
使用eclipse+python編寫爬蟲獲取python百科的1000條詞條
爬蟲的機構
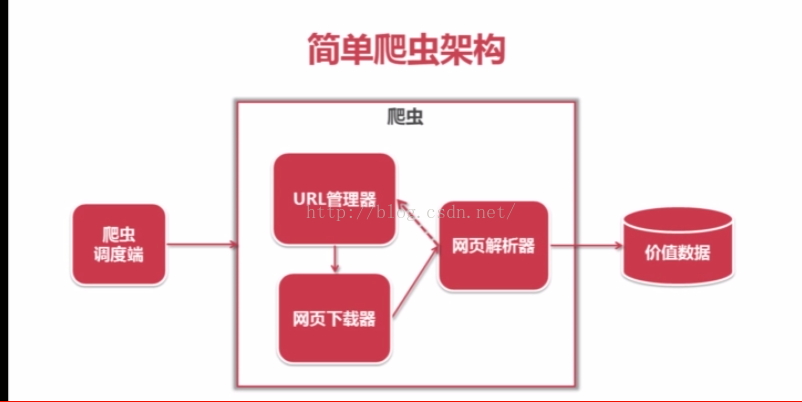
1. 爬蟲的排程端
作用是實現爬蟲的啟動,停止和監視爬蟲的執行情況
包括URL管理器:包含待爬取的URL和已經爬取的URL
把待爬取的URL送到網頁下載器,下載器會將URL指定的網頁下載下來儲存成一個字串,這個字串會傳送給玩野直譯器解析,一方面解釋出有價值的資料,和一些指向其他網頁的URL,這些URL會補充到URL管理器,這三個模組形成一個迴圈,有相關的URL就會一直執行下去。
2.
例項爬蟲的步驟
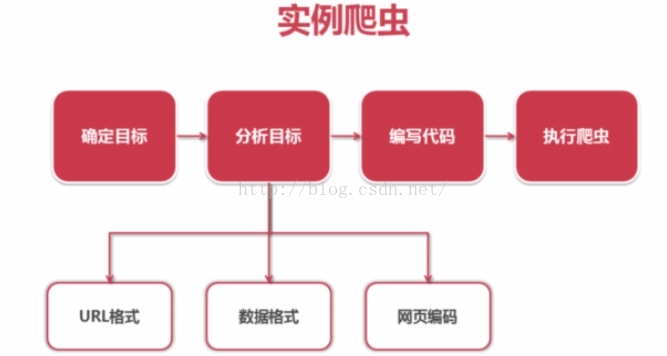
1. 確定目標:百度百科Python詞條相關詞條網頁-標題和簡介
2. 分析目標
1) URL格式
入口頁:
http://baike.baidu.com/view/125370.htm
詞條頁面URL格式:/view/125370.htm"
2)頁面編碼 UTF-8
3)資料格式
標題格式<ddclass="lemmaWgt-lemmaTitle-title"></dd>
簡介格式“<divclass="lemma-summary" label-module="lemmaSummary">
3. 編寫爬蟲
#coding:utf8
# from:http://www.imooc.com/learn/563
# By:muqingcai
from bs4import BeautifulSoup
import re
importurlparse
importurllib2
import os
#URL管理器
classUrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def add_new_url(self,url):
if url is None:
raise Exception # 為None丟擲異常
if url not in self.new_urls and url notin self.old_urls:
self.new_urls.add(url)
def add_new_urls(self,urls):
if urls is None or len(urls) == 0:
raise Exception # 為None丟擲異常
for url in urls:
self.add_new_url(url)
def has_new_url(self):
return len(self.new_urls) != 0
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
#HTML下載器
classHtmlDownloader(object):
def download(self, url):
if url is None:
return None
response = urllib2.urlopen(url)
if response.getcode() != 200:
return None
return response.read()
# HTML解析器
classHtmlParser(object):
def _get_new_urls(self,page_url,soup):
new_urls = [] ###########
# /view/123.htm: 得到所有詞條URL
links = soup.find_all("a",href=re.compile(r"/view/\d+\.htm"))
for link in links:
new_url = link["href"]
#把new_url按照page_url的格式拼接成完整的URL格式
new_full_url =urlparse.urljoin(page_url,new_url)
new_urls.append(new_full_url)
return new_urls
def _get_new_data(self,page_url,soup):
res_data = {}
#url
res_data["url"] = page_url
#<ddclass="lemmaWgt-lemmaTitle-title"><h1>Python</h1>
title_node =soup.find("dd",class_="lemmaWgt-lemmaTitle-title").find("h1")
res_data["title"] =title_node.get_text()
#<divclass="lemma-summary" label-module="lemmaSummary">
summery_node =soup.find("div",class_="lemma-summary")
res_data["summary"] =summery_node.get_text()
return res_data
def parse(self,page_url,html_cont):
if page_url is None or html_cont isNone:
return
soup = BeautifulSoup(html_cont,"html.parser", from_encoding="utf-8")
new_urls = self._get_new_urls(page_url,soup)
new_data = self._get_new_data(page_url,soup)
return new_urls, new_data
# HTML輸出器
classHtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self, data):
if data is None:
return
self.datas.append(data)
def output_html(self):
fout =open("baike_spider_output.html", "w")
fout.write("<html>")
fout.write("<head>")
fout.write('<metacharset="utf-8"></meta>')
fout.write("<title>百度百科Python頁面爬取相關資料</title>")
fout.write("</head>")
fout.write("<body>")
fout.write('<h1style="text-align:center">在百度百科中爬取相關資料展示</h1>')
fout.write("<table>")
for data in self.datas:
fout.write("<tr>")
fout.write("<td>%s</td>" % data["url"])
fout.write("<td><ahref='%s'>%s</a></td>" %(data["url"].encode("utf-8"),data["title"].encode("utf-8")))
fout.write("<td>%s</td>" %data["summary"].encode("utf-8"))
fout.write("</tr>")
fout.write("</table>")
fout.write("</body>")
fout.write("</html>")
classSpiderMain():
def craw(self, root_url, page_counts):
count = 1 #記錄爬取的是第幾個URL
UrlManager.add_new_url(root_url)
while UrlManager.has_new_url(): # 如果有待爬取的URL
try:
# 把新URL取出來
new_url =UrlManager.get_new_url()
# 記錄爬取的URL數量
print "\ncrawed %d :%s" % (count, new_url)
# 下載該URL的頁面
html_cont =HtmlDownloader.download(new_url)
# 進行頁面解析,得到新的URL和資料
new_urls, new_data =HtmlParser.parse(new_url, html_cont)
# 新URL補充進URL管理器
UrlManager.add_new_urls(new_urls)
# 進行資料的收集
HtmlOutputer.collect_data(new_data)
# 爬取到第counts個連結停止
if count == page_counts:
break
count = count + 1
except:
print "craw failed"
#輸出收集好的資料
HtmlOutputer.output_html()
if__name__=="__main__":
print "\nWelcome to use baike_spider:)"
UrlManager = UrlManager()
HtmlDownloader = HtmlDownloader()
HtmlParser = HtmlParser()
HtmlOutputer = HtmlOutputer()
root = raw_input("Enter you want tocraw which baike url: http://baike.baidu.com/view/")
root_url ="http://baike.baidu.com/view/%s" % (root) #爬蟲入口URL
page_counts = input("Enter you want tocraw how many pages:" ) #想要爬取的數量
SpiderMain = SpiderMain()
SpiderMain.craw(root_url,page_counts) #啟動爬蟲
print"\nCraw is done, please go to"+os.path.dirname(os.path.abspath('__file__')) + " to see the resultin baike_spider_output.html"
4. 執行爬蟲
直接python run即可,執行結果
如下:

..................................

……………………..
在package包下按F5即可重新整理得到

點開可以看到

相關推薦
使用eclipse+python編寫爬蟲獲取python百科的1000條詞條
爬蟲的機構 1. 爬蟲的排程端 作用是實現爬蟲的啟動,停止和監視爬蟲的執行情況 包括URL管理器:包含待爬取的URL和已經爬取的URL 把待爬取的URL送到網頁下載器,下載器會將URL指定的網頁下載下來儲存成一個字串,這個字串會傳送給玩野直譯器解析,一方面解釋
python編寫爬蟲獲取區域程式碼-遞迴獲取所有子頁面
上一篇文章用htmlparser寫了一個java的獲取區域的爬蟲,覺得太笨重。發現python也可以實現這個功能。 這裡就簡單寫一個用python3寫的小爬蟲例子 功能目標:對指定網站的所有區域資訊進行篩選,並儲存到文字中 思路:1、定義一個佇列,初始向佇列中put一個地址
python 利用爬蟲獲取頁面上下拉框裏的所有國家
span googl lec ram chrome color 模塊 獲取 ica 前段時間,領導說列一下某頁面上的所有國家信息,話說這個國家下拉框裏的國家有兩三百個,是第三方模塊導入的,手動從頁面拷貝,不切實際,於是想著用爬蟲去獲取這個國家信息,並保存到文件裏。 下面是具
python 編寫爬蟲常用包下載地址、工具網站以及相關安裝問題集合(持續更新)
轉載請標明出處,謝謝。以下連結出現問題請私戳或留言,我儘快解決。 免費代理ip網站: http://www.xicidaili.com/nn/ geckodriver 下載地址: https://github.com/mozilla/geckodrive
使用python編寫爬蟲配置環境變數以及使用scrapy
安裝python 配置python環境變數注意安裝路徑前加; 下載安裝pywin32 下載安裝pip 配置環境變數C:\Users\Jiang\AppData\Local\Programs\Python\Python36-32\Scripts 下載安裝l
【Python網路爬蟲】Python維基百科網頁抓取(BeautifulSoup+Urllib2)
引言: 從網路提取資料的需求和重要性正在變得越來越迫切。 每隔幾個星期,我都會發現自己需要從網路中提取資料。 例如,上週我們正在考慮建立一個關於網際網路上可用的各種資料科學課程的熱度和情緒指數。 這不僅需要找到新的課程,而且還要抓住網路的評論,然後在
python 3 爬蟲獲取可用ip地址(小白)
前幾天剛剛把正則表示式看了一些,也是隻是稍微懂了一點點,所以想要寫一個簡單的程式試一下。然後就想到了以前在找免費的代理的時候有好多不能用的,所以就嘗試著寫了一個這樣的爬蟲程式,寫的不是很好,寫的很複雜,等以後再去寫簡潔一些吧。 先直接把程式碼
用Python爬取了考研吧1000條帖子,原來他們都在討論這些!
寫在前面 考研在即,想多瞭解考研er的想法,就是去找學長學姐或者去網上搜索,貼吧就是一個好地方。而藉助強大的工具可以快速從網路魚龍混雜的資訊中得到有價值的資訊。雖然網上有很多爬取百度貼吧的教程和例子,但是貼吧規則更新快,目的不一樣,爬取的內容也不一樣,所以就有了這個工具。 目的 爬取1000條帖子→判斷是
使用Python的BeautifulSoup庫實現一個可以爬取1000條百度百科數據的爬蟲
otto 提取數據 tps summary 簡介 標題格式 段落 字典 如果 BeautifulSoup模塊介紹和安裝 BeautifulSoup BeautifulSoup是Python的第三方庫,用於從HTML或XML中提取數據,通常用作於網頁的解析器 Beauti
python 爬蟲獲取文件式網站資源(基於python 3.6)
codes 網頁 大小 file sel dal 網頁代碼 目錄 多級目錄 import urllib.requestfrom bs4 import BeautifulSoupfrom urllib.parse import urljoinfrom Cat.findLink
python 爬蟲獲取文件式網站資源完整版(基於python 3.6)
sta 不支持 bytes ror 啟動 www des find parse <--------------------------------下載函數-----------------------------> import requestsimport t
python 爬蟲--糗事百科段子
decode imp rst -a paragraph 糗事百科 mozilla ont ner import reimport urllib.requestfrom docx import Documentheader=("User-Agent",‘User-Agent:
零基礎掌握百度地圖興趣點獲取POI爬蟲(python語言爬取)(基礎篇)
region map 基礎 輸入 filter put mark page -h 實現目的:爬取昆明市範圍內的全部中學數據,包括名稱、坐標。 先進入基礎篇,本篇主要講原理方面,並實現步驟分解,為python代碼編寫打基礎。 因為是0基礎開始,所以講得會比較詳細。 如實現目的
使用簡單的python語句編寫爬蟲 定時拿取信息並存入txt
item line 簡單 ror article 5.5 quest win tail # -*- coding: utf-8 -*- #解決編碼問題import urllibimport urllib2import reimport osimport timepag
python 爬蟲獲取世界杯比賽賽程
star odin csv文件 cal requests tex pre brush c-c #!/usr/bin/python # -*- coding:utf8 -*- import requests import re import os import tim
用Python編寫web爬蟲的5個方法
web 描述 結構化數據 方式 網絡 提取信息 src 添加 只讀 這些庫可以使你更容易構架個人項目。 在 Python/Django 的世界裏有這樣一個諺語:為語言而來,為社區而留。對絕大多數人來說的確是這樣的,但是,還有一件事情使得我們一直停留在 Pytho
有哪些網站值得用python爬蟲獲取很有價值的資料
^___^一個程式設計師的淘寶店:點選開啟連結,助你快速學習python技術的一臂之力,不喜歡看廣告的請忽略這條! 0、IT桔子和36Kr在專欄文章中(http://zhuanlan.zhihu.com/p/20714713),抓取IT橘子和36Kr的各公司的投融資資料
Python爬蟲(二):爬蟲獲取資料儲存到檔案
接上一篇文章:Python爬蟲(一):編寫簡單爬蟲之新手入門 前言: 上一篇文章,我爬取到了豆瓣官網的頁面程式碼,我在想怎樣讓爬取到的頁面顯示出來呀,爬到的資料是html頁面程式碼,不如將爬取到的程式碼儲存到一個檔案中,檔案命名為html格式,那直接開啟這個檔案就可以在瀏覽器上看到爬取資料的
常常寫出不阻塞的爬蟲?分享5個用Python編寫非阻塞web爬蟲的方法 python
常常寫出不阻塞的爬蟲?分享5個用Python編寫非阻塞web爬蟲的方法 大家在讀爬蟲系列的帖子時常常問我怎樣寫出不阻塞的爬蟲,這很難,但可行。通過實現一些小策略可以讓你的網頁爬蟲活得更久。那麼今天我就將和大家討論這方面的話題。 使用者代理 你需要關心的第一件事是設定使用者代理。pytho
第二章 python分散式爬蟲打造搜尋引擎環境搭建 第二節正則表示式的學習和編寫練習
第一,正則表示式介紹 1. 為什麼必須會正則表示式?關於正則表達的詳細介紹可檢視一篇官網的技術文件! 正則表示式是一個特殊的字元序列,它能幫助你方便的檢查一個字串是否與某種模式匹配。正則表示式,又稱規則表示式,通常被用來檢索、替換那些符合