字典
return sortedClassCount[0][0]
#返回次數最多的類別
#準備資料,歸一化資料
def autoNorm(dataSet):
min=dataSet.min(0)
max=dataSet.max(0)
ranges=max-min
m=dataSet.shape[0]
normDataSet=dataSet-np.tile(min,(m,1))
normDataSet=normDataSet/np.tile(ranges,(m,1))
return normDataSet,ranges,min
def file2matrix(filename):
fr=open(filename)
arrayOlLines=fr.readlines()
#讀取檔案所有內容
numberOfLines=len(arrayOlLines)
returnMat=np.zeros((numberOfLines,3))
#np.zeros()函式生成矩陣中的值全為0
classLabelVector=[]
index=0
for line in arrayOlLines:
line=line.strip()
#strip(),括號為空時,預設刪除空白符(包括\n,\r,\t)
listFromline=line.split('\t')
returnMat[index,:]=listFromline[0:3]
if listFromline[-1]=='didntLike':
classLabelVector.append(1)
elif listFromline[-1]=='smallDoses':
classLabelVector.append(2)
elif listFromline[-1]=='largeDoses':
classLabelVector.append(3)
index+=1
return returnMat,classLabelVector
if __name__=="__main__":
data,classla=file2matrix('./datingTestSet.txt')
data1=autoNorm(data)
print(data1)
執行結果:

用完整程式碼測試分類器效果
# -*- coding: utf-8 -*-
"""
Created on Sun Apr 1 20:11:04 2018
@author: Administrator
"""
import operator
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
def classify0(inX,dataSet,labels,k):
dataSetSize=dataSet.shape[0]
#numpy函式shape[0]返回dataSet的行數
diffMat=np.tile(inX,(dataSetSize,1))-dataSet
#np.tile()函式,把陣列沿各個方向複製,此例中是沿橫向複製一倍(其實是沒有增加),縱向複製dataSetSize次
sqDiffMat=diffMat**2
sqDistances=sqDiffMat.sum(axis=1)
#sum(0)列相加,sum(1)行相加
distances=sqDistances**0.5
sortedDistIndicies=distances.argsort()
#返回distance中元素從小到大的排列值
classCount={}
for i in range(k):
votelabel=labels[sortedDistIndicies[i]]
#取出前k個元素的類別
classCount[votelabel]=classCount.get(votelabel,0)+1
#dict.get(key,default=None),字典的get方法,返回指定鍵的值,如果不在字典中返回預設值
#計算類別次數
sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#字典函式items(),函式以列表返回可遍歷的鍵和值
#python3中用items()替換python2中的iteritems()
#key=operator.itemgetter[1]根據字典的值進行排序
#key=operator.itemgetter[0 ]根據字典的鍵進行排序
#reverse降序排序字典
return sortedClassCount[0][0]
#返回次數最多的類別
#準備資料,歸一化資料
def autoNorm(dataSet):
min=dataSet.min(0)
max=dataSet.max(0)
ranges=max-min
m=dataSet.shape[0]
normDataSet=dataSet-np.tile(min,(m,1))
normDataSet=normDataSet/np.tile(ranges,(m,1))
return normDataSet,ranges,min
def file2matrix(filename):
fr=open(filename)
arrayOlLines=fr.readlines()
#讀取檔案所有內容
numberOfLines=len(arrayOlLines)
returnMat=np.zeros((numberOfLines,3))
#np.zeros()函式生成矩陣中的值全為0
classLabelVector=[]
index=0
for line in arrayOlLines:
line=line.strip()
#strip(),括號為空時,預設刪除空白符(包括\n,\r,\t)
listFromline=line.split('\t')
returnMat[index,:]=listFromline[0:3]
if listFromline[-1]=='didntLike':
classLabelVector.append(1)
elif listFromline[-1]=='smallDoses':
classLabelVector.append(2)
elif listFromline[-1]=='largeDoses':
classLabelVector.append(3)
index+=1
return returnMat,classLabelVector
#測試演算法,作為完整程式驗證分類
def datingClassTest():
hoRatio=0.2
datingDataMat,datingLabels=file2matrix('datingTestSet.txt')
normMat,ranges,min=autoNorm(datingDataMat)
m=normMat.shape[0]
numTestVecs=int(m*hoRatio)
errorCount=0.0
for i in range(numTestVecs):
classifierResult=classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],5)
print('分類器返回:{},正確結果是:{}'.format(classifierResult,datingLabels[i]))
if(classifierResult!=datingLabels[i]):
errorCount+=1.0
print('the total error rate is:{}'.format(errorCount/float(numTestVecs)))
if __name__=="__main__":
datingClassTest()
執行結果:
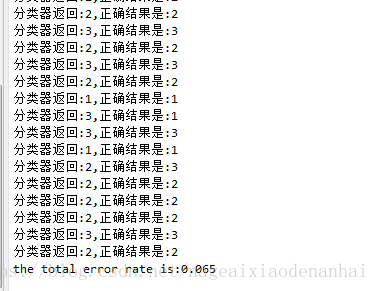
這裡的資料集錯誤率是6.5%,有點高,可以試著改變k值和hoRatio的值來調整錯誤率。
使用演算法
# -*- coding: utf-8 -*-
"""
Created on Sun Apr 1 20:11:04 2018
@author: Administrator
"""
import operator
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
def classify0(inX,dataSet,labels,k):
dataSetSize=dataSet.shape[0]
#numpy函式shape[0]返回dataSet的行數
diffMat=np.tile(inX,(dataSetSize,1))-dataSet
#np.tile()函式,把陣列沿各個方向複製,此例中是沿橫向複製一倍(其實是沒有增加),縱向複製dataSetSize次
sqDiffMat=diffMat**2
sqDistances=sqDiffMat.sum(axis=1)
#sum(0)列相加,sum(1)行相加
distances=sqDistances**0.5
sortedDistIndicies=distances.argsort()
#返回distance中元素從小到大的排列值
classCount={}
for i in range(k):
votelabel=labels[sortedDistIndicies[i]]
#取出前k個元素的類別
classCount[votelabel]=classCount.get(votelabel,0)+1
#dict.get(key,default=None),字典的get方法,返回指定鍵的值,如果不在字典中返回預設值
#計算類別次數
sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#字典函式items(),函式以列表返回可遍歷的鍵和值
#python3中用items()替換python2中的iteritems()
#key=operator.itemgetter[1]根據字典的值進行排序
#key=operator.itemgetter[0 ]根據字典的鍵進行排序
#reverse降序排序字典
return sortedClassCount[0][0]
#返回次數最多的類別
#準備資料,歸一化資料
def autoNorm(dataSet):
min=dataSet.min(0)
max=dataSet.max(0)
ranges=max-min
m=dataSet.shape[0]
normDataSet=dataSet-np.tile(min,(m,1))
normDataSet=normDataSet/np.tile(ranges,(m,1))
return normDataSet,ranges,min
def file2matrix(filename):
fr=open(filename)
arrayOlLines=fr.readlines()
#讀取檔案所有內容
numberOfLines=len(arrayOlLines)
returnMat=np.zeros((numberOfLines,3))
#np.zeros()函式生成矩陣中的值全為0
classLabelVector=[]
index=0
for line in arrayOlLines:
line=line.strip()
#strip(),括號為空時,預設刪除空白符(包括\n,\r,\t)
listFromline=line.split('\t')
returnMat[index,:]=listFromline[0:3]
if listFromline[-1]=='didntLike':
classLabelVector.append(1)
elif listFromline[-1]=='smallDoses':
classLabelVector.append(2)
elif listFromline[-1]=='largeDoses':
classLabelVector.append(3)
index+=1
return returnMat,classLabelVector
#測試演算法,作為完整程式驗證分類
def datingClassTest():
hoRatio=0.2
datingDataMat,datingLabels=file2matrix('datingTestSet.txt')
normMat,ranges,min=autoNorm(datingDataMat)
m=normMat.shape[0]
numTestVecs=int(m*hoRatio)
errorCount=0.0
for i in range(numTestVecs):
classifierResult=classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],5)
print('分類器返回:{},正確結果是:{}'.format(classifierResult,datingLabels[i]))
if(classifierResult!=datingLabels[i]):
errorCount+=1.0
print('the total error rate is:{}'.format(errorCount/float(numTestVecs)))
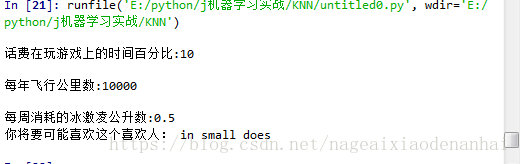
def classifPreson():
resultList=['nor at all','in small does','in large doses']
percentTate=float(input('話費在玩遊戲上的時間百分比:'))
ffMile=float(input('每年飛行公里數:'))
iceCream=float(input('每週消耗的冰激凌公升數:'))
dataset,dataLabels=file2matrix('datingTestSet.txt')
normMat,ranges,min=autoNorm(dataset)
inArr=np.array([ffMile,percentTate,iceCream])
classifierresult=classify0((inArr-min)/ranges,normMat,dataLabels,3)
print('你將要可能喜歡這個喜歡人:',resultList[classifierresult-1])
if __name__=="__main__":
#datingClassTest()
classifPreson()
執行結果:
sklearn實戰——手寫識別系統
sklearn有提供KNN演算法的API,直接呼叫即可。
import numpy as np
import operator
from sklearn.neighbors import KNeighborsClassifier as kNN
from os import listdir
def img2vector(filename):
returnvect=np.zeros((1,1024))
fr=open(filename)
for i in range(32):
linestr=fr.readline()
for j in range(32):
returnvect[0,32*i+j]=int(linestr[j])
return returnvect
def handwritingClassTest():
hwLabels=[]
trainingFileList=listdir('trainingDigits')
m=len(trainingFileList)
trainingMat=np.zeros((m,1024))
for i in range(m):
fileNameStr=trainingFileList[i]
classNumber=int(fileNameStr.split('_')[0])
hwLabels.append(classNumber)
trainingMat[i,:]=img2vector('trainingDigits/{}'.format(fileNameStr))
neigh=kNN(n_neighbors=3,algorithm='auto')
neigh.fit(trainingMat,hwLabels)
testFileList=listdir('testDigits')
errorCount=0.0
mtest=len(testFileList)
for i in range(mtest):
fileNameStr=testFileList[i]
classNumber=int(fileNameStr.split('_')[0])
vectoUndertest=img2vector('testDigits/{}'.format(fileNameStr))
classifierResult=neigh.predict(vectoUndertest)
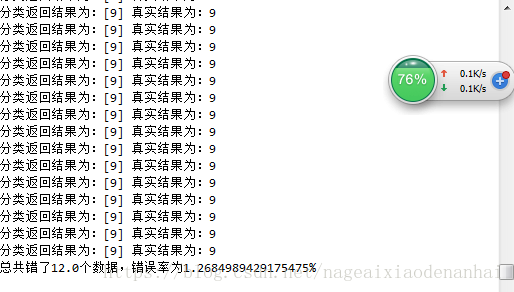
print('分類返回結果為:{} 真實結果為:{}'.format(classifierResult,classNumber))
if (classifierResult!=classNumber):
errorCount+=1
print('總共錯了{}個數據,錯誤率為{}'.format(errorCount,errorCount/mtest*100))
if __name__=='__main__':
handwritingClassTest()
執行結果:
相關推薦
C++單刷《機器學習實戰》之一——k-近鄰演算法
數學系研二渣碩一枚,最早接觸機器學習還是在研究生一年級的模式識別課程上,發現大部分機器學習的書籍都是採用Python語言,當然Python在資料分析和矩陣計算方面確實會有很大的優勢,對於缺乏程式設計基礎又想要快速入門的同學,Python確實是首選。而從本系列開始,我將主要
機器學習實戰筆記2(k-近鄰演算法)
1:演算法簡單描述 給定訓練資料樣本和標籤,對於某測試的一個樣本資料,選擇距離其最近的k個訓練樣本,這k個訓練樣本中所屬類別最多的類即為該測試樣本的預測標籤。簡稱kNN。通常k是不大於20的整數,這裡的距離一般是歐式距離。 2:python程式碼實現 建立一個
《機器學習實戰》—— KNN(K近鄰演算法)
《機器學習實戰》可以說是學習ML的必備書籍,連載本書中的重點演算法。重點在演算法和思想,避免涉及數學和理論推導。 由於現在已經有現成的庫,不管是Sklearn還是keras,所以演算法基本不需要我們自己去寫,呼叫庫就可以,但是必須要知道如何要去調參,也就是每個
《機器學習實戰》第二章——k-近鄰演算法——筆記
在看這一章的書之前,在網上跟著博主Jack-Cui的部落格學習過,非常推薦。 部落格地址:http://blog.csdn.net/c406495762 《Python3《機器學習實戰》學習筆記(一):k-近鄰演算法(史詩級乾貨長文)》 講述的非常細緻,文字幽默有趣,演算法細
《機器學習實戰》第二章——K-近鄰演算法
1.K-近鄰演算法(kNN)1.1K-近鄰演算法概述簡單的說,K-近鄰演算法採用測量不同特徵值之間的距離方法進行分類優點:精度高、對異常值不敏感、無資料輸入假定缺點:計算複雜度高、空間複雜度高適用資料範圍:數值型和標稱型1.2KNN演算法原理 存在一個樣本訓練資料集合,並且每
機器學習實戰第二章——學習KNN演算法,讀書筆記
K近鄰演算法(簡稱KNN)學習是一種常用的監督學習方法,給定測試樣本,基於某種距離度量找出訓練集中與其最靠近的k個訓練樣本,然後基於這k個“鄰居”的資訊來進行預測。通常在分類任務中可以使用“投票法”,即
機器學習實戰第二章----KNN
BE 指定 cto 文件轉換 .sh ati subplot OS umt tile的使用方法 tile(A,n)的功能是把A數組重復n次(可以在列方向,也可以在行方向) argsort()函數 argsort()函數返回的是數組中值從大到小的索引值 dict.get()
機器學習實戰-第二章代碼+註釋-KNN
rep sdn odi als cti 元素 集合 pre recv #-*- coding:utf-8 -*- #https://blog.csdn.net/fenfenmiao/article/details/52165472 from numpy import *
機器學習實戰筆記(K近鄰)
最終 而是 類別 頻率 n) 簡單 因此 當前 要素 K近鄰算法(KNN) k近鄰算法 ??k近鄰(k-nearest neighbor,KNN)是一種基本的分類與回歸算法。於1968年由Cover和Hart提出。k近鄰的輸入是實例的特征向量,對應於特征空間的點;輸出為實
機器學習(6)K近鄰演算法
k-近鄰,通過離你最近的來判斷你的類別 例子: 定義:如果一個樣本在特徵空間中的k個最相似(即特徵空間中最鄰近的樣本中大多數屬於某一類別),則該樣本屬於這個類別 K近鄰需要做標準化處理 例如: import numpy as npimport pandas as pdfrom mat
【機器學習筆記】基於k-近鄰演算法的數字識別
更多詳細內容參考《機器學習實戰》 k-近鄰演算法簡介 簡單的說,k-近鄰演算法採用測量不同特徵值之間的距離方法進行分類。它的工作原理是:存在一個樣本資料集合,也稱作訓練樣本集,並且樣本集中每個資料都存在標籤,即我們知道樣本集中每個資料與所屬分類的對應關係。輸入沒
我與機器學習 - [Today is Knn] - [K-近鄰演算法]
優點:精度高,對異常值不敏感,無資料輸入假定 缺點:計算複雜度高,空間複雜度高 適用資料範圍:數值型和標稱型 k近鄰,也就是KNN演算法,他的工作原理是:一個有監督的學習,有一個帶有標籤的訓練集,訓練,當我們輸入沒有標籤的的新資料後,將新資料的每個特徵與訓練集中的每個特徵比較,然後演算法
機器學習筆記九:K近鄰演算法(KNN)
一.基本思想 K近鄰演算法,即是給定一個訓練資料集,對新的輸入例項,在訓練資料集中找到與該例項最鄰近的K個例項,這K個例項的多數屬於某個類,就把該輸入例項分類到這個類中。如下面的圖: 通俗一點來說,就是找最“鄰近”的夥伴,通過這些夥伴的類別來看自己的類別
機器學習實戰 第二章KNN(1)python程式碼及註釋
#coding=utf8 #KNN.py from numpy import * import operator def createDataSet(): group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) #我覺
機器學習實戰之使用k-鄰近演算法改進約會網站的配對效果
1 準備資料,從文字檔案中解析資料 用到的資料是機器學習實戰書中datingTextSet2.txt 程式碼如下: from numpy import * def file2matrix(filname): fr=open(filname) arrayOLines
機器學習實施kNN之k-近鄰演算法--演算法步驟
kNN演算法步驟 1、計算已知類別資料集中的每個點與當前點之間的距離 2、按照距離遞增次序排序 3、選取與當前點距離最小的K 個點 4、確定前K個點所在類別的出現頻率 5、返回前K 個點出現頻率最高的類別作為當前點的預測分類
機器學習實戰第二章記錄
第二章講的是K-鄰近演算法from numpy import*import operatordef createDataSet(): group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) labels = ['A',
CSDN機器學習筆記十二 k-近鄰演算法實現手寫識別系統
本文主要內容來自《機器學習實戰》 示例:手寫識別系統 為了簡單起見,這裡構造的系統只能識別數字0到9。需要識別的數字要使用圖形處理軟體,處理成具有相同的色彩和大小:32*32 黑白影象。為了方便理解,這裡將影象轉換成文字格式。 1. 流程 收集
機器學習實戰之第二章 k-近鄰算法
lifo -h 訓練數據 adl sdi 加載 erro orm 數據集 第2章 k-近鄰算法 KNN 概述 k-近鄰(kNN, k-NearestNeighbor)算法主要是用來進行分類的. KNN 場景 電影可以按照題材分類,那麽如何區分 動作片 和 愛情片 呢?
【機器學習實戰】第2章 K-近鄰演算法(k-NearestNeighbor,KNN)
第2章 k-近鄰演算法 <script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=default"></script>