
spark mllib原始碼分析之L-BFGS(一)
1. 使用
spark給出的example中涉及到LBFGS有兩個,分別是LBFGSExample.scala和LogisticRegressionWithLBFGSExample.scala,第一個是直接使用LBFGS直接訓練,需要指定一系列優化引數,優點是比較靈活,可以自己控制的引數較多。後者使用了LogisticRegressionWithLBFGS,只能設定class的個數,其他引數都是固定的,其實就是將第一個中自己能控制的引數,都指定了預設值,適合剛開始時學習。
下面會以第二個為例,因為其中封裝了第一個。
// Split data into training (60%) and test (40%) 設定包含10分類,調節訓練和驗證資料集的比例
2. 邏輯迴歸與L-BFGS演算法
這一節簡單介紹邏輯迴歸和L-BFGS演算法原理,以便於程式碼實現相互對照,但是不會做嚴格的數學推理。
2.1. softmax
這裡貼兩頁程式碼註釋中給出的PPT(https://www.slideshare.net/dbtsai/2014-0620-mlor-36132297)


簡單解釋下PPT中的內容,第二頁似然函式最後的形式中,α只有當樣本的label是0的時候取1,第一項為0,其他的label取0,也就是第一項是有值的。第一項雖然在累加號裡面,但是我們注意權重w的下標yk,這意味著當累加索引k從0到N迴圈時,只有其與樣本label y(label也是從1到N)相等時,x*w才會被計算,在程式碼中這項是marginY。
對於第二項,loss和gradient計算中含有指數運算,這部分累加在程式碼中是margins變數,如果資料中存在異常點,對應到指數如果超過了709.78,就會溢位,導致訓練失敗,這裡做了一點trick,在涉及到指數計算的地方,會先判斷計算出的指數部分是否大於0,如果大於0,直接在後面加指數部分,相當於在log裡面再除掉,這樣就不會溢位了。
對比第一個式子和第三個式子,我們看到故意加1又在後面減1,這裡是為了保持形式上的一致性,程式碼實現的時候,當margin大於0,後面的累加是sum變數,根據margin是否大於0,分別計算,其他部分一樣計算。並且當margin大於0,會計算最大maxMargin,累加過程中,累加到max的時候,因為指數部分都會先減掉maxMargin,相當於結果是1,也就和後面的-1合併掉了,因此在程式碼計算的時候,當累加到maxMargin的時候,直接加上了前面那個-maxMargin了。
梯度的計算也是類似的。
2.2. L-BFGS
關於L-BFGS之前也貼過轉載的文章,詳細介紹了從牛頓法到L-BFGS是怎麼發展過來的,這裡僅僅貼出演算法部分,同時結合spark的實現簡單說下
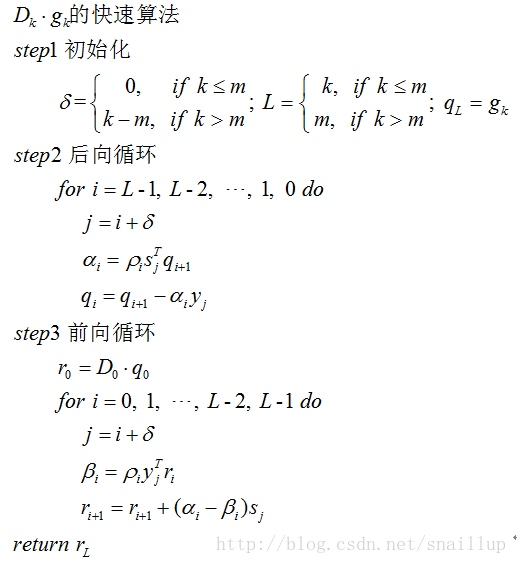
這裡的演算法僅僅是計算搜尋方向,delta和L的作用主要是當k較小時(小於m),就迭代k輪,較大時(大於m)就迭代m次。
對比Wikipedia(https://en.wikipedia.org/wiki/Limited-memory_BFGS), 這裡每輪的初值的設定應該是
3. 資料結構
3.1. LogisticRegressionWithLBFGS
上文有提到,這裡主要是封裝了LBFGS的一些引數,使得對外暴露的引數很少,值得注意的是這裡的正則化引數regParam預設是0,也就是不使用正則化。程式碼部分比較簡單,這裡簡單說下。程式碼中首先設定對特徵進行縮放,然後設定LBFGS的剃度使用LogistcGradient,正則化使用SquaredL2Updater,根據是2/多分類設定對label進行驗證的DataValidators,這裡值得注意的是,在run介面中,如果是二分類(numOfLinearPredictor == 1),這裡其實使用的是ml包中的ElasticNet,只有多分類時才是真正使用的LBFGS,如果想在二分類時使用,需要自己參考LBFGSExample.scala呼叫。
值得注意的是
def setNumClasses(numClasses: Int): this.type = {
require(numClasses > 1)
numOfLinearPredictor = numClasses - 1
if (numClasses > 2) {
optimizer.setGradient(new LogisticGradient(numClasses))
}
this
} 可以看到這裡同時設定了numOfLinearPredictor,也就是預測器的個數,比class個數少一個,這種多分類方法是有pivot class的,也就是優化時只需要優化k-1個係數,預設class 0的margin是0,對應演算法中
3.2. LogisticRegressionModel
都是設定其中的諸如weight,threshold等屬性的,比較簡單,這裡介紹predict函式,看是怎樣分類的,以便其他環境中自己實現分類函式
override protected def predictPoint(
//樣本特徵向量
dataMatrix: Vector,
//weight
weightMatrix: Vector,
//截距
intercept: Double) = {
require(dataMatrix.size == numFeatures)
// If dataMatrix and weightMatrix have the same dimension, it's binary logistic regression.
if (numClasses == 2) {
val margin = dot(weightMatrix, dataMatrix) + intercept
val score = 1.0 / (1.0 + math.exp(-margin))
threshold match {
//分類
case Some(t) => if (score > t) 1.0 else 0.0
//迴歸
case None => score
}
} else {
/**
* Compute and find the one with maximum margins. If the maxMargin is negative, then the
* prediction result will be the first class.
*
* PS, if you want to compute the probabilities for each outcome instead of the outcome
* with maximum probability, remember to subtract the maxMargin from margins if maxMargin
* is positive to prevent overflow.
*/
var bestClass = 0
var maxMargin = 0.0
val withBias = dataMatrix.size + 1 == dataWithBiasSize
(0 until numClasses - 1).foreach { i =>
var margin = 0.0
dataMatrix.foreachActive { (index, value) =>
if (value != 0.0) margin += value * weightsArray((i * dataWithBiasSize) + index)
}
// Intercept is required to be added into margin.
if (withBias) {
margin += weightsArray((i * dataWithBiasSize) + dataMatrix.size)
}
if (margin > maxMargin) {
maxMargin = margin
bestClass = i + 1
}
}
bestClass.toDouble
}
}從程式碼可以看到,多分類預測的過程就是分別將樣本的特徵向量於訓練得到的各個分類的weight相乘,取最大的值對應的label。需要注意的是weights向量裡連續存著1到numClasses-1分類的weight,從margin的計算就可以看出來。
3.3. LogisticGradient
邏輯迴歸的演算法前面有簡要介紹,這裡主要是要計算其剃度和loss,程式碼這裡定義
當有margin大於0,定義
同時後面需要加m。所有margin都小於0,則
同時後面也不需要加m
/**
* For Multinomial Logistic Regression.
*/
val weightsArray = weights match {
case dv: DenseVector => dv.values
case _ =>
throw new IllegalArgumentException(
s"weights only supports dense vector but got type ${weights.getClass}.")
}
val cumGradientArray = cumGradient match {
case dv: DenseVector => dv.values
case _ =>
throw new IllegalArgumentException(
s"cumGradient only supports dense vector but got type ${cumGradient.getClass}.")
}
// marginY is margins(label - 1) in the formula.
var marginY = 0.0
var maxMargin = Double.NegativeInfinity
var maxMarginIndex = 0
val margins = Array.tabulate(numClasses - 1) { i =>
var margin = 0.0
data.foreachActive { (index, value) =>
if (value != 0.0) margin += value * weightsArray((i * dataSize) + index)
}
//第一項
if (i == label.toInt - 1) marginY = margin
if (margin > maxMargin) {
maxMargin = margin
maxMarginIndex = i
}
margin
}
/**
* When maxMargin > 0, the original formula will cause overflow as we discuss
* in the previous comment.
* We address this by subtracting maxMargin from all the margins, so it's guaranteed
* that all of the new margins will be smaller than zero to prevent arithmetic overflow.
*/
val sum = {
var temp = 0.0
if (maxMargin > 0) {
//大於0時候的處理
for (i <- 0 until numClasses - 1) {
margins(i) -= maxMargin
if (i == maxMarginIndex) {
temp += math.exp(-maxMargin)
} else {
temp += math.exp(margins(i))
}
}
} else {
//不會溢位,不需要處理
for (i <- 0 until numClasses - 1) {
temp += math.exp(margins(i))
}
}
temp
}
for (i <- 0 until numClasses - 1) {
val multiplier = math.exp(margins(i)) / (sum + 1.0) - {
if (label != 0.0 && label == i + 1) 1.0 else 0.0
}
data.foreachActive { (index, value) =>
if (value != 0.0) cumGradientArray(i * dataSize + index) += multiplier * value
}
}
//非0的時候,alpha=0,第一項有值
val loss = if (label > 0.0) math.log1p(sum) - marginY else math.log1p(sum)
if (maxMargin > 0) {
//大於0,最後要加上m
loss + maxMargin
} else {
loss
}3.4. SquaredL2Updater
L2正則化,我們之前介紹過,這裡不再贅述,值得注意的是,正則化時需要更新優化物件weight,compute函式第一項正是更新過的weight。
4. 訓練
訓練主要在breeze包中的LBFGS.scala和其父類FirstOrderMinimizer的一些函式中
4.1. weight初始化
/**
* Generate the initial weights when the user does not supply them
*/
protected def generateInitialWeights(input: RDD[LabeledPoint]): Vector = {
if (numFeatures < 0) {
numFeatures = input.map(_.features.size).first()
}
/**
* When `numOfLinearPredictor > 1`, the intercepts are encapsulated into weights,
* so the `weights` will include the intercepts. When `numOfLinearPredictor == 1`,
* the intercept will be stored as separated value in `GeneralizedLinearModel`.
* This will result in different behaviors since when `numOfLinearPredictor == 1`,
* users have no way to set the initial intercept, while in the other case, users
* can set the intercepts as part of weights.
*
* TODO: See if we can deprecate `intercept` in `GeneralizedLinearModel`, and always
* have the intercept as part of weights to have consistent design.
*/
if (numOfLinearPredictor == 1) {
Vectors.zeros(numFeatures)
} else if (addIntercept) {
Vectors.zeros((numFeatures + 1) * numOfLinearPredictor)
} else {
Vectors.zeros(numFeatures * numOfLinearPredictor)
}
}根據二/多分類,是否有截距,初始化weight向量,多分類時,多個weight向量是連續存放在一個vector結構裡的,有過有截距,相當於每個weight多加了一維。
4.2. 樣本資料check
主要是檢查樣本label的範圍
/**
* Function to check if labels used for k class multi-label classification are
* in the range of {0, 1, ..., k - 1}.
*
* @return True if labels are all in the range of {0, 1, ..., k-1}, false otherwise.
*/
@Since("1.3.0")
def multiLabelValidator(k: Int): RDD[LabeledPoint] => Boolean = { data =>
val numInvalid = data.filter(x =>
x.label - x.label.toInt != 0.0 || x.label < 0 || x.label > k - 1).count()
if (numInvalid != 0) {
logError("Classification labels should be in {0 to " + (k - 1) + "}. " +
"Found " + numInvalid + " invalid labels")
}
numInvalid == 0
}4.3. scaling
對樣本特徵值的範圍進行縮放,加快收斂速度,但是這裡僅僅對特徵值除以標準差,沒有做真正的歸一化。
val scaler = if (useFeatureScaling) {
new StandardScaler(withStd = true, withMean = false).fit(input.map(_.features))
} else {
null
}
// Prepend an extra variable consisting of all 1.0's for the intercept.
// TODO: Apply feature scaling to the weight vector instead of input data.
val data =
if (addIntercept) {
if (useFeatureScaling) {
input.map(lp => (lp.label, appendBias(scaler.transform(lp.features)))).cache()
} else {
input.map(lp => (lp.label, appendBias(lp.features))).cache()
}
} else {
if (useFeatureScaling) {
input.map(lp => (lp.label, scaler.transform(lp.features))).cache()
} else {
input.map(lp => (lp.label, lp.features))
}
}這段程式碼同時對有截距的情況進行了處理,因為我們之前把截距當成額外的一維放在了weight向量裡,這裡對樣本特徵也對應增加以為,且特徵值全部設定成1,就可以把截距也當成特徵統一處理了。
相關推薦
spark mllib原始碼分析之L-BFGS(一)
1. 使用 spark給出的example中涉及到LBFGS有兩個,分別是LBFGSExample.scala和LogisticRegressionWithLBFGSExample.scala,第一個是直接使用LBFGS直接訓練,需要指定一系列優化引數,優
Android4.4.2原始碼分析之WiFi模組(一)
已經寫了幾篇關於Android原始碼的,原始碼程式碼量太大,所以如果想分析某個模組可能不知如何下手,說一下思路 1,分析原始碼英文閱讀能力要夠,想要分析某個模組一般找模組對應的英文,就是模組 2,找到之後首先檢視清單配置檔案Androidmani.fest,找到程式主介面activity 3,通過檢視配置檔
spark mllib原始碼分析之隨機森林(Random Forest)(二)
4. 特徵處理 這部分主要在DecisionTree.scala的findSplitsBins函式,將所有特徵封裝成Split,然後裝箱Bin。首先對split和bin的結構進行說明 4.1. 資料結構 4.1.1. Split cl
spark mllib原始碼分析之隨機森林(Random Forest)(三)
6. 隨機森林訓練 6.1. 資料結構 6.1.1. Node 樹中的每個節點是一個Node結構 class Node @Since("1.2.0") ( @Since("1.0.0") val id: Int, @S
spark mllib原始碼分析之邏輯迴歸彈性網路ElasticNet(一)
spark在ml包中將邏輯迴歸封裝了下,同時在演算法中引入了L1和L2正則化,通過elasticNetParam來調節兩種正則化的係數,同時根據選擇的正則化,決定使用L-BFGS還是OWLQN優化,是謂Elastic Net。 1. 輔助類 我們首先介紹
spark mllib原始碼分析之二分類邏輯迴歸evaluation
在邏輯迴歸分類中,我們評價分類器好壞的主要指標有精準率(precision),召回率(recall),F-measure,AUC等,其中最常用的是AUC,它可以綜合評價分類器效能,其他的指標主要偏重一些方面。我們介紹下spark中實現的這些評價指標,便於使用sp
spark mllib原始碼分析之DecisionTree與GBDT
我們在前面的文章講過,在spark的實現中,樹模型的依賴鏈是GBDT-> Decision Tree-> Random Forest,前面介紹了最基礎的Random Forest的實現,在此基礎上我們介紹Decision Tree和GBDT的實現
雲客Drupal8原始碼分析之外掛系統(下)
以下內容僅是一個預覽,完整內容請見文尾: 至此本系列對外掛的介紹全部完成,涵蓋了系統外掛的所有知識 全文目錄(全文10476字): 例項化外掛 外掛對映Plugin mapping 外掛上下文
elasticsearch原始碼分析之分片分配(十)
分片 什麼是分片 分片是把索引資料切分成多個小的索引塊,這些小的索引塊能夠分發到同一個叢集中的不同節點。在檢索時,檢索結果是該索引每個分片上檢索結果的合併。類似於資料庫的分庫分表。 為什麼分片 1、這樣可以提高讀寫效能,實現負載均衡。 2、副本容易
elasticsearch原始碼分析之索引操作(九)
上節介紹了es的node啟動如何建立叢集服務的過程,這節在其基礎之上介紹es索引的基本操作功能(create、exist、delete),用來進一步細化es叢集是如果工作的。 客戶端部分的操作就不予介紹了,詳細可以參照elasticsearch原始碼分析之客戶
elasticsearch原始碼分析之服務端(四)
上篇部落格說明了客戶端的情況,現在繼續分析服務端都幹了些啥,es是怎麼把資料插進去的,此處以transport的bulk為入口來探究,對於單個document的傳送就忽略了。 一、服務端接收 1.1接收訊息 在客戶端分析中已經提到,netty中通訊的處理類是Mes
elasticsearch原始碼分析之啟動過程(二)
最近開始廣泛的使用elasticsearch,也開始寫一些java程式碼了,為了提高java程式碼能力,也為了更加深入一點了解elasticsearch的內部運作機制,所以開始看一些elasticsearch的原始碼了。對於這種廣受追捧的開源專案,細細品讀一定會受益匪淺,
Vue原始碼分析之依賴收集(九)
依賴收集就是訂閱資料變化watcher的收集,依賴收集的目的是當響應式資料發生變化時,能夠通知相應的訂閱者去處理相關的邏輯。在上一章,介紹了Vue將普通物件變成響應式物件是利用defineReactive()(定義在'core/observer/index.js'中)函式,d
雲客Drupal8原始碼分析之實體Entity(二)配置實體基類
配置實體基類是系統定義的一個用於配置實體的抽象基類,繼承自實體基類,完成了配置實體的大部分通用功能,具體的配置實體往往會繼承它,比如使用者角色實體,這樣寫少量程式碼即可,類定義如下: Drupal\Core\Config\Entity\ConfigEntityBase 實
雲客Drupal8原始碼分析之實體Entity(五)內容實體基類
原始碼分析重點在於在自己的大腦中重現開發者的思維過程,內容實體基類是drupal中很大的一個類,她要處理眾多的問題,內容實體的大多數功能都集中在這裡,開發者有許多的考慮,要弄清楚她的所有細節,學習者可能會覺得有些困難,這時需要明白任何複雜龐大的事物都是一步步累積發展起來的,
雲客Drupal8原始碼分析之外掛系統(上)
各位《雲客drupal8原始碼分析》系列的讀者: 本系列一直以每週一篇的速度進行部落格原創更新,希望幫助大家理解drupal8底層原理,並縮短學習時間,但自《外掛系統(上)》主題開始部落格僅釋出前言和目錄,這是因為雲客在思考一個問題:drupal在國外如此流行但在國內卻很小
Android4.4.2原始碼分析之WiFi模組(二)
接著上一篇繼續對WiFi原始碼的分析 onResume方法中 6>,首先是呼叫WiFiEnabler的resume方法對switch進行管理 接下來註冊廣播 getActivity().registerReceiver(mReceiver, mFilter);
Memcached原始碼分析之訊息迴應(3)
文章列表: 《Memcached原始碼分析 - Memcached原始碼分析之總結篇(8)》 前言 上一章《Memcached原始碼分析 - Memcached原始碼分析之命令解析(2)》,我們花了很大的力氣去講解Memcached如何從客戶端讀取命令,並且
精盡 MyBatis 原始碼分析 - MyBatis 初始化(一)之載入 mybatis-config.xml
> 該系列文件是本人在學習 Mybatis 的原始碼過程中總結下來的,可能對讀者不太友好,請結合我的原始碼註釋([Mybatis原始碼分析 GitHub 地址](https://github.com/liu844869663/mybatis-3)、[Mybatis-Spring 原始碼分析 GitHub 地址
精盡MyBatis原始碼分析 - SQL執行過程(一)之 Executor
> 該系列文件是本人在學習 Mybatis 的原始碼過程中總結下來的,可能對讀者不太友好,請結合我的原始碼註釋([Mybatis原始碼分析 GitHub 地址](https://github.com/liu844869663/mybatis-3)、[Mybatis-Spring 原始碼分析 GitHub 地址