
Hadoop筆記之二:執行WordCount實驗
實驗環境
Hadoop版本:Hadoop2.7.3
linux版本:Ubuntu
JDK版本:JDK1.7
實驗步驟
- 設定HADOOP的PATH和HADOOP CLASSPATH(這裡假設java的相關路徑已經配置好)
export HADOOP_HOME=/home/luchi/Hadoop/hadoop-2.7.3
export PATH=${HADOOP_HOME}/bin:$PATH
export HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar- 編輯CountWord.java檔案
import java.io.IOException - 編譯WordCount.java
注意這裡使用的是Hadoop下面的javac進行編譯的:
首先轉到WordCount.java所在的目錄(如果沒有轉到該子目錄,使用路徑名的話,那麼也就相當於編譯一個java包,這裡需要在上面的程式碼上加上相應的包名)
$ hadoop com.sun.tools.javac.Main WordCount.java使用這個命令之後,會生成三個檔案:
WordCount
WordCount.class
第一個和第二個其實是WordCount類的兩個子靜態類,中間用$表示隸屬關係
4. 將.class檔案打包成jar包
jar cf wc.jar WordCount*.class注意,這裡用的是JDK1.7的jar命令,區別於後文的hadoop jar命令
5. 在HDFS檔案系統上建立input目錄,作為輸入檔案目錄
我是在/user目錄下建立了一個input子目錄,下面有兩個檔案file1和file2:
luchi@ubuntu:~/Desktop$ hdfs dfs -ls /user/input
Found 2 items
-rw-r--r-- 1 luchi supergroup 68 2016-10-16 09:40 /user/input/file1
-rw-r--r-- 1 luchi supergroup 15 2016-10-16 09:40 /user/input/file2
file1和file2的檔案是:
luchi@ubuntu:~/Desktop$ hdfs dfs -cat /user/input/file1 /user/input/file2
i have a dream
that everyone should chase his dream
and be honest
this is cat 2
注意:這裡不需要建立output目錄,因為在執行完map-reduce工作之後,會自動生成該目錄
6. 執行map-reduce工作
hadoop jar wc.jar WordCount /user/input /user/output需要注意的是,如果WordCount有包名,那麼需要在上述命令裡面的WordCount前面加上包名
執行成功的顯示如下:
16/10/16 10:45:53 INFO mapreduce.Job: Job job_local98859034_0001 completed successfully
16/10/16 10:45:53 INFO mapreduce.Job: Counters: 35
File System Counters
FILE: Number of bytes read=10886
FILE: Number of bytes written=850552
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=234
HDFS: Number of bytes written=106
HDFS: Number of read operations=22
HDFS: Number of large read operations=0
HDFS: Number of write operations=5
Map-Reduce Framework
Map input records=4
Map output records=17
Map output bytes=148
Map output materialized bytes=182
Input split bytes=206
Combine input records=17
Combine output records=16
Reduce input groups=16
Reduce shuffle bytes=182
Reduce input records=16
Reduce output records=16
Spilled Records=32
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=105
Total committed heap usage (bytes)=455553024
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=83
File Output Format Counters
Bytes Written=106
從上面的程式碼可以看出,了4個map輸入,產生了17個map輸出,17個combine輸入產生了16個combine輸出,16個reduce輸入產生了16個reduce輸出。注意這裡的map輸入和map輸出以及reduce輸入和reduce輸出指的並不是map和reduce的個數,實際上,FileInputFormat是一個基類,如果不加指定的話,預設的是TextInputFormat,是根據input目錄下的檔案數來確定map的個數的(對於檔案小於block size的情況,對於檔案大小大於block的情況則要再分割槽),這裡的input資料夾下面有兩個檔案,因此,這個任務的job的map個數為2,另一方面,這個hadoop環境是偽分散式的,因此其reduce的個數是1。
- 看一眼我們的輸出結果檔案:
luchi@ubuntu:~/Desktop$ hdfs dfs -cat /user/output/part-r-00000
2 1
a 1
and 1
be 1
cat 1
chase 1
dream 2
everyone 1
have 1
his 1
honest 1
i 1
is 1
should 1
that 1
this 1
可以看出,詞頻已經統計完畢了。
程式碼和結果分析
說明:這是一個HADOOP新手的理解,可能有些地方不對,不對的地方還請指正。
詳細的API呼叫不準備說了,看官方文件即可,因為剛開始學HADOOP,所以還是想把程式碼執行的經過說下。
程式碼中TokenizerMapper繼承了Mapper這個父類,Mapper這個類是用來進行map操作的,以輸入文字為例,程式碼:
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));這兩句指定了輸入與輸出的路徑,本例子中指定的路徑是、user/input,接受到這個輸入之後,Map-Reduce框架會首先將文字分塊,然後每塊對應一個map,這裡用了4個map輸入(指的是有四行文字),每個map是以鍵值對對應的,key為文字索引位置,value為一行文字的文字,以下面為例(僅僅是示例,沒有實際意義):
(0,"i have")
(24,"dream")然後每個map的每個項輸入會送入Mapper類,進行map操作,這裡使用的是TokenizerMapper這個Mapper子類進行操作。在本例中:
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}TokenizerMapper的作用是,將每個map傳來的輸入(鍵值對)進行處理,我們對傳進來的傳進來的鍵值對的key並不關心,只有value有作用,上面程式碼的map方法前兩個引數就是這個意思,我們需要對value進行分詞處理,這裡使用的StringTokenizer這個類進行處理,分詞之後,按照(單詞,詞頻)的鍵值對儲存在context中,並作為輸出的map,這也是為什麼2個map輸入會用多個輸出map
在這之後,程式碼中使用了combine操作,其實combine操作買就是區域性的reduce,因為在map和reduce之間傳遞需要頻寬,因此combine先是把本地的輸出map進行了區域性的reduce,比如說,一個map的輸出是:
(dream,1)
(dream,1)
經過combine之後的輸出是(dream,2),這就減少了傳輸資料量,減少了頻寬的壓力。
之後就是reduce操作,當然在reduce之前還是有sort和shuffle過程,shuffle就是把相似的mapper對映到一個reduce塊中。本例中reduce是使用IntSumReducer這個類實現的,IntSumReducer繼承了Reducer這個父類,和這點Mapper一樣。
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}這裡的reduce方法和之前的map方法還是有差別的,reduce接受的輸入是key一致的,而值的大小不一樣的輸入,在本例中,key就是word,而values就是該詞的詞頻列表,我們將其相加就得到了這個詞的詞頻。該程式整體的框架如下圖:
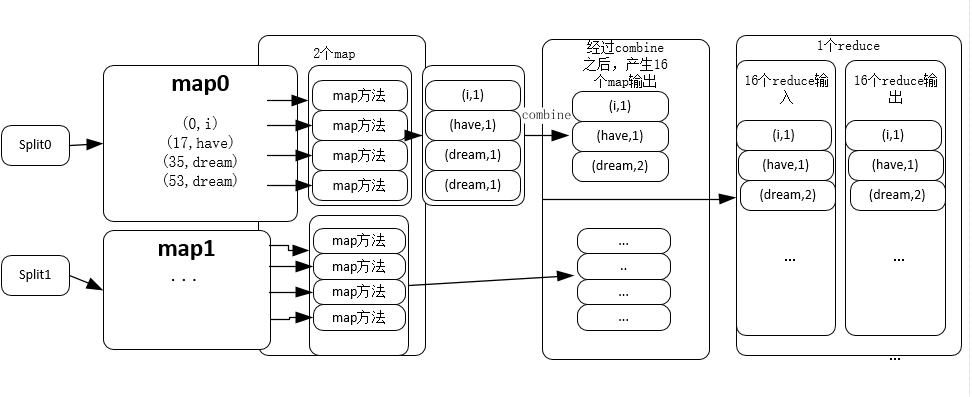
在使用了map方法之後, 本例之中是指TokenizerMapper的map方法,得到17個map,本例子只有兩個相同的詞就是dream,經過combine之後,將兩個(dream,1)合併為(combine,2),得到16個map實際輸出,然後這16個輸出map經過shuffle和sort送入reduce過程,此時沒有單詞需要reduce,因為在combine過程中已經將完全一樣的詞dream合併過了,所以16個reduce輸入得到16個reduce輸出,然後就得到了結果。
總結
程式碼執行起來也容易,但是還是有些細節需要探究的,根據這個實驗,我粗略的瞭解了map-reduce的整個過程,當然可能存在一些不當之處,還是需要今後多多學習來補充,歡迎指正。
參考資料:《Hadoop權威指南》
相關推薦
Hadoop筆記之二:執行WordCount實驗
實驗環境 Hadoop版本:Hadoop2.7.3 linux版本:Ubuntu JDK版本:JDK1.7 實驗步驟 設定HADOOP的PATH和HADOOP CLASSPATH(這裡假設java的相關路徑已經配置好) export HA
Modbus庫開發筆記之二:Modbus消息幀的生成
不同的 command dwr 分別是 slave 識別碼 align 數據格式 .com 前面我們已經對Modbus的基本事務作了說明,也據此設計了我們將要實現的主從站的操作流程。這其中與Modbus直接相關的就是Modbus消息幀的生成。Modbus消息幀也是實現Mod
Linux運維學習筆記之二:常用命令2
linux 運維 筆記71、passwd:修改用戶密碼語法passwd [參數]username選項-k --keep-tokens :保留即將過期的用戶在期滿後仍能使用-l --lock :鎖定用戶無權更改其密碼,只能root才能操作-u --unlock :解除鎖定-S --status :查看用戶狀
《逐夢旅程:Windows遊戲編程之從零開始》學習筆記之二:GDI框架
register 開發 操作 程序 turn use 繪制 cal 完整 1 //===========================================【程序說明】=================================== 2 //
C語言學習及應用筆記之二:C語言static關鍵字及其使用
static關鍵字 可能 語言 需要 c語言 UNC function 不必要 能夠 C語言有很多關鍵字,大多關鍵字使用起來是很明確的,但有一些關鍵字卻要相對復雜一些。我們這裏要說明的static關鍵字就是如此,它的功能很強大,相應的使用也就更復雜。 一般來說sta
Memcached學習筆記之二:入門使用
使用 現在伺服器已經正常運行了,下面我們就來寫java的客戶端連線程式。 將java_memcached-release.zip解壓,把java_memcached-release.jar檔案複製到java專案的lib目錄下, 然後我們來編寫程式碼,比如我提供的一個應用類如下: &n
Effective C++筆記之二:儘量以const、enum、inline替換#define
一.#define定義的類似函式的巨集,使用時易出錯 缺點描述 這樣做的初衷是,巨集看起來像函式,但不會招致函式呼叫(function call)帶來的額外開銷。但即使你為所有實參加上小括,仍然會在使用時遭遇麻煩。舉個例子: // 求兩個變數中最大的那個 #define THE_MAX(a, b)
hive程式設計指南學習筆記之二:hive資料庫及其中的表查詢
show databases; /*
SpringSecurity學習筆記之二:SpringSecurity結構及基本配置
Spring Security3.2分為11個模組,如下表所示: Spring Security3.2引入了新的Java配置方案,完全不在需要通過XML來配置安全性功能。如下,展現了Spring Security最簡單的Java配置: @EnableWebSecurity
C++11併發學習之二:執行緒管理
1.啟動執行緒 (1)使用物件 “小試牛刀”中thread構造時傳入的是函式,還可以傳入物件。 #include <thread> #include <iostream> void func() { std::cout<<
多執行緒複習筆記之二【執行緒間的通訊】
Object.wait:釋放鎖,當時程式碼不會往下繼續執行,需要等待notify通知,wait(1000)超過1秒自動喚醒 Object.notify:不釋放鎖,需要等到同步程式碼塊執行完畢,如果沒有wait執行緒,notify命令將被忽略。 condition 如果有多個執行緒處於等待
資料庫筆記之二:關係資料庫
關係的定義: 關係是一個元數為k的元組集合,即這個關係有n個元組,每一個元組有k個屬性值。 關係的性質: 列時同質的,每一列的分量必須是同一型別的資料,來自同一個域。 不同列的值可以來自同一個域,關係中的列不可以同名,不同列的資料型別可以一樣; 列的順序隨意 任意兩個元組的候
Modbus協議棧開發筆記之二:Modbus訊息幀的生成
前面我們已經對Modbus的基本事務作了說明,也據此設計了我們將要實現的主從站的操作流程。這其中與Modbus直接相關的就是Modbus訊息幀的生成。Modbus訊息幀也是實現Modbus通訊協議的根本。 1、Modbus訊息幀分析 MODBUS協議在不同的物理鏈路上的訊息幀有一些差異,
DirectX 9 UI設計學習筆記之二:第2章Introducing DirectX+第3章Introducing Direct3D
此文由哈利_蜘蛛俠原創,轉載請註明出處!有問題歡迎聯絡本人! 上一期的地址: 別看這一期似乎要講很多內容,其實大部分是一帶而過的。其實我的重點在於弄了一個框架程式;詳情見本期最後。 第2章 Introducing DirectX ===
spark學習筆記之二:寬依賴和窄依賴
1.如果父RDD裡的一個partition只去向一個子RDD裡的partition為窄依賴,否則為寬依賴(只要是shuffle操作)。 2.spark根據運算元判斷寬窄依賴: 窄依賴:map
博科SAN交換機學習筆記之二:配置檔案備份與韌體升級 作者 LiaoJL | 轉載時請務必以超連結形式標明文章原文連結和作者資訊及本版權宣告。 原文連結:http://www.liaojl.co
配置檔案恢復 當需要備份中恢復交換機配置時,可以通過configdownload命令將博科交換機的配置從遠端伺服器恢復到交換機。博科交換機支援將舊版本的配置檔案匯入新版本韌體的交換機,例如將v6.2.0的配置檔案匯入v6.3.0韌體版本的交換機,或者將v6.4.1 配置檔案匯入 v7.0.0 版本的交換機。
Redis學習筆記之二:Redis的資料儲存結構
Redis與Mysql等關係型資料庫的第一點區別就是Redis的資料儲存結構,Mysql等關係型資料庫以表的形式存放資料,而Redis提供Key-Value形式的儲存格式。與Mysql等資料庫的第二
吳恩達機器學習 學習筆記 之 二 :代價函式和梯度下降演算法
二、 2-1 Model Representation 我們學習的第一個演算法是線性迴歸,接下來會講什麼樣的模型更重要,監督學習的過程是什麼樣子。 首先舉一個需要做預測的例子:住房價格上漲,預測房價,我們擁有某一城市的住房價格資料。基於這些資料,繪製圖形。 在已有房價資
Java Web 學習筆記之二:Java HttpURLConnection保持會話的方法
在Java Web開發中,會話保持是伺服器識別客戶端(一般指瀏覽器)的方式。對此,各大瀏覽器都是支援會話保持的。然而在開發者通過Java API HttpURLConnection 開發網路請求工具的
f2fs study 筆記之二: SSA揭秘
筆記 dentry pac amp mat one += reg pos node inode node: used to locate block;inode: upper lawyer logical entity (file/directory) block ?和f