
Android逆向之旅—Android應用的漢化功能(修改SO中的字串內容)
本文轉載自趙四大神
一、前言
今天我們繼續來講述逆向的知識,今天我們來講什麼呢?我們在前一篇文章中介紹了關於SO檔案的格式,今天我們繼續這個話題來看看如何修改SO檔案中的內容,看一下我們研究的主題:
需求:想漢化一個Apk
思路:漢化,想必大家都瞭解,老外開發的一個遊戲,結果他不支援中文,那麼我們就需要做一下漢化,那麼我們知道漢化的工作其實很簡單,就是替換Apk中英文的字串位置,那麼我們可以反編譯Apk..得到smail檔案,然後直接找到需要漢化的字串位置,然後修改成對應的中文即可。這個倒是很簡單。這裡就不詳細說明了,但是現在問題變得有點複雜,就是有些apk,他把字串放到了底層,也就是so檔案中,那麼問題就變的傷心了,我需要去修改so中的內容了。這時候我們不能像修改smail檔案那麼搞了,因為底層都是指標操作字串,而且還涉及到字串的地址。所以我們這時候需要了解so檔案的格式,才能做相應的修改。所以大家需要先來看這篇文章才能繼續我們今天的課題:
二、準備工作
我們瞭解了SO的檔案格式,也手動的寫了一個工具來解析他,那麼我們現在如果想修改一個字串的內容,還需要一些準備。
需要兩個工具:
1、010Editor:檢視16進位制的工具,比UE輕了很多,也很好用
2、IDA 6.6 Pro:這個工具太出名了,在逆向領域中堪比Android中的AndroidStudio.沒有他的話,逆向是難上加難,當然,這個工具也是我們日後介紹逆向領域必備的技能,網上也有相關工具的說明書,這個工具學起來不難,但是一定要學會使用
3、NDK:這個工具想必大家也不陌生了,我們後面需要編譯so檔案,所以需要用到他,關於如何配置NDK的話,看這篇文章:
有了這兩個三具我們還不夠,我們還需要了解一個常識:
我們在Java中不會接觸到指標的概念,但是用IDA分析so的時候,就是彙編指令,所以都是地址,我們在學習C的時候,知道一句話:地址就是指標,指標就是地址,所以我們需要了解指標的一點知識,我們在編寫C程式的時候,程式碼中定義一個字串:
char *str = "Hello World";str就是一個指標,指向Hello World中的首個字元,也是這個字串在記憶體中的首地址,但是這裡我們需要了解的是,這個地址不是絕對地址,而是相對地址。是絕對地址減去偏移值。
三、技術原理
上面的準備工作做完了,下面我們來看看具體思路吧:
我們如果做漢化工作的話,其實原理打攪都瞭解,就是反編譯Apk,然後將其英文改稱中文即可。如果Apk的字串都定義在string.xml中,或者是在java層程式碼中的話,那麼就簡單了,我們只需要用apktools工具修改smail檔案和新增中文的string.xml就可以了。但是我今天不是重點來說這個內容,因為這個內容沒難度。大家都可以實現的,今天我們要說的是有難度的,加入字串定義在native層中,也就是在so檔案中,我們該怎麼辦?
通過前一篇的so檔案的格式詳解之後,我們知道字串都存在哪裡。
下面我們就來通過一個案例來分析一下如何修改so中的字串內容,這個案例的native層我們不準備自己手寫了,我們用NDK中的一個demo就可以了:

在NDK的這個目錄下,我們看一下C++的程式碼:
/*
* Copyright (C) 2009 The Android Open Source Project
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*
*/
#include <string.h>
#include <jni.h>
/* This is a trivial JNI example where we use a native method
* to return a new VM String. See the corresponding Java source
* file located at:
*
* apps/samples/hello-jni/project/src/com/example/hellojni/HelloJni.java
*/
jstring
Java_com_example_hellojni_HelloJni_stringFromJNI( JNIEnv* env, jobject thiz )
{
return (*env)->NewStringUTF(env, "Hello from JNI !");
}
上層的Java程式碼:
package com.example.hellojni;
import android.app.Activity;
import android.os.Bundle;
import android.view.View;
import android.view.View.OnClickListener;
import android.widget.Button;
public class HelloJni extends Activity{
@Override
public void onCreate(Bundle savedInstanceState){
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
final Button btn = (Button)findViewById(R.id.btn);
btn.setOnClickListener(new OnClickListener(){
@Override
public void onClick(View arg0) {
String str = stringFromJNI();
btn.setText(str);
}});
}
public native String stringFromJNI();
public native String unimplementedStringFromJNI();
static {
System.loadLibrary("hello-jnis");
}
}
我們看到native層的字串是:Hello from JNI !,那麼我們現在來修改這個字串內容。
四、技術實現
這時候我們就需要用到上面說到的那個強大的工具:IDA了,開啟so檔案,很簡單的,介面如下:
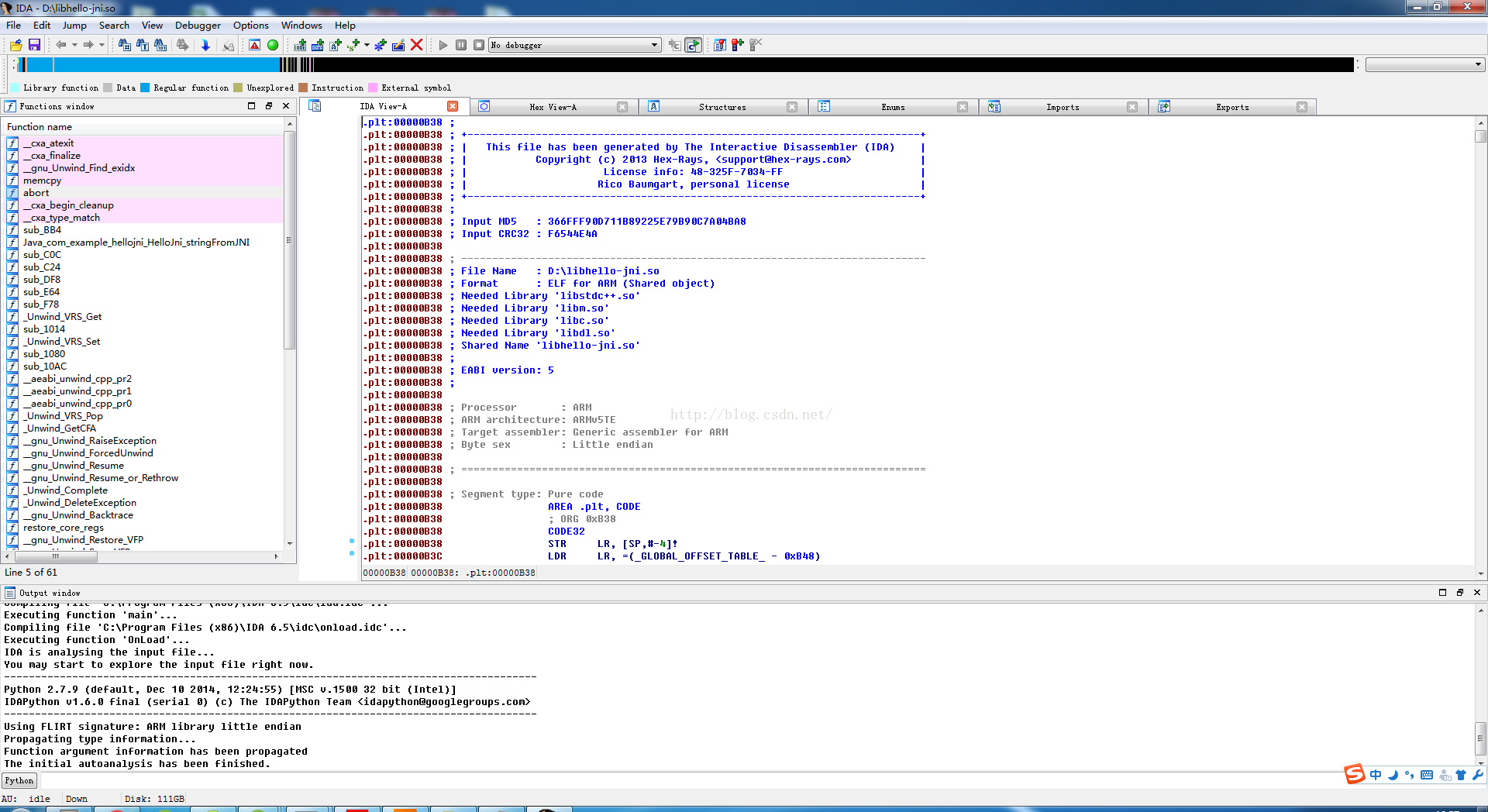
這裡有很多視窗的,所以IDA工具很強大,我們需要慢慢的學習,還有各種快捷鍵的使用,都是一門學問。
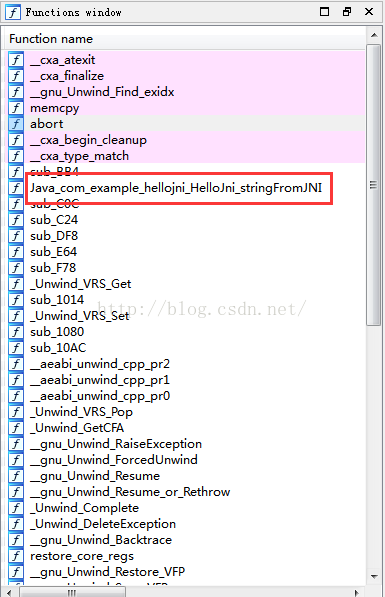
在Functions window視窗中我們可以看到我們的native函式,如果太多的話,我們可以用Ctrl+F搜尋。然後我們雙擊這個函式,在IDA View視窗中就可以看到這個函式的彙編程式碼了:
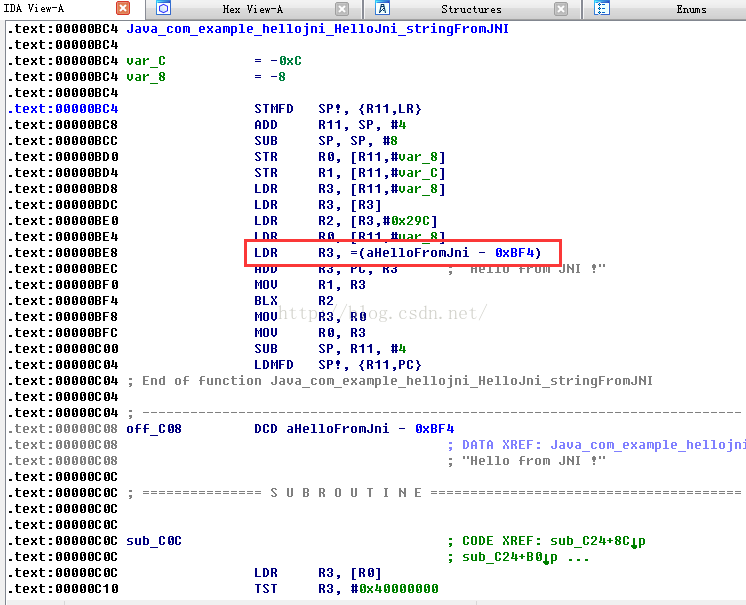
關於彙編指令,這裡也不多解釋了,大學裡面都學過了,但是可能都忘了,所以還得複習一下。這裡我們看到了,那個字串的地址:aHelloFromJni – 0xBF4,0xBF4是偏移地址,這個aHelloFromJni應該是一個符號,所以我們雙擊跳到這個字串的絕對地址。
這裡又要在做一個插曲了,就是在詳細介紹一下elf檔案中的各個段的資訊:
我們在IDA中可以使用Shift+F7快捷鍵開啟段視窗:
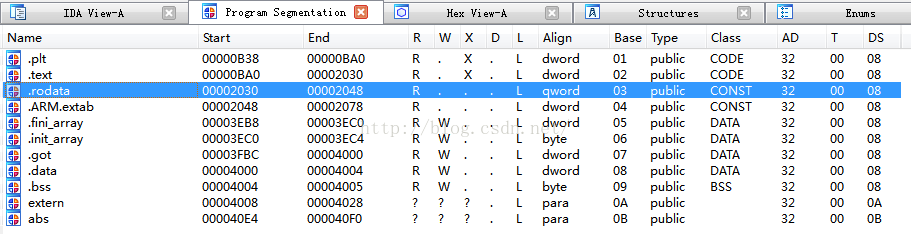
當然我們在IDA View視窗中使用Ctrl+S快捷鍵:
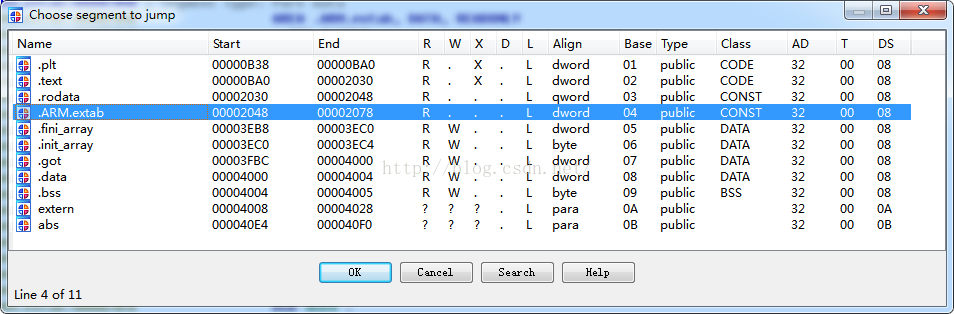
第一、介紹ELF檔案的各個段資訊
那麼下面就來看看這些段的資訊:
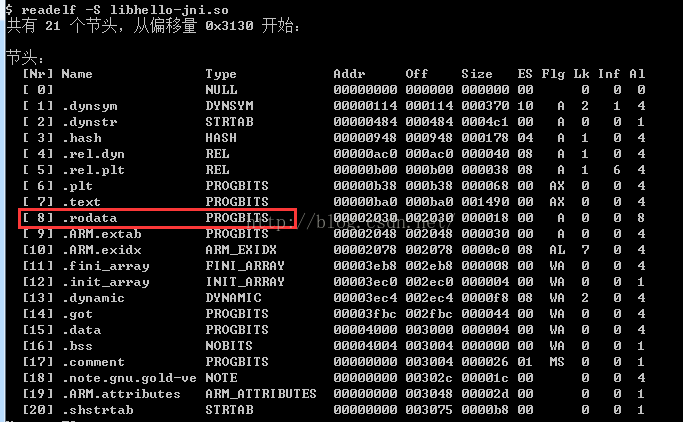
ELF檔案主要由檔案頭(ELF header)、程式碼段(.text)、資料段(.data)、.bss段、只讀資料段(.rodata)、段表(section table)、符號表(symtab)、字串表()、重定位表(.rel.text)如下圖所示:
程式碼段與資料段分開的原因:
1.對程序來說,資料段是可讀寫的,指令段是隻讀的。這樣可以防止程式指令被改寫。
2.指令區與資料區的分離有助於提高程式的區域性性,有助於對CPU快取命中率的提高。
3.當系統執行多個改程式的副本的時候,他們對應的指令都是一樣的,此時記憶體只需要保留一份改程式的指令即可。當然,每個副本程序的資料區域是不一樣的,他們是程序私有的
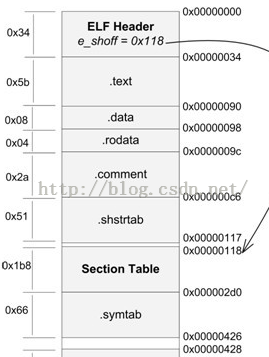
結合下圖進行分析
如上圖所示,
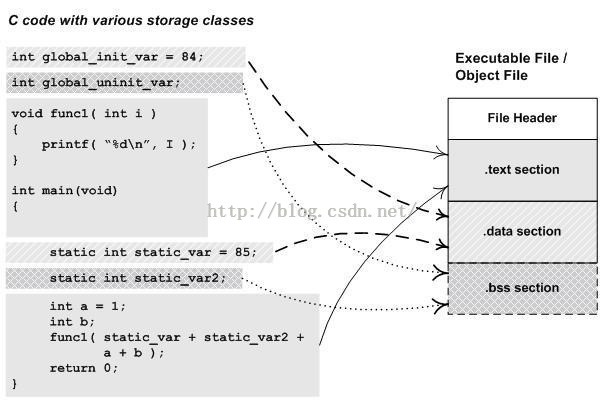
1、.text段
一般C語言編譯後的執行語句都編譯成機器程式碼,儲存在.text段。
2、.data段
已經初始化的全域性變數和區域性靜態變數(雖然預設會初始化為0,或者手動初始化為0,都沒有必要在資料段分配空間,直接放在.bss段,就預設值為0了)都儲存在.data段。
大體來說,該section包含了在記憶體中的程式的初始化資料;data段包含三個部分:heap(堆)、stack(棧)和靜態資料區。即.data還會存放其他型別的資料,比如區域性變數。
資料段只是存放資料,變數名存放在字串表中。
3、.bss段
未初始化的全域性變數和區域性靜態變數都儲存在.bss段。
大體來說該section包含了在記憶體中的程式的未初始化的資料。
由於程式載入(一般是指main之前)時,bss會被作業系統清零,所以未賦初值或初值為0的全域性變數都在bss。.bss段只是為未初始化的全域性變數和區域性靜態變數預留位置而已,它並沒有內容,所以它在檔案中也不佔據空間,這樣可減少目標檔案體積。
但程式執行時需為變數分配記憶體空間,故目標檔案必須記錄所有未初始化的靜態分配變數大小總和(通過start_bss和end_bss地址寫入機器程式碼)。當載入器(loader)載入程式時,將為BSS段分配的記憶體初始化為0。
4、.rodata段
存放只讀資料,一般是程式裡面的只讀變數(如const修飾的變數),以及字串常量(不一定,也可能放在.data中)。
5、.got段
GOT(Global Offset Table)表中每一項都是本執行模組要引用的一個全域性變數或函式的地址。可以用GOT表來間接引用全域性變數、函式,也可以把GOT表的首地址作為一個基 準,用相對於該基準的偏移量來引用靜態變數、靜態函式。由於載入器不會把執行模組載入到固定地址,在不同程序的地址空間中,各執行模組的絕對地址、相對位 置都不同。這種不同反映到GOT表上,就是每個程序的每個執行模組都有獨立的GOT表,所以程序間不能共享GOT表。
6、.plt段
過程連結表用於把位置獨立的函式呼叫重定向到絕對位置。通過 PLT 動態連結的程式支援惰性繫結模式。每個動態連結的程式和共享庫都有一個 PLT,PLT 表的每一項都是一小段程式碼,對應於本執行模組要引用的一個全域性函式。程式對某個函式的訪問都被調整為對 PLT 入口的訪問。
每個 PLT 入口項對應一個 GOT 項,執行函式實際上就是跳轉到相應 GOT 項儲存的地址,該 GOT 項初始值為 PLTn項中的 push 指令地址(即 jmp 的下一條指令,所以第 1 次跳轉沒有任何作用),待符號解析完成後存放符號的真正地址。動態連結器在裝載對映共享庫時在 GOT 裡設定 2 個特殊值:在 GOT+4( 即 GOT[1]) 設定動態庫對映資訊資料結構link_map 地址;在 GOT+8(即 GOT[2])設定動態連結器符號解析函式的地址_dl_runtime_resolve。
每一個外部定義的符號在全域性偏移表 (Global Offset Table GOT)中有相應的條目,如果符號是函式則在過程連線表(Procedure Linkage Table PLT)中也有相應的條目
下面來看張圖就瞭解了.got段和.plt段的關係:
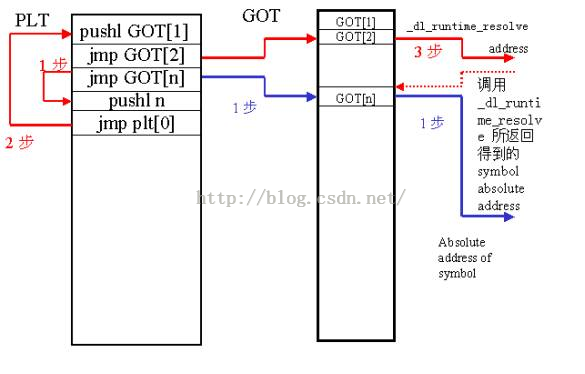
這個在我們之前說到Hook技術就是用著兩個段來實現的。只要修改需要hook的函式地址,插入我們hook的函式,執行之後,再回來就可以了,這裡只要修改.got和.plt表就可以了,相關知識大家去網上搜一下吧。這裡就不在解釋了。
第二、修改字串
解釋了上面的各個段詳情之後,我們看到Hello from JNI !這個字串是個常量,所以放在了.rodata段中,那麼我們現在修改這個字串,比如我們要修改成 “jiangwei”,這裡該怎麼弄呢?很簡單,直接修改就可以了,但是我們不用IDA來修改,因為IDA修改起來特麻煩,我需要用010Editor工具來做修改,簡單。用這個工具開啟so檔案:
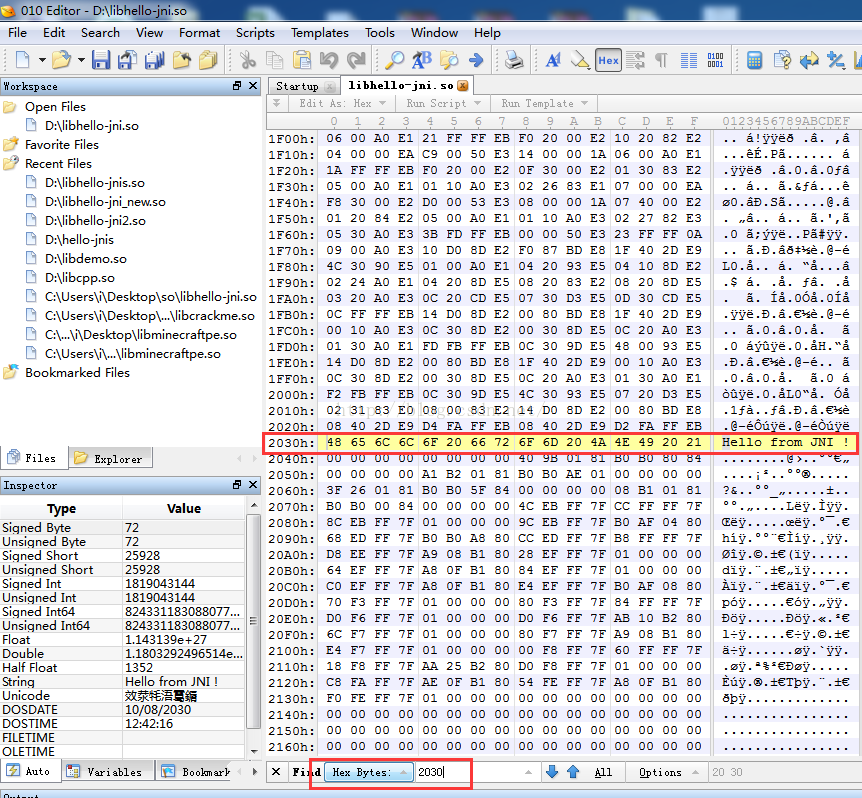
因為我們在IDA中知道這個字串的地址是:0x2030,所以這裡使用Ctrl+G快捷鍵直接跳轉到這個地址就可以了,我們看到了這個字串內容:我們直接修改:

但是這裡需要注意的是:“jiangwei”這個字串比”Hello from JNI !”這個字串短,所以我們不能改變原來字串的長度,所以需要用空字串來補充。這裡我們可以看到在修改字串的時候我們會發現有這些問題:
遵從一個原則:在修改檔案的內容的時候,一定不能影響到其他內容的地址,這樣會導致其他資訊的偏移值發生變化之後,程式碼就會異常報錯的。有了這個原則,我們就有以下集中情況以及處理方法:
1、如果修改的字串的長度和源字串的長度相等,那麼簡單,直接替換就可以
2、如果修改的字串的長度比源字串的長度短,那麼我們需要用空字串進行補齊
3、如果修改的字串的長度比源字串的長度要長,那麼我們就需要這麼做了:
1) 在.rodata段、.data段、.string段找到一塊空地,在哪裡新增一個字串,這裡的so檔案,我們看到沒有太多的空地,我們看一下下面的這個so檔案:

如何找到這些段,很簡單,用IDA開啟so檔案,用Ctrl+S搜尋,到這個段得到起始地址,然後在用010Editor開啟,我們看到有一大片空字串的地方,這就是空地,我們可以在這裡新增一個字串,新增完之後,我們還需要做一件事:
就是要修改源字串在程式碼中的指標(相對地址),如何在檔案中找到這個地址呢?很簡單:
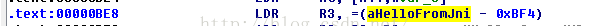
我們用絕對地址減去偏移值就可以了:0x2030 – 0xBF4 = 0x143C
但是這裡又需要注意一個問題,就是高位和地位需要倒敘,這個是因為記憶體地址都是從地位到高位開始分配地址的。
所以倒敘之後就是0x3C14,這個就是源字串的指標,在010Editor中查詢一下:

然後用同樣的方法來計算出新字串的指標,然後替換即可。
但是我們看到案例的so檔案沒有空地,怎麼辦呢?這時候我們就需要自己新增一個段來充當空白地了。
第三、新增新的段(Section)
這個就引出了我們今天的核心內容,如何在so檔案中新增一個自己的段資訊?
如果要新增一個段的話,我們需要注意哪些問題,步驟是什麼?
1、新增段的內容肯定不能影響到以前的資訊內容,特別是偏移值,那麼按照這個原則的話,我們只能在檔案的末尾新增一個段了。那麼這時候新加的段的位置找到了。
2、新增一個段我們需要做哪些工作?
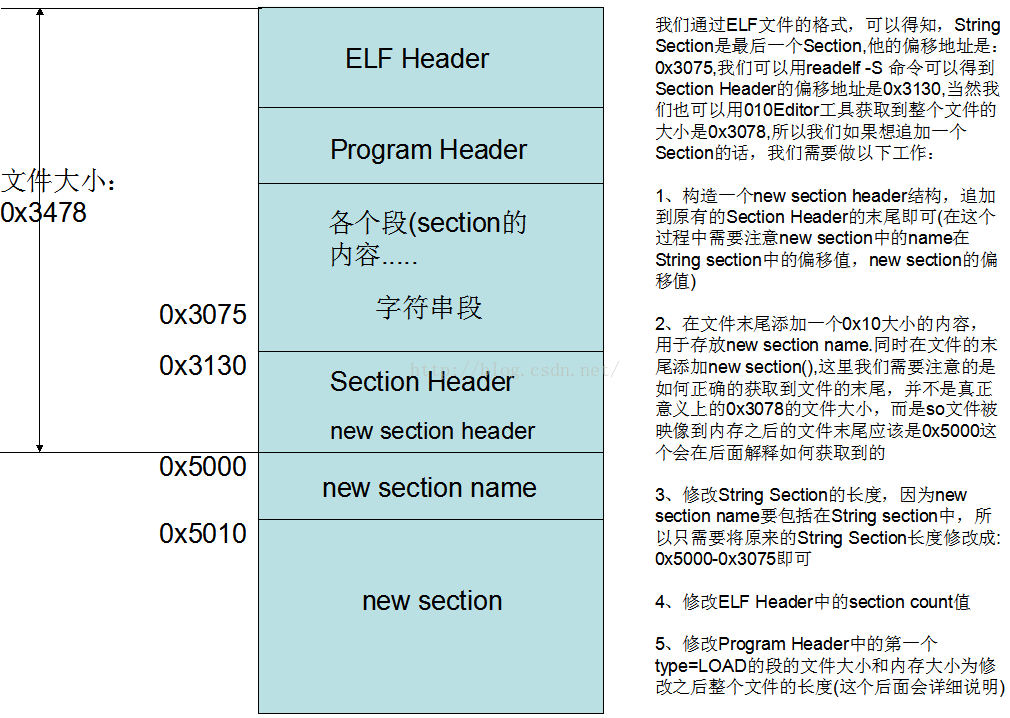
1)、構造一個new section header結構,追加到原有的Section Header的末尾即可(在這個過程中需要注意new section中的name在String section中的偏移值,new section的偏移值)
2)、在檔案末尾新增一個0x10大小的內容,用於存放new section name.同時在檔案的末尾新增new section(),這裡我們需要注意的是如何正確的獲取到檔案的末尾,並不是真正意義上的0x3078的檔案大小,而是so檔案被映像到記憶體之後的檔案末尾應該是0x5000這個會在後面解釋如何獲取到的
3)、修改String Section的長度,因為new section name要包括在String section中,所以只需要將原來的String Section長度修改成:
0x5000-0x3075即可
4)、修改ELF Header中的section count值
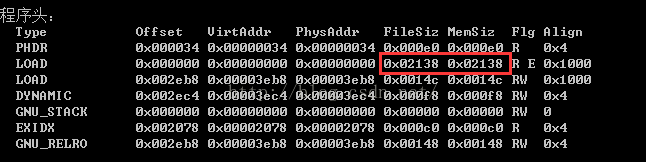
5)、修改Program Header中的第一個type=LOAD的段的檔案大小和記憶體大小為修改之後整個檔案的長度(這個後面會詳細說明)
有了上面的步驟下面我們就好辦了。直接上程式碼吧:
第一步:新增Section Header資訊
/**
* 新增section header資訊
* 原理:
* 找到String Section的位置,然後獲取他偏移值
* 將section新增到檔案末尾
*/
public static byte[] addSectionHeader(byte[] src){
/**
* public byte[] sh_name = new byte[4];
public byte[] sh_type = new byte[4];
public byte[] sh_flags = new byte[4];
public byte[] sh_addr = new byte[4];
public byte[] sh_offset = new byte[4];
public byte[] sh_size = new byte[4];
public byte[] sh_link = new byte[4];
public byte[] sh_info = new byte[4];
public byte[] sh_addralign = new byte[4];
public byte[] sh_entsize = new byte[4];
*/
byte[] newHeader = new byte[sectionSize];
//構建一個New Section Header
newHeader = Utils.replaceByteAry(newHeader, 0, Utils.int2Byte(addSectionStartAddr - stringSectionOffset));
newHeader = Utils.replaceByteAry(newHeader, 4, Utils.int2Byte(ElfType32.SHT_PROGBITS));//type=PROGBITS
newHeader = Utils.replaceByteAry(newHeader, 8, Utils.int2Byte(ElfType32.SHF_ALLOC));
newHeader = Utils.replaceByteAry(newHeader, 12, Utils.int2Byte(addSectionStartAddr + newSectionNameLen));
newHeader = Utils.replaceByteAry(newHeader, 16, Utils.int2Byte(addSectionStartAddr + newSectionNameLen));
newHeader = Utils.replaceByteAry(newHeader, 20, Utils.int2Byte(newSectionSize));
newHeader = Utils.replaceByteAry(newHeader, 24, Utils.int2Byte(0));
newHeader = Utils.replaceByteAry(newHeader, 28, Utils.int2Byte(0));
newHeader = Utils.replaceByteAry(newHeader, 32, Utils.int2Byte(4));
newHeader = Utils.replaceByteAry(newHeader, 36, Utils.int2Byte(0));
//在末尾增加Section
byte[] newSrc = new byte[src.length + newHeader.length];
newSrc = Utils.replaceByteAry(newSrc, 0, src);
newSrc = Utils.replaceByteAry(newSrc, src.length, newHeader);
return newSrc;
}這裡我們需要詳細介紹一下SectionHeader中的各個欄位的含義了:
還是看那個pdf文件說的最詳細了

1)、sh_name:這個欄位是Section name,這個值一般儲存在.strtab段中的,但是這個值是section name在.strtab段中的偏移值,所以值是:new section的起始地址減去String Section的偏移值
那麼new section的起始地址是多少呢?
這個我們剛剛說過了,這個段是載入檔案的末尾處的,所以new section的起始地址就是檔案的總長度:0x3078
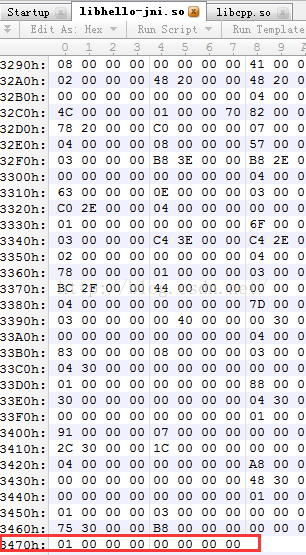
那String Section的偏移值是多少呢?這個也簡單,因為我們在之前的一篇文章中介紹瞭如何解析elf檔案
那裡我們解析出了所有的Section Header資訊,然後我們在定位String Section在這個header列表中的位置即可,這個位置在elf檔案的頭部資訊中有,就是這個欄位:e_shstrndx
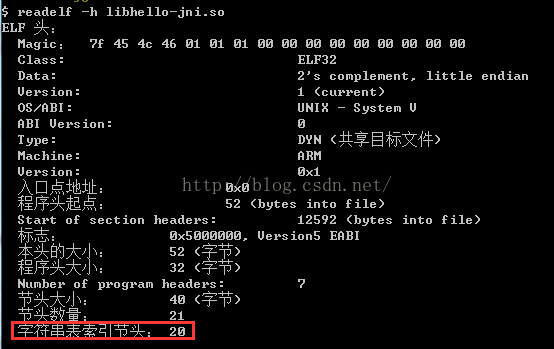
那麼我們就可以找到String Section的偏移值了:0x3075

2)、sh_type:段的型別,這個欄位我們需要把和設定的和.rodata段的型別相同即可,取值如下:
/****************sh_type********************/
public static final int SHT_NULL = 0;
public static final int SHT_PROGBITS = 1;
public static final int SHT_SYMTAB = 2;
public static final int SHT_STRTAB = 3;
public static final int SHT_RELA = 4;
public static final int SHT_HASH = 5;
public static final int SHT_DYNAMIC = 6;
public static final int SHT_NOTE = 7;
public static final int SHT_NOBITS = 8;
public static final int SHT_REL = 9;
public static final int SHT_SHLIB = 10;
public static final int SHT_DYNSYM = 11;
public static final int SHT_NUM = 12;
public static final int SHT_LOPROC = 0x70000000;
public static final int SHT_HIPROC = 0x7fffffff;
public static final int SHT_LOUSER = 0x80000000;
public static final int SHT_HIUSER = 0xffffffff;
public static final int SHT_MIPS_LIST = 0x70000000;
public static final int SHT_MIPS_CONFLICT = 0x70000002;
public static final int SHT_MIPS_GPTAB = 0x70000003;
public static final int SHT_MIPS_UCODE = 0x70000004;我們可以看到.rodata段的型別是:PROGBITS
3)、sh_flags:段的屬性,這個欄位的取值如下:
/*****************sh_flag***********************/
public static final int SHF_WRITE = 0x1;
public static final int SHF_ALLOC = 0x2;
public static final int SHF_EXECINSTR = 0x4;
public static final int SHF_MASKPROC = 0xf0000000;
public static final int SHF_MIPS_GPREL = 0x10000000;這個我們看到欄位就知道每個屬性是什麼意思了,這裡我們設定成可分配屬性:ALLOC
4)、sh_addr:段被映像到記憶體中的首地址,也就是這個section的起始地址,也就是檔案的末尾地址在加上section name的大小,看到程式碼,我們把section name大小設定成了0x10,也就說新加的section段的name長度不可超過16個位元組,當然這個數值是可以改的,但是我感覺沒必要了,因為一個section name沒必要搞那麼長。那麼這裡的值就是:檔案的長度+0x10
5)、sh_offset:這個欄位是值該段到檔案開始位置的偏移值,這個值我們想一下就知道他的值和sh_addr的值應該一樣的。
還有其他欄位需要設定,但是這裡沒必要做解釋了,所以就和.rodata段的值保持一致即可。這裡就不再做介紹了。
上面就構造了一個Section Header了,那麼這個頭部加到哪裡呢?肯定也是檔案末尾處了,看上面的圖就知道了:
第二步:新增New Section 的內容到檔案末尾
這一步我們主要是新增一個空白的段在末尾處,大小我們這裡設定為1000個位元組。
/**
* 在檔案末尾新增空白段+增加段名String
* @param src
* @return
*/
public static byte[] addNewSectionForFileEnd(byte[] src){
byte[] stringByte = newSectionName.getBytes();
byte[] newSection = new byte[newSectionSize + newSectionNameLen];
newSection = Utils.replaceByteAry(newSection, 0, stringByte);
//新建一個byte[]
byte[] newSrc = new byte[addSectionStartAddr + newSection.length];
newSrc = Utils.replaceByteAry(newSrc, 0, src);//複製之前的檔案src
newSrc = Utils.replaceByteAry(newSrc, addSectionStartAddr, newSection);//複製section
return newSrc;
}這裡在新增順便把Section name也新增進去了,那麼長度就是1000+0x10個,位置是在檔案的末尾。
第三步:修改String Section Header中的大小
因為我們新加的Section name在String Section中,所以我們還得修改一下String Section的大小了
/**
* 修改.strtab段的長度
*/
public static byte[] changeStrtabLen(byte[] src){
//獲取到String的size欄位的開始位置
int size_index = sectionHeaderOffset + (stringSectionInSectionTableIndex)*sectionSize + stringSectionSizeIndex;
//多了一個Section Header + 多了一個Section的name的16個位元組
byte[] newLen_ary = Utils.int2Byte(addSectionStartAddr - stringSectionOffset + newSectionNameLen);
src = Utils.replaceByteAry(src, size_index, newLen_ary);
return src;
}我們知道String Section Header中的sh_size欄位是記錄大小的,所以我們找到String Section Header然後修改這個欄位的值就可以了,那麼現在的String Section的大小是多大呢?

新的String Section的大小變成了,new section name的結束位置減去String Section的起始位置,也就是:
檔案末尾+0x10 – 0x3075
我們需要把0xb8改成最新的值就可以了。這個sh_size欄位也是好定位的。
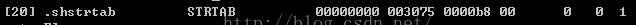
首先知道String Section Header,然後替換sh_size位置的位元組數即可。
第四步:修改elf頭部中section的count數
這步就簡單了,修改一下這個欄位:e_shnum
/**
* 修改elf頭部總的section的總數資訊
*/
public static byte[] changeElfHeaderSectionCount(byte[] src){
byte[] count = Utils.copyBytes(src, elfHeaderSectionCountIndex, 2);
short counts = Utils.byte2Short(count);
counts++;
count = Utils.short2Byte(counts);
src = Utils.replaceByteAry(src, elfHeaderSectionCountIndex, count);
return src;
}第五步:修改Program Header中第一個型別為LOAD的段的檔案大小和記憶體映像的大小
這裡需要修改的是第一個Type為LOAD的file_size和mem_size欄位的大小為檔案的總大小即可。下面會說道type為PT_LOAD的都會被載入到記憶體中。那麼我們如果想把我們新加的段的內容載入記憶體中,這裡需要修改一下file_size和mem_size為檔案的總大小。
程式碼如下:
/**
* 修改Program Header中的資訊
* 把新增的段內容加入到LOAD Segement中
* 就是修改第一個LOAD型別的Segement的filesize和memsize為檔案的總長度
*/
public static byte[] changeProgramHeaderLoadInfo(byte[] src){
//尋找到LOAD型別的Segement位置
int offset = elfHeaderSize + programHeaderSize * firstLoadInPHIndex + programFileSizeIndex;
//file size欄位
byte[] fileSize = Utils.int2Byte(src.length);
src = Utils.replaceByteAry(src, offset, fileSize);
//mem size欄位
offset = offset + 4;
byte[] memSize = Utils.int2Byte(src.length);
src = Utils.replaceByteAry(src, offset, memSize);
//flag欄位
offset = offset + 4;
byte[] flag = Utils.int2Byte(7);
src = Utils.replaceByteAry(src, offset, flag);
return src;
}
上面我們完成了工作,下面還需要來講解一下一個重要的知識點,就是我們上面一直說到的檔案末尾這個詞?
我在開始的時候就說了,這裡的檔案末尾不是真正意義上的檔案末尾,比如這裡的檔案長度是:0x3478
這裡的檔案末尾指的是映像到記憶體中的位元組大小?因為我們知道檔案的大小和這個檔案映像到記憶體中的大小是不一定相等的,因為映像到記憶體中是需要做很多操作的,比如最簡單的就是頁面對其工作,這個就會增加位元組了,所以映像到記憶體的大小肯定是大於等於檔案大小的。
那麼我們該如何獲取到這個檔案映像到記憶體之後的大小呢?這裡就需要先來了解一個知識點:
可執行檔案和共享目標檔案(動態連結庫)是程式在磁碟中的靜態儲存形式;要執行一個程式,系統就要先把相應的可執行檔案和共享目標檔案裝載到程序的地址空間中,這樣就形成一個可執行程序的記憶體空間佈局,稱為程序映象;一個已經裝載完成的程序空間中會包含多個不同的段(Segment),比如,程式碼段、資料段、堆疊段,等等;
準備一個程式的記憶體映象,大體上可以分為兩個步驟:裝載和連結;前者是把目標檔案裝載到記憶體中,後者是解析目標檔案中的符號引用;
一個可執行檔案及其依賴的共享目標檔案被完全成功地裝載到程序的記憶體地址空間中之後,這個可執行檔案或共享目標檔案中的程式頭部表(Program Header Table)就是必須存在的、不可缺少的必需品,程式頭部表是一個數組,陣列中的每一個元素就稱為一個程式頭(Program Header),每一個程式頭描述一個記憶體段(Segment)或者一塊用於準備執行程式的資訊;記憶體中的一個目標檔案中的段包含一個或多個節;也就是ELF檔案在磁碟中的一個或多個節可能會被對映到記憶體中的同一個段中;程式頭只對可執行檔案或共享目標檔案有意義,對於其它型別的目標檔案,該資訊可以忽略;
p_type=PT_LOAD時,段的內容會被從檔案中拷貝到記憶體中,如果p_memsz>p_filesz,則在記憶體中多出的儲存空間中填0補充,即,段在記憶體中可以比在檔案中佔用更大空間;相反,p_filesz永遠都不應該比p_memsz大,因為這樣的話,在記憶體中就將無法完整地對映段的內容;在程式頭部表中,所有PT_LOAD型別的程式頭都按照p_vaddr的值做升序排列;
從上面的兩段話可以看出我們看到兩個知識點:
1、程式頭中的p_type=PT_LOAD的時候,段的內容會被從檔案中拷貝到記憶體中
2、所有PT_LOAD型別的程式頭都按照p_vaddr的值做升序排列的
那麼我們就好辦了,我們只要獲取到最後一個PT_LOAD的p_vaddr的值然後加上這個段的mem_size在做一下頁面對其操作就可以得到記憶體中的末尾了。
關於頁面對其的操作,網上有相關的資料,可以去搜一下,這裡也不解釋了。
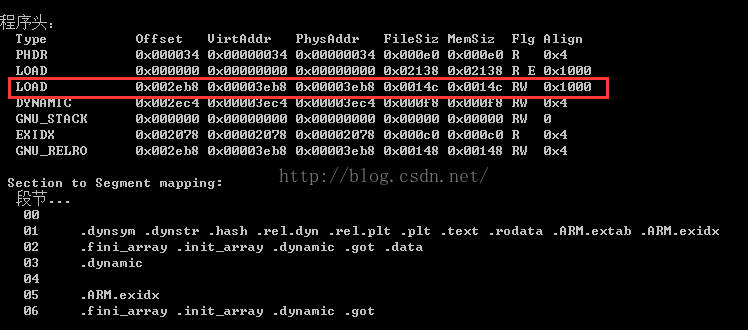
這裡就是0x3EB8+0x14c對0x1000對其操作結果是:0x5000也就是上面我們說的檔案末尾值了。
第四、驗證結果
好了,上面我就做完了所有的工作,下面就將我們修改之後的so檔案儲存一下,然後用readelf工具驗證一下:
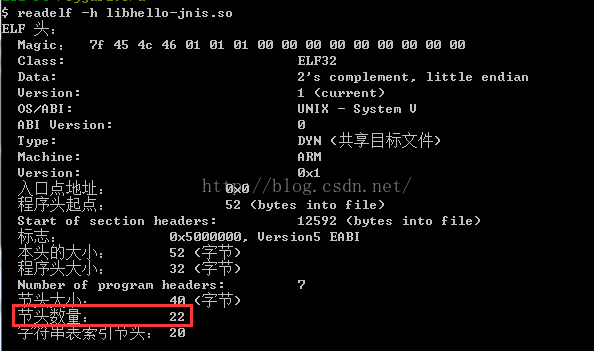
1、驗證elf的頭部資訊中的section變成22了
2、驗證Section Header
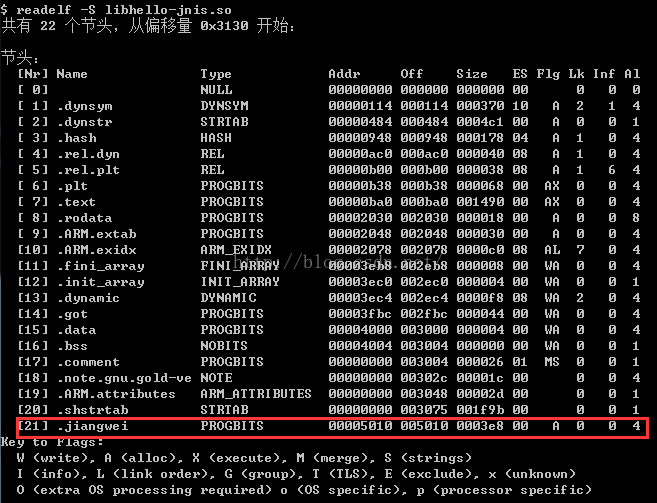
最後一個段是我們新增的
3、驗證Program Header資訊
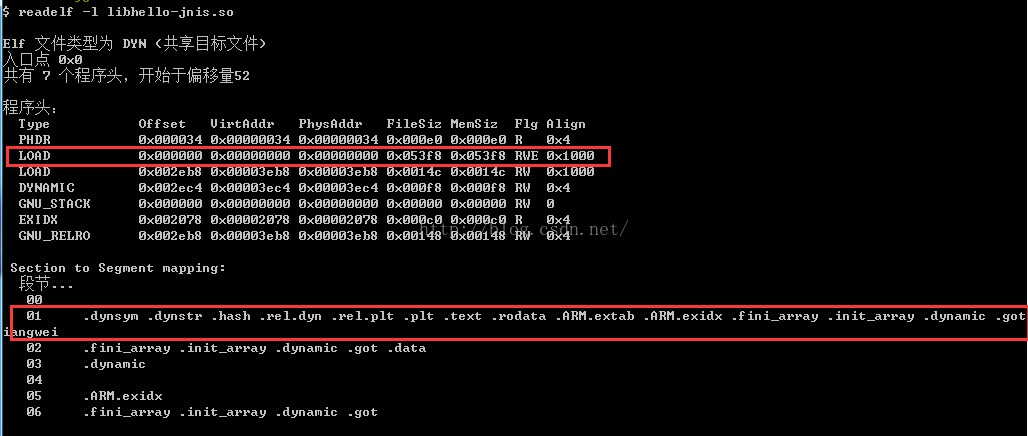
新加的Section能夠載入到記憶體中。
我們同樣也可以用IDA進行驗證一下:
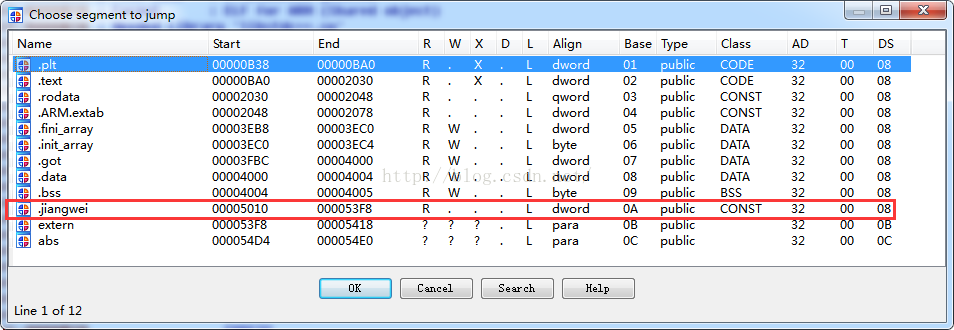
用010Editor檢視一下:
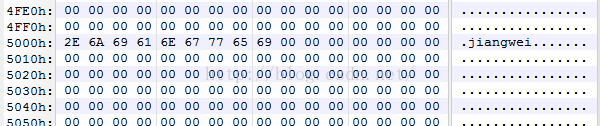
段名位置都是正確的,那麼下面我們就來修改字串吧,因為我們新加的段完全就是一個空白地,想怎麼加就怎麼加?
下面我們來修改一下字串:

在0x5010出添加了修改的字串,那麼我還需修改一下指標:
修改之後的指標:0x5010-0xBF4 = 0x441c
倒敘之後就是0x1C44,我們替換一下源字串的指標,上面說到了是:0x3C14

這就改好了,我們這時候可以用IDA進行驗證一下:

可以看到我們修改應該是成功了。
但是最終的驗證是整合到Android程式中測試:
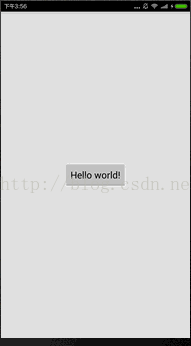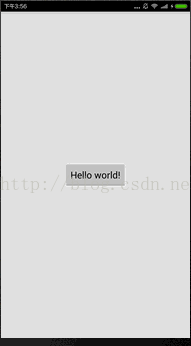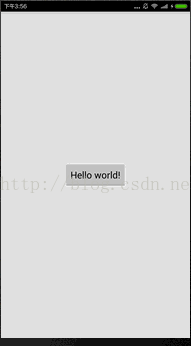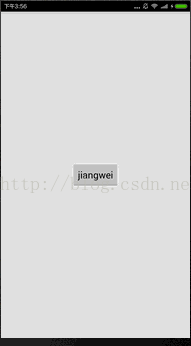
果然成功了。
第五、技術延展
我們這篇文章可能只是通過新增一個section來進行修改字串的內容,其實有了新增段的知識之後,我們可以去給別人的so檔案植入惡意程式碼了,而這段程式碼我們就可以放到我們新加的段中,然後在利用修改.got和.plt段的資訊,幹掉別人的so檔案還是很簡單的。但是呢,這個想法是初級的,我想到了,想必大家也都想到了,那麼就有了防範之道了,比如他們對so加密,這會導致我們無法分析so檔案了。那談何修改so檔案呢?或者是對so檔案進行校驗,一旦修改了,就不能執行,這些都是防禦的方法。但是關於so加密的知識,我後面會詳細介紹,所以說防禦和逆向是相生相剋的,永不停息的戰爭。
第六、知識梳理
這裡我們就算是完成了漢化功能,有的人說?這不是忽悠人嗎?這哪是漢化呀。就是修改so中的字串內容呀。但是這裡我說道了一個新增新段的方法,這個才是本文的核心,如果都能新增段了,那麼替換中文又有何難呢?不過從這篇文章的篇幅來看,就知道這裡的知識點真的很多?而且我可能還有遺漏的地方,下面就來總結一下我們這篇文章的思路把:
思路:
1、我們需要修改so檔案中的字串從而達到漢化效果,但是在在這個過程中我可能會遇到一些問題,就是我們修改的字串的長度和修改之後的字串的長度,因為我們要秉承著修改之後其他部分內容的偏移地址不能發生變化的原則,所以當要修改的字串的長度大於源字串的長度的話,我們就要做一些操作了,這裡我們可以觀察so中有沒有空地,如果有空地而且空地的大小夠用的話,那麼問題就簡單了,如果沒有空地的話,那麼就引出了我們今天的核心內容,自己加段。
2、在加一個段的時候,我們需要注意的哪些問題和具體步驟上面也都說了。我們還是遵照一個原則就是修改之後不能影響之前的內容的偏移值。所以就在檔案的末尾新增,然後構造一個Section header,和追加一個空白的section即可。
3、修改完之後的so,我們需要校驗一下,用readelf工具進行檢視新增的段資訊,或者IDA也是可以的。
技術點:
1、對elf檔案的格式有了深刻的瞭解
2、對記憶體映像的概念有了深刻的瞭解
3、C語言中的字串的指標如何修改
4、IDA工具的初步使用
5、.got和.plt段對hook的過程的作用
相關推薦
Android逆向之旅---Android應用的漢化功能 修改SO中的字串內容
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow
也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
Android逆向之旅—Android應用的漢化功能(修改SO中的字串內容)
本文轉載自趙四大神
一、前言
今天我們繼續來講述逆向的知識,今天我們來講什麼呢?我們在前一篇文章中介紹了關於SO檔案的格式,今天我們繼續這個話題來看看如何修改SO檔案中的內容,看一下我們研究的主題:
需求:想漢化一個Apk
思路:漢化,想必大家都瞭解,老外開發的
Android逆向之旅---Android手機端破解神器MT的內購VIP功能破解教程
一、前言在破解app的時候,我們現在幾乎都是在PC端進行操作,但是之前bin神的MT管理器,可以在手機端直接破解,不過也有很大的侷限性,但是對於一些簡單的app破解沒問題的。這個工具其實原理也很簡單,就
Android逆向之旅—Android手機端破解神器MT的內購VIP功能破解教程
一、前言
在破解app的時候,我們現在幾乎都是在PC端進行操作,但是之前bin神的MT管理器,可以在手機端直接破解,不過也有很大的侷限性,但是對於一些簡單的app破解沒問題的。這個工具其實原理也很簡單,就是解析apk中的dex,arsc等檔案,然後支援修改其中的類方法資
Android逆向之旅---Android中分析某手短視訊的資料請求加密協議(IDA靜態分析SO)第三篇
一、逆向分析在之前的兩篇文章中,我們已經介紹了短視訊四小龍的某音,某山,某拍的資料請求加密協議,不瞭解的同學可以點選檢視:;那麼今天繼續最後一個短視訊那就是某手,不多說了,還是老規矩直接抓包找入口:看到
Android逆向之旅---Android中分析抖音和火山小視訊的資料請求加密協議(IDA動態除錯SO)
一、前言
最近萌發了一個做app的念頭,大致什麼樣的app先暫時不說,後面會詳細介紹這個app的開發流程和架構,不過先要解決一些技術前提問題,技術問題就是需要分析解密當前短視訊四小龍:抖音,火山,秒拍,快手這四家短視訊的資料請求加密協議,只有破解了加密協議,才可以自定義資料請求拉回資料。不多說了,本文先來第一
Android逆向之旅---靜態方式分析破解視頻編輯應用「Vue」水印問題
https http mpeg 朋友圈 無需 爆破 資料 不可 fill 一、故事背景
現在很多人都喜歡玩文藝,特別是我身邊的UI們,拍照一分鐘修圖半小時。就是為了能夠在朋友圈顯得逼格高,不過的確是挺好看的,修圖的軟件太多了就不多說了,而且一般都沒有水印啥的。相比較短視頻有
Android逆向之旅---Hook神器家族的Frida工具使用詳解
常見 fin () 文件的 數值 isp extern dex文件 所有 一、前言
在逆向過程中有一個Hook神器是必不可少的工具,之前已經介紹了Xposed和Substrate了,不了解的同學可以看這兩篇文章:Android中Hook神器Xposed工具介紹 和 Andr
Android逆向之旅---動態方式破解apk前奏篇 Eclipse動態除錯smail原始碼
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow
也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
Android逆向之旅---靜態方式破解微信獲取聊天記錄和通訊錄資訊
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow
也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
Android逆向之旅---靜態分析技術來破解Apk
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow
也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
Android逆向之旅---抖音火山視訊的Native註冊混淆函式獲取方法
一、靜態分析
最近在小密圈中有很多同學都在諮詢有時候有些應用的動態註冊Native函式,在分析so之後發現找不到真的實現函式功能地方,我們知道有時候為了安全考慮會動態註冊Native函式,但是如果只是這麼做的話就會非常簡單,比如這樣的:
這樣的我們熟知Reigster
Android逆向之旅---動態方式破解apk終極篇(加固apk破解方式)
一、前言
今天總算迎來了破解系列的最後一篇文章了,之前的兩篇文章分別為:
第一篇:如何使用Eclipse動態除錯smali原始碼
第二篇:如何使用IDA動態除錯SO檔案
現在要說的就是最後一篇了,如何應對Android中一些加固apk安全防護,在之前的兩篇破
Android逆向之旅---解析編譯之後的Resource arsc檔案格式
一、前言快過年了,先提前祝賀大家新年快樂,這篇文章也是今年最後一篇了。今天我們繼續來看逆向的相關知識,前篇文章中我們介紹瞭如何解析Android中編譯之後的AndroidManifest.xml檔案格式:http://blog.csdn.net/jiangwei09104100
Android逆向之旅---動態方式破解apk進階篇 IDA除錯so原始碼
一、前言今天我們繼續來看破解apk的相關知識,在前一篇:Eclipse動態除錯smali原始碼破解apk 我們今天主要來看如何使用IDA來除錯Android中的native原始碼,因為現在一些app,為了安全或者效率問題,會把一些重要的功能放到native層,那麼這樣一來,我們
Android逆向之旅---SO(ELF)檔案格式詳解
第一、前言從今天開始我們正式開始Android的逆向之旅,關於逆向的相關知識,想必大家都不陌生了,逆向領域是一個充滿挑戰和神祕的領域。作為一名Android開發者,每個人都想去探索這個領域,因為一旦你破解了別人的內容,成就感肯定爆棚,不過相反的是,我們不僅要研究破解之道,也要
Android逆向之旅---動態方式破解apk前奏篇(Eclipse動態除錯smail原始碼)
一、前言今天我們開始apk破解的另外一種方式:動態程式碼除錯破解,之前其實已經在一篇文章中說到如何破解apk了:Android中使用靜態方式破解Apk 主要採用的是靜態方式,步驟也很簡單,首先使用ap
Android逆向之旅---破解一款永久免費網路訪問工具
一、前言因為最近個人需要,想在手機上使用"高階搜尋",但是找了一圈發現都是需要收費的網路工具,奈何我沒錢,所以只能通過專業技能弄一個破解版的。二、應用分析下面就直接奔入主題。首先我們看到到期介面如下:提
Android逆向之旅---基於對so中的section加密技術實現so加固
致謝:一、前言好長時間沒有更新文章了,主要還是工作上的事,連續加班一個月,沒有時間研究了,只有週末有時間,來看一下,不過我還是延續之前的文章,繼續我們的逆向之旅,今天我們要來看一下如何通過對so加密,在介紹本篇文章之前的話,一定要先閱讀之前的文章:so檔案格式詳解以及如何解析
Android逆向之旅---Native層的Hook神器Cydia Substrate使用詳解
一、前言在之前已經介紹過了Android中一款hook神器Xposed,那個框架使用非常簡單,方法也就那幾個,其實最主要的是我們如何找到一個想要hook的應用的那個突破點。需要逆向分析app即可。不瞭解Xposed框架的同學可以檢視:Android中hook神器Xposed使用詳解;關於hook使用以及原理
Android逆向之旅---Android應用的漢化功能 修改SO中的字串內容
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
Android逆向之旅—Android應用的漢化功能(修改SO中的字串內容)
本文轉載自趙四大神 一、前言 今天我們繼續來講述逆向的知識,今天我們來講什麼呢?我們在前一篇文章中介紹了關於SO檔案的格式,今天我們繼續這個話題來看看如何修改SO檔案中的內容,看一下我們研究的主題: 需求:想漢化一個Apk 思路:漢化,想必大家都瞭解,老外開發的
Android逆向之旅---Android手機端破解神器MT的內購VIP功能破解教程
一、前言在破解app的時候,我們現在幾乎都是在PC端進行操作,但是之前bin神的MT管理器,可以在手機端直接破解,不過也有很大的侷限性,但是對於一些簡單的app破解沒問題的。這個工具其實原理也很簡單,就
Android逆向之旅—Android手機端破解神器MT的內購VIP功能破解教程
一、前言 在破解app的時候,我們現在幾乎都是在PC端進行操作,但是之前bin神的MT管理器,可以在手機端直接破解,不過也有很大的侷限性,但是對於一些簡單的app破解沒問題的。這個工具其實原理也很簡單,就是解析apk中的dex,arsc等檔案,然後支援修改其中的類方法資
Android逆向之旅---Android中分析某手短視訊的資料請求加密協議(IDA靜態分析SO)第三篇
一、逆向分析在之前的兩篇文章中,我們已經介紹了短視訊四小龍的某音,某山,某拍的資料請求加密協議,不瞭解的同學可以點選檢視:;那麼今天繼續最後一個短視訊那就是某手,不多說了,還是老規矩直接抓包找入口:看到
Android逆向之旅---Android中分析抖音和火山小視訊的資料請求加密協議(IDA動態除錯SO)
一、前言 最近萌發了一個做app的念頭,大致什麼樣的app先暫時不說,後面會詳細介紹這個app的開發流程和架構,不過先要解決一些技術前提問題,技術問題就是需要分析解密當前短視訊四小龍:抖音,火山,秒拍,快手這四家短視訊的資料請求加密協議,只有破解了加密協議,才可以自定義資料請求拉回資料。不多說了,本文先來第一
Android逆向之旅---靜態方式分析破解視頻編輯應用「Vue」水印問題
https http mpeg 朋友圈 無需 爆破 資料 不可 fill 一、故事背景 現在很多人都喜歡玩文藝,特別是我身邊的UI們,拍照一分鐘修圖半小時。就是為了能夠在朋友圈顯得逼格高,不過的確是挺好看的,修圖的軟件太多了就不多說了,而且一般都沒有水印啥的。相比較短視頻有
Android逆向之旅---Hook神器家族的Frida工具使用詳解
常見 fin () 文件的 數值 isp extern dex文件 所有 一、前言 在逆向過程中有一個Hook神器是必不可少的工具,之前已經介紹了Xposed和Substrate了,不了解的同學可以看這兩篇文章:Android中Hook神器Xposed工具介紹 和 Andr
Android逆向之旅---動態方式破解apk前奏篇 Eclipse動態除錯smail原始碼
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
Android逆向之旅---靜態方式破解微信獲取聊天記錄和通訊錄資訊
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
Android逆向之旅---靜態分析技術來破解Apk
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
Android逆向之旅---抖音火山視訊的Native註冊混淆函式獲取方法
一、靜態分析 最近在小密圈中有很多同學都在諮詢有時候有些應用的動態註冊Native函式,在分析so之後發現找不到真的實現函式功能地方,我們知道有時候為了安全考慮會動態註冊Native函式,但是如果只是這麼做的話就會非常簡單,比如這樣的: 這樣的我們熟知Reigster
Android逆向之旅---動態方式破解apk終極篇(加固apk破解方式)
一、前言 今天總算迎來了破解系列的最後一篇文章了,之前的兩篇文章分別為: 第一篇:如何使用Eclipse動態除錯smali原始碼 第二篇:如何使用IDA動態除錯SO檔案 現在要說的就是最後一篇了,如何應對Android中一些加固apk安全防護,在之前的兩篇破
Android逆向之旅---解析編譯之後的Resource arsc檔案格式
一、前言快過年了,先提前祝賀大家新年快樂,這篇文章也是今年最後一篇了。今天我們繼續來看逆向的相關知識,前篇文章中我們介紹瞭如何解析Android中編譯之後的AndroidManifest.xml檔案格式:http://blog.csdn.net/jiangwei09104100
Android逆向之旅---動態方式破解apk進階篇 IDA除錯so原始碼
一、前言今天我們繼續來看破解apk的相關知識,在前一篇:Eclipse動態除錯smali原始碼破解apk 我們今天主要來看如何使用IDA來除錯Android中的native原始碼,因為現在一些app,為了安全或者效率問題,會把一些重要的功能放到native層,那麼這樣一來,我們
Android逆向之旅---SO(ELF)檔案格式詳解
第一、前言從今天開始我們正式開始Android的逆向之旅,關於逆向的相關知識,想必大家都不陌生了,逆向領域是一個充滿挑戰和神祕的領域。作為一名Android開發者,每個人都想去探索這個領域,因為一旦你破解了別人的內容,成就感肯定爆棚,不過相反的是,我們不僅要研究破解之道,也要
Android逆向之旅---動態方式破解apk前奏篇(Eclipse動態除錯smail原始碼)
一、前言今天我們開始apk破解的另外一種方式:動態程式碼除錯破解,之前其實已經在一篇文章中說到如何破解apk了:Android中使用靜態方式破解Apk 主要採用的是靜態方式,步驟也很簡單,首先使用ap
Android逆向之旅---破解一款永久免費網路訪問工具
一、前言因為最近個人需要,想在手機上使用"高階搜尋",但是找了一圈發現都是需要收費的網路工具,奈何我沒錢,所以只能通過專業技能弄一個破解版的。二、應用分析下面就直接奔入主題。首先我們看到到期介面如下:提
Android逆向之旅---基於對so中的section加密技術實現so加固
致謝:一、前言好長時間沒有更新文章了,主要還是工作上的事,連續加班一個月,沒有時間研究了,只有週末有時間,來看一下,不過我還是延續之前的文章,繼續我們的逆向之旅,今天我們要來看一下如何通過對so加密,在介紹本篇文章之前的話,一定要先閱讀之前的文章:so檔案格式詳解以及如何解析
Android逆向之旅---Native層的Hook神器Cydia Substrate使用詳解
一、前言在之前已經介紹過了Android中一款hook神器Xposed,那個框架使用非常簡單,方法也就那幾個,其實最主要的是我們如何找到一個想要hook的應用的那個突破點。需要逆向分析app即可。不瞭解Xposed框架的同學可以檢視:Android中hook神器Xposed使用詳解;關於hook使用以及原理