
關於Hadoop分散式計算:多個Map分佈在不同節點上執行
1 背景&問題
學習Hadoop已經快一年了,也是似懂非懂的樣子。由於專案的原因,再次啟動Hadoop,一直以為這個很簡單就能夠實現多個機器一起完成一個任務,其實並不然。在實驗過程中,發現Map的數量並不能通過設定“mapreduce.job.maps"來改變,這方面的資料也有很多。而且最大問題是,只有當輸入檔案分塊達到8時才會出現7個分佈在一個節點上,另外一個分佈在另一個節點上。這個是與資源申請有關“Containers”(具體可以參考牛人“董的部落格”),每個節點最多能容納8個Containers(可以通過web檢視),大致解釋是一個Job對應一個Containers,然後每個Map也是。但是輸入檔案分塊多,導致map數量變多,這樣消耗的時間會更多。怎麼才能做到多個Map比較均勻分佈在不同的機器上呢?
2 解決過程
第一章中,已經描述了,只有分塊很多時,才能分佈在不同節點上,但這並不是有效的方法。於是抱著嘗試的心態“如果有多個Job呢,每個Job分成3個Map(用3個輸入檔案),能不能達到並行的效果”。今天,做了幾個實驗,猜對了,比如:6000條記錄放在一個文本里,只有一個Map執行;如果將6000行紀錄分割成6部分,兩個Job分別處理3個小檔案。同時執行這兩任務,第一個測試耗時:10185s,第二個測試耗時:7572s。下圖是將6000條記錄分成3個Job每個Job對應4個小檔案(當作四個splits),執行3個Job任務如下:
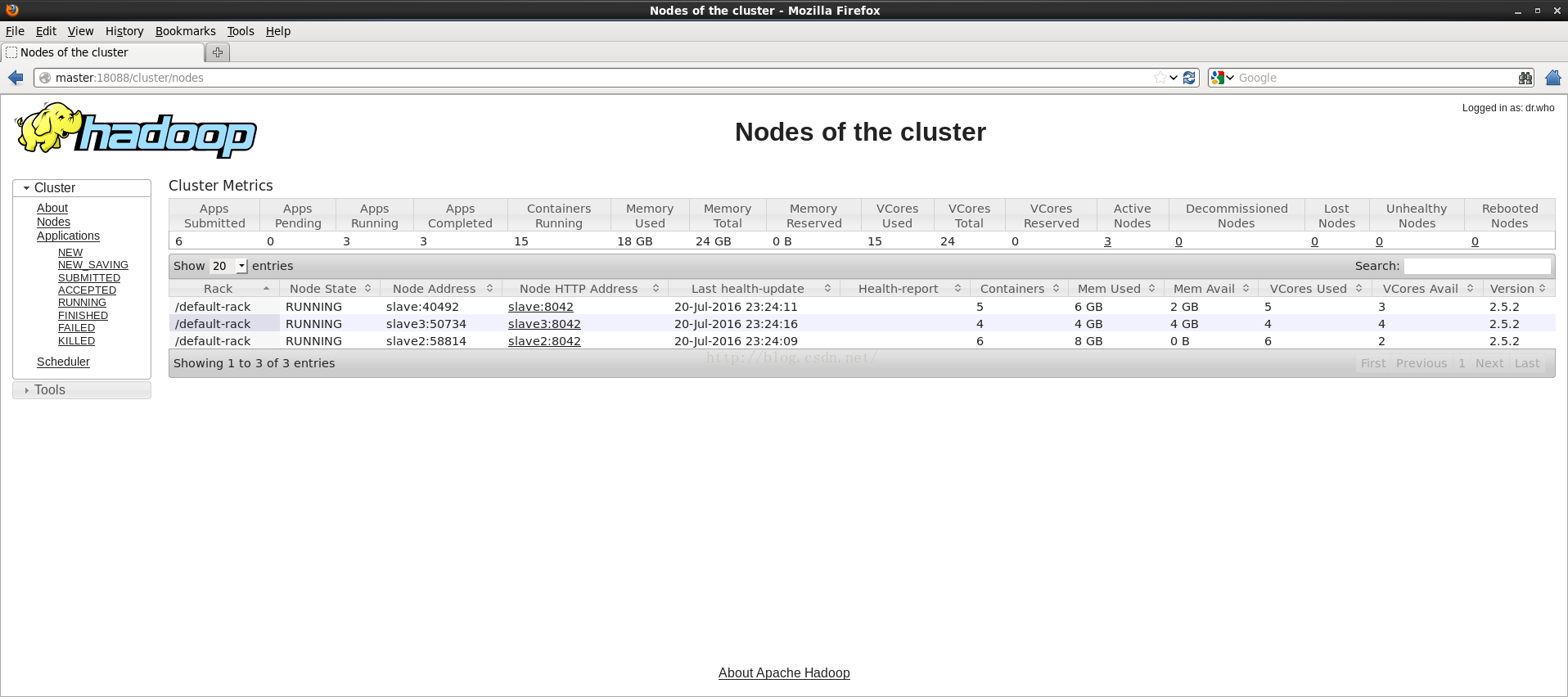
每個節點上均分配了4個Map任務,另外3個是ApplicationMaster,這裡不討論。
2.1 201610
發現上述方法治標不治本,於是又查詢資料,只需修改yarn-site.xml配置檔案即可,關於這些引數說明,網上資源還是很多,這裡先不多說了,後續。
一個節點上執行的任務數目主要由兩個因素決定,一個是NodeManager可使用的資源總量,一個是單個任務的資源需求量,比如一個NodeManager上可用資源為8 GB記憶體,8 cpu,單個任務資源需求量為1 GB記憶體,1cpu,則該節點最多執行8個任務。NodeManager上可用資源是由管理員在配置檔案yarn-site.xml中配置的,相關引數如下:<property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>256<alue> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>4096</value> </property>
yarn.nodemanager.resource.memory-mb:總的可用實體記憶體量,預設是8096
yarn.nodemanager.resource.cpu-vcores:總的可用CPU數目,預設是8 對於任務的相關引數如下:
yarn.scheduler.minimum-allocation-mb:最小可申請記憶體量,預設是1024
yarn.scheduler.minimum-allocation-vcores:最小可申請CPU數,預設是1
yarn.scheduler.maximum-allocation-mb:最大可申請記憶體量,預設是8096
yarn.scheduler.maximum-allocation-vcores:最大可申請CPU數,預設是4
3 總結
後面繼續把資料量增多,感覺這樣做還可以。因為網上談這方面基本沒有,所以先把思路紀錄下來,後面再把實驗進行視覺化,進一步證明這樣做的可行性。