JMeter-後置處理器
阿新 • • 發佈:2019-01-22
後置處理器
在Sampler執行後執行。
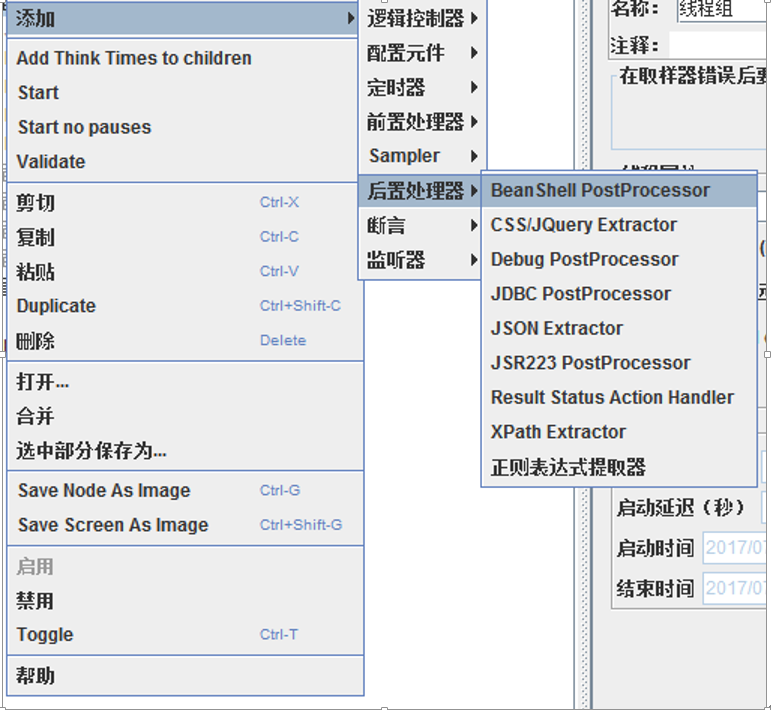
建議都新增後置處理器作為一個sampler的子元件(確保是作用於你需要的那個sampler,不然,他會作用與他同級的所有sampler),比如.

1. BeanShell PostProcessor
語法與BeanShell Sampler一樣,但注意可用的變數有不同的
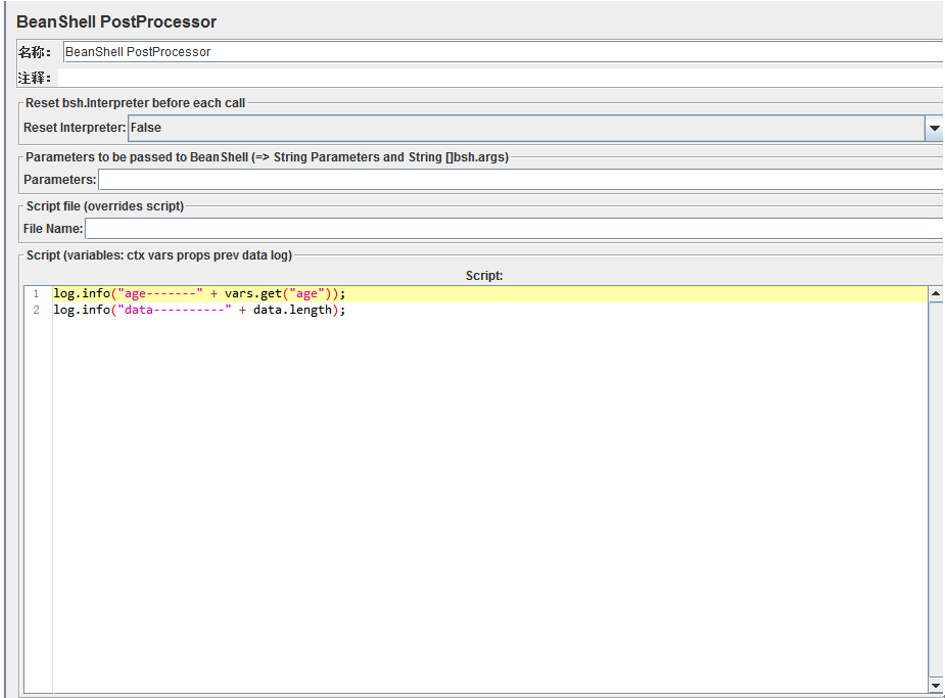
結果:
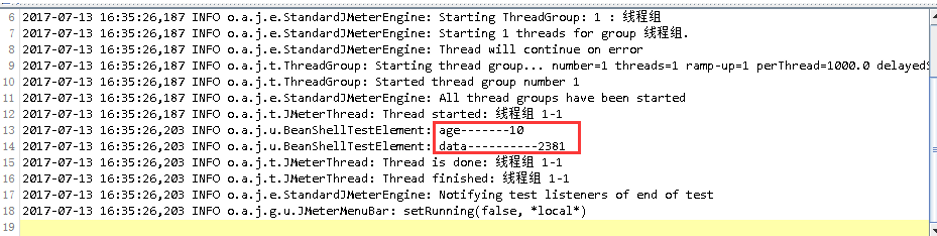
- vars:操作Jmeter變數
a) vars.get(“name”):從jmeter中獲得變數值
b) vars.put(“key”,”value”):儲存資料到jmeter變數中,如果變數不存在會自動建立 - props: 操作Jmeter屬性
a) props.get(“START.HMS”); 注:START.HMS為屬性名
b) props.put(“PROP1”,”1234”); 儲存資料到Jmeter屬性中,如果屬性不存在會自動建立 - data: (byte [])- 使用者訪問當前請求的資料 (byte陣列,不知道什麼場景下有用呢。。)
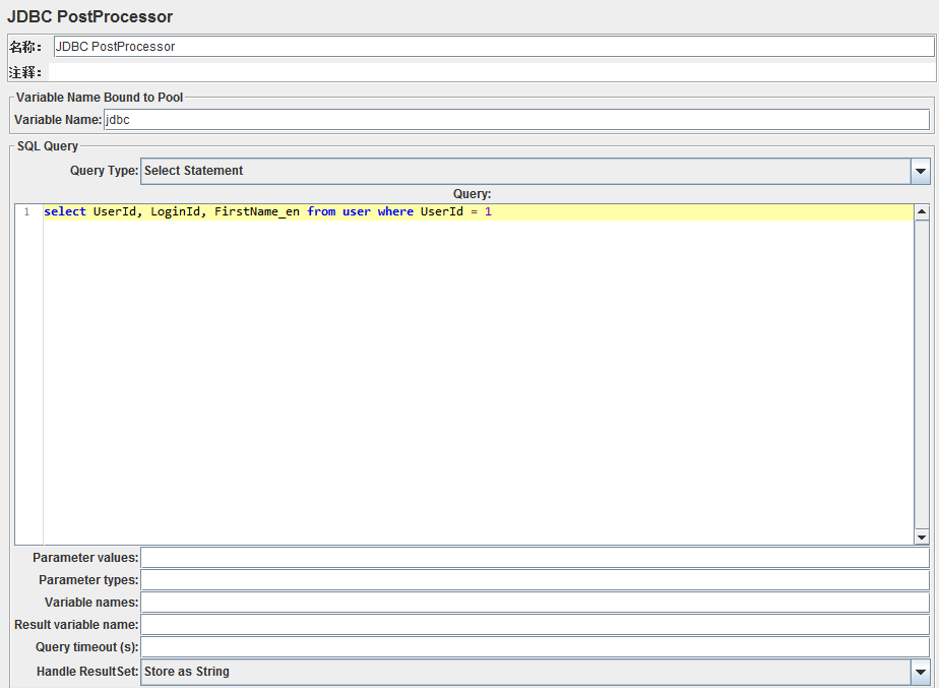
2. JDBC PostProcessor
在請求執行之後進行資料庫操作。
使用方法與JDBC Request 是一樣的。
應用場景,比如在建立使用者,需要知道儲存在資料庫中的使用者資訊,可以使用JDBC PreProcessor進行查詢
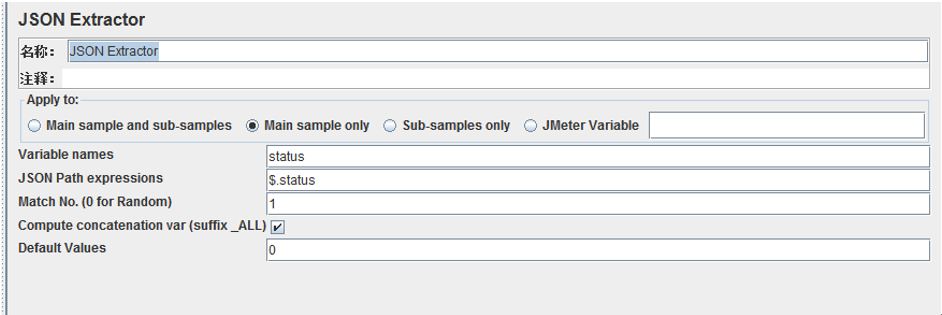
3. JSON Extractor
| 屬性 | 描述 | 備註 |
|---|---|---|
| Variable Names | 變數名 | |
| JSON Path Expressions | Json提取表示式 | |
| Match No. (0 for Random) | 當提取有多個結果值時,選擇需要的值儲存到變數中,預設值為0 0:隨機一個 -1:全部值,使用_N 方式儲存(N從1開始),比如status_1,status_2… X: 自然數,比如1,返回第X個值(如果X大於返回值的數量,結果會不能獲取,最終返回設定的預設值) |
|
| Compute concatenation var | 如果有匹配到多個值,選擇此項,會將全部值儲存到_ALL,並使用逗號分割每個值 | 注意Match No. (0 for Random)需要為-1才有效,不然只能匹配到一個值了 |
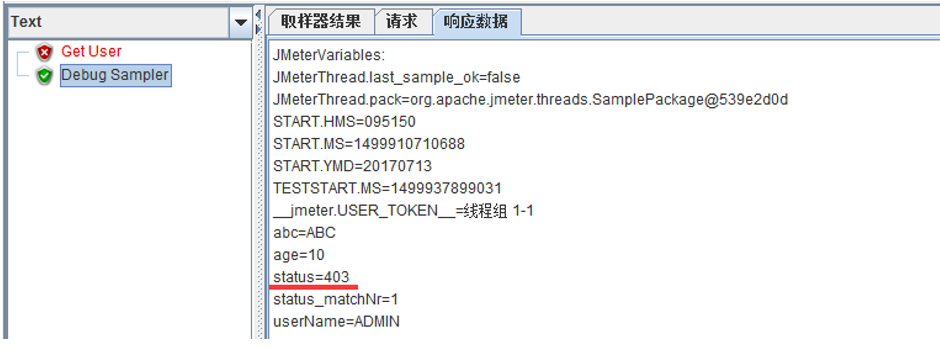
比如一個獲取使用者資訊請求,請求失敗返回為json,需要提取status值

JSON Extractor:
結果:
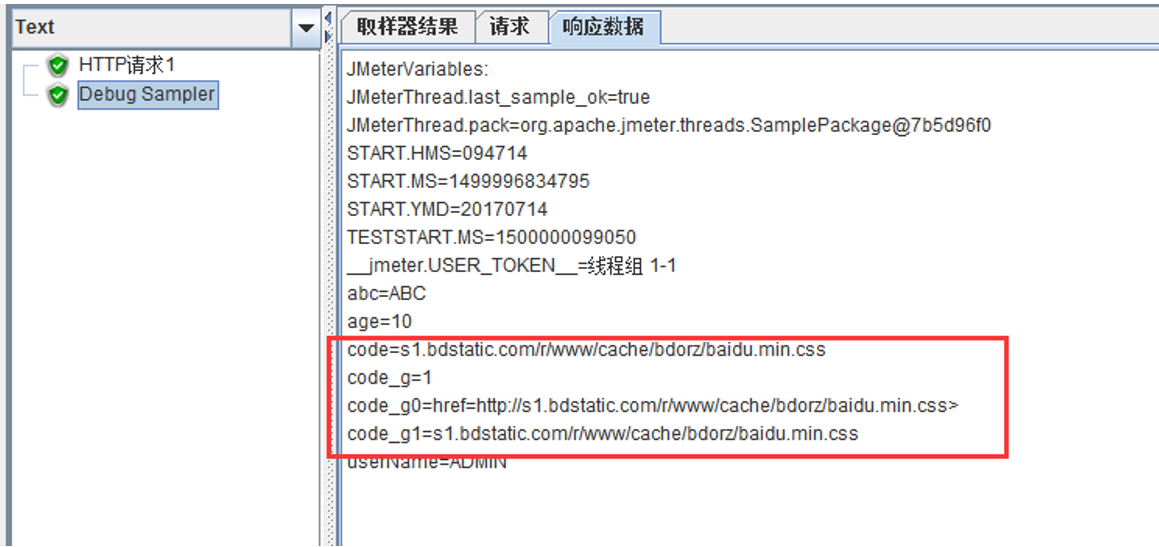
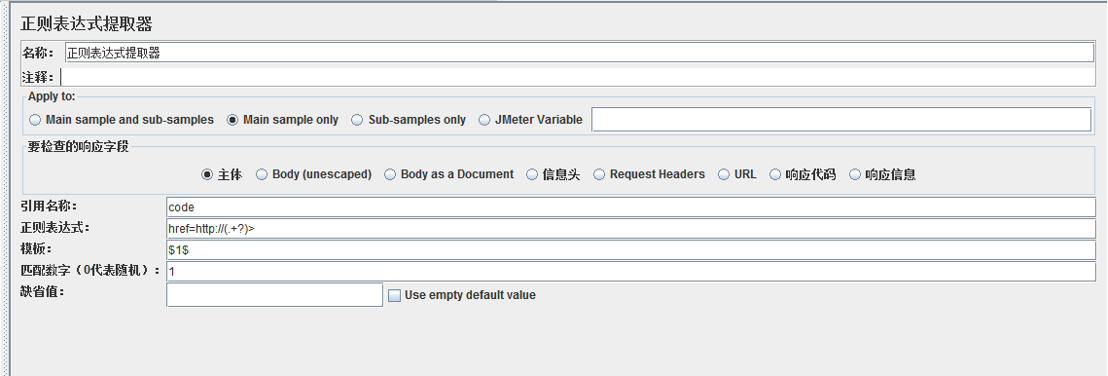
4. 正則表示式提取器
使用正則表示式提取請求中的內容。
| 屬性 | 描述 | 備註 |
|---|---|---|
| Apply to | Sampler可能會產生子Sampler,這裡需要選擇從哪個Sampler中進行提取 | |
| 要檢查的響應欄位 | 指要從請求的哪部分內容中進行提取 主體:請求的響應資料 Body (unescaped):請求的響應資料,html程式碼不會被轉義 Body as a Document: 資訊頭:指響應頭 Request Headers:請求頭 URL: 請求地址 響應程式碼:e.g 200 |
響應資訊:e.g OK 感覺這些中文翻譯有點繞。。可以從下面的註解截圖中瞭解下 |
| 引用名稱 | 用來儲存提取結果的。同時還會生成一組變數,[引用名稱]_g#: [引用名稱]_g:表示式提取的次數(指表示式中”()”的數量) [引用名稱]_g0:表示式匹配到的完整字串 [引用名稱]_g1:表示式中第1個“()”提取到的值 [引用名稱]_g2:表示式中第2個“()”提取到的值 。。。 |
如果表示式匹配到多個字串,最終引用名稱生成的變數會變成 [引用名稱]_N_g#, N表示匹配的字串順序 |
| 正則表示式 | 正則表示式,最少要包括一個“()”, 括號裡面的表示要提取的內容 | 比如:aaa(.+?)ccc, 可以提取到aaabbbcc中的 “bbb”. (.+?)是一個很常用的表示式, .表示任意一個字元 +表示重複一次或多次 ?表示匹配0次或一次 更多的的介紹可以看下:正則表示式 |
| 模板 | 說明要獲取哪個提取式的內容,比如 ’$1$’: 獲取第1組的內容(指第一個“()”中提取到的值) ’$2$’: 獲取第2組的內容 。。。 $0$ :表示獲取整個表示式匹配的內容(就是[引用名稱]_g0 的值) |
|
| 匹數數字 | 表示式可能會匹配多個字串,匹數數字說明要獲取第幾個匹配值 0:表示隨機一個 N:表示第N個 -1:表示全部(負數都是一樣的) |
如果填寫了負數,最終引用名稱必然會加上序號,比如[引用名稱]_1, 使用的時候要注意 |
| 預設值 | 表示式匹配不到字串時,儲存到引用名稱中的值 | 預設值,可以為空的 |
注:
要檢查的響應欄位:
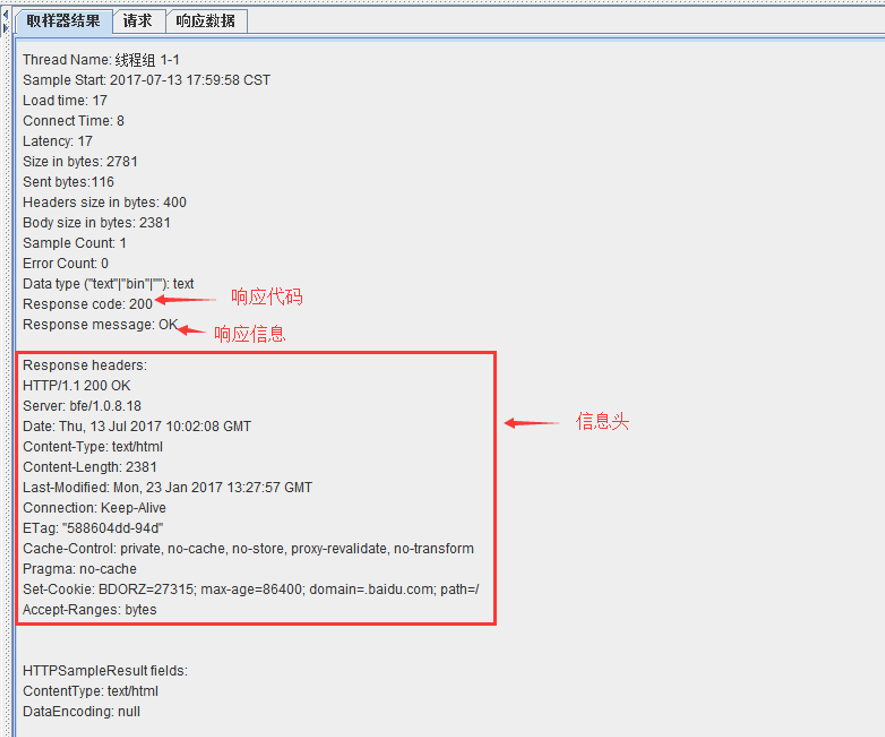
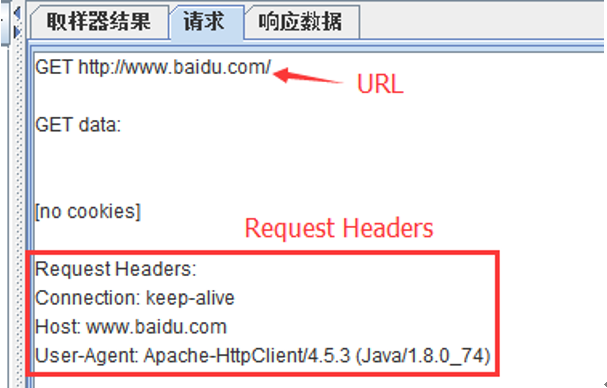
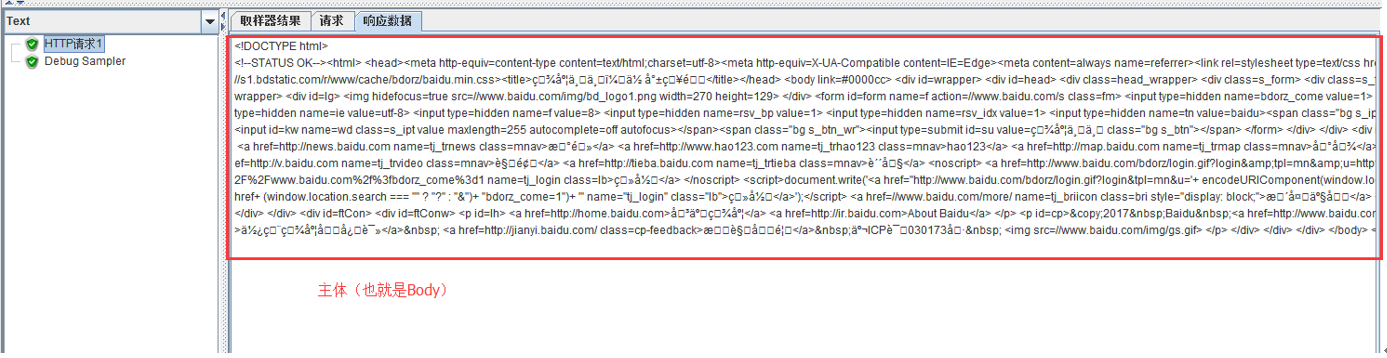
最終提取結果:
使用HTTP請求訪問百度,正則表示式提取器 如本節開頭截圖