
UI更新為什麼一定要在UI執行緒裡?幕後真相究竟如何?
相信很多人看到這個標題之後輕笑一聲,UI更新為啥要在UI執行緒裡?逗呢,這是谷歌專門制定的規則,當然要遵循規則來玩兒啦。但是細緻的人看到後半截標題之後就不會那麼輕易的下結論了,二八定律告訴我們,大部分人都知道的事兒往往有著貓膩。
我當然相信且明確知道谷歌制定了那麼一套規則:UI更新一定要在主執行緒中進行。所以依舊取這個標題絕對不是譁眾取寵。本文需要討論的內容主要有以下幾點:
1.谷歌為什麼要制定這套規則?
2.這套規則背後隱藏的機制是什麼?
3.這套規則是如何形成使用閉環的?
4.該機制的細節有哪些?
5.這套規則的優勢和劣勢有哪些?
6.這套規則未來可能的前景有哪些?
帶著這些問題展開我的理解進行討論。
[TOC]
谷歌為什麼要制定這套規則
討論這個命題之前,先丟擲我認為的結論:
谷歌提出“UI更新一定要在UI執行緒裡實現”這一規則的根本原因在於提高移動端UI的使用效率和體驗。
在移動裝置中,UI的使用是絕對裝置對於使用者體驗的重要因素之一。而谷歌android系統當中的控制元件都不是執行緒安全的,這導致當使用多執行緒模式的時候在多個執行緒共同使用同一個UI控制元件時容易發生不可控的錯誤,而這是致命的。
那麼谷歌為什麼不把UI控制元件設計成執行緒安全的呢?我認為這也是移動端的特點所致,由於移動端的應用十分講究UI,不單單數量多,UI的互動方式也很多,而且UI還會涉及到動畫的體現等等,諸多因素疊加,如果考慮使用多執行緒的話,執行緒間存在掛起和堵塞,會十分影響UI的使用效率,這對於移動端app來說是不可饒恕的。另一方面,移動端app所屬的移動裝置本身具有一定的不足:如系統推出之初記憶體小、磁碟容量小、CPU數量和效能等等,這些先天性的移動裝置特徵也為谷歌在最初設計UI執行緒這一方案奠定了基礎。 因此,規則的產生基於產品的特點和使用場景,在這樣的移動端應用大背景下,在移動端的裝置特徵下,多執行緒與移動端所期許的高效快速的使用體驗下是存在衝突矛盾的,所以至少目前的多執行緒模型是不合適的。由此,谷歌推出單執行緒模型,所有涉及UI的操作都在一個執行緒內完成,這個執行緒由於主要用於UI的效率提升,為UI服務,就稱為了UI執行緒。既然是單執行緒模型,且講究UI的使用效率,那麼就催生出了另一個概念: 在這個單執行緒UI執行緒內(ActivityThread)中不可以執行耗時操作,如果有耗時操作,就有了熟悉的"ANR"錯誤了。
這套規則背後隱藏的機制是什麼
前面瞭解了下谷歌推出UI執行緒的原因,但是UI執行緒基於的模型是單執行緒模型,而為了單執行緒模型下UI效率,禁止UI執行緒內進行耗時任務的執行,推出了ANR。但是,有時候確實需要執行耗時任務該如何呢?在單執行緒模型下,UI執行緒負責UI更新,子執行緒負責耗時任務。當子執行緒中的耗時任務執行完成之後需要更新UI的時候,由於分屬不同執行緒,因此推出了Handler訊息機制。
Handler機制是谷歌單執行緒模型的伴生產物,就是為了解決“子執行緒需要執行耗時任務”和“主執行緒不允許耗時且必須負責UI更新”這兩者之間執行緒的矛盾問題而出現的。
Handler機制的核心點就是Looper、MessageQueue、Handler三者的鐵三角組成。
這套規則是如何形成閉環的
前面兩節已經詳細描述了UI執行緒推出的原因以及伴隨UI執行緒引出的新的機制:Handler訊息機制,那麼就來用如下圖所示來描述整個規則閉環的構成:
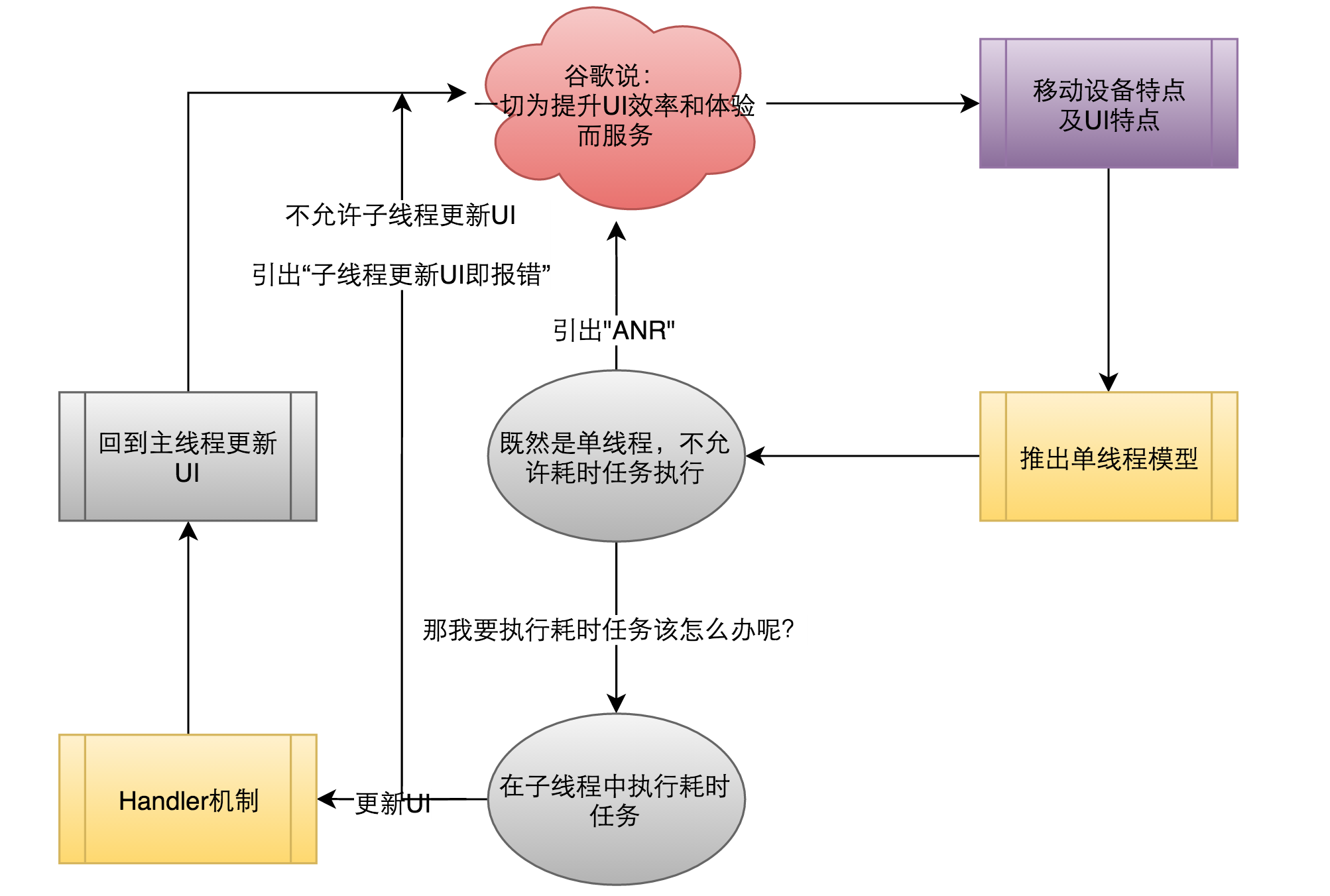
在如上的閉環圖描述中,給出了單執行緒模型和Handler機制推行的原因。同時也提出了為什麼會引出"ANR"錯誤和“子執行緒更新UI即報錯”。
Handler機制是用於執行緒切換任務執行的;單執行緒模型是為了有效提高UI體驗和效率;兩者最終都是從UI角度和移動裝置角度出發來考慮的。
該機制的細節有哪些
論述完前面的內容,接下來就來詳細拆分一下這套規則、這套handler機制背後的一些細節佈置,將描述以下幾個細節:
(1)Handler機制相關細節
既然是單執行緒模型,那就必須詳細瞭解一下Handler機制。
handler機制的核心三要素:Handler、Looper、MessageQueue
Handler:
這玩意存在的目的就在於實現執行緒間的工作切換,將一個任務從一個執行緒中切換到另一個執行緒去執行,我在讀《Android開發藝術探索》一書中認為作者使用“切換”一詞的用意很到位。當我們在子執行緒中執行完耗時任務時,通過使用handler,來讓程式碼邏輯切換到主執行緒中,完成UI的更新。看一下Handler原始碼:
public Handler() {
this(null, false);
} 上面的構造方法是我們最常使用的構造方法了(啥也不用填總是挺舒服的),在該方法中呼叫了另一個構造方法:
public Handler(Callback callback, boolean async) {
if (FIND_POTENTIAL_LEAKS) {
final Class<? extends Handler> klass = getClass();
if ((klass.isAnonymousClass() || klass.isMemberClass() || klass.isLocalClass()) &&
(klass.getModifiers() & Modifier.STATIC) == 0) {
Log.w(TAG, "The following Handler class should be static or leaks might occur: " +
klass.getCanonicalName());
}
}
mLooper = Looper.myLooper();
if (mLooper == null) {
throw new RuntimeException(
"Can't create handler inside thread that has not called Looper.prepare()");
}
mQueue = mLooper.mQueue;
mCallback = callback;
mAsynchronous = async;
}這才是真正實現Handler的地方之一,其實裡面的邏輯可以拆分成三個部分:
a.Handler類的構建宣告
b.獲取Looper
c.Handler賦值
看第一部分:
if (FIND_POTENTIAL_LEAKS) {
final Class<? extends Handler> klass = getClass();
if ((klass.isAnonymousClass() || klass.isMemberClass() || klass.isLocalClass()) &&
(klass.getModifiers() & Modifier.STATIC) == 0) {
Log.w(TAG, "The following Handler class should be static or leaks might occur: " +
klass.getCanonicalName());
}
}這一部分邏輯其實是控制Handler類的構建。我們一般在使用Handler的時候都會建立一個自定義繼承自Handler的本地類,這個時候需宣告此類為static,且不說匿名類、不是內部類,具有static修飾符。否則,將會提示出會有記憶體洩漏的風險存在。
看第二部分:
mLooper = Looper.myLooper();從Looper中拿到looper物件。我們知道執行緒是程式碼邏輯執行的最小環境,而每一個Looper都會繫結到一個執行緒中去。恰好,咱們的單執行緒模型依託主執行緒,所以可以需要一個Looper去繫結,具體的繫結後續介紹。那麼Handler服務於執行緒切換,所依託的訊息機制必然需要一個Looper,如果此執行緒都沒事先實現Looper的繫結,那麼在這個執行緒裡建立Handler也會導致失敗的。如下:
if (mLooper == null) {
throw new RuntimeException(
"Can't create handler inside thread that has not called Looper.prepare()");
}看第三部分:
mQueue = mLooper.mQueue;
mCallback = callback;
mAsynchronous = async;當獲取了所線上程中的looper之後,為Handler的一系列成員變數賦值了就。最主要的就是拿到Looper內部維護的訊息佇列mQueue了。這樣才可以把自己手裡的訊息從外部傳遞給另一個執行緒中,然後執行對應操作。
callback是什麼呢?
關於callback會在Looper當中去介紹更合適。先預留一下這個玩意。
Looper:
Looper是在Handler機制中與Thread密不可分的關鍵元素(拋開Handler機制就不管它了)
首先了解一下線上程中建立Looper的邏輯,這裡使用HandlerThread的程式碼為例:
@Override
public void run() {
mTid = Process.myTid();
Looper.prepare();
synchronized (this) {
mLooper = Looper.myLooper();
notifyAll();
}
Process.setThreadPriority(mPriority);
onLooperPrepared();
Looper.loop();
mTid = -1;
}在Thread的回撥方法run中建立Looper,其核心點有兩處,分別是Looper.prepare()和Looper.loop()。
完成以上兩步之後就建立好了Looper,並使得Thread開始執行時啟動Looper的訊息迴圈。
看一下Looper的prepare方法:
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}首先從sThreadLocal裡獲取looper物件,如果獲取到了就會報出異常,不然的話就可以執行set方法了,將新建的一個looper方法塞給了sThreadLocal。這裡為什麼要這樣的程式碼設計呢?
這樣設計的好處就在於此靜態方法只會呼叫一次,因為set方法必然會執行(如過prepare方法執行完的話),但是一個執行緒只能有一個Looper,所以這樣的設計其實也算是“單例”實現的一種吧。
這裡還要提一下關於sThreadLocal,這個玩意兒是一個ThreadLocal型別,這個型別是以執行緒為作用域的,實現以執行緒為單位各自資料的儲存和獲取,執行緒間不會影響:
// sThreadLocal.get() will return null unless you've called prepare().
static final ThreadLocal<Looper> sThreadLocal = new ThreadLocal<Looper>();具體ThreadLocal是如何實現以執行緒為作用域的資料儲存而執行緒相互之間做到不影響的呢?後續其他的文章會專門描述,可以提一下,其實每個執行緒類Thread裡也有一個全域性變數:
ThreadLocal.Values localValues這個localValues綁定了ThreadLocal的set方法和get方法,所以實際上set和get方法結合了Thread的接應,完成了以執行緒為單位的資料獲取與儲存。
講完了prepare,再來看一下Looper.loop方法:
/**
* Run the message queue in this thread. Be sure to call
* {@link #quit()} to end the loop.
*/
public static void loop() {
final Looper me = myLooper();
if (me == null) {
throw new RuntimeException("No Looper; Looper.prepare() wasn't called on this thread.");
}
final MessageQueue queue = me.mQueue;
// Make sure the identity of this thread is that of the local process,
// and keep track of what that identity token actually is.
Binder.clearCallingIdentity();
final long ident = Binder.clearCallingIdentity();
for (;;) {
Message msg = queue.next(); // might block
if (msg == null) {
// No message indicates that the message queue is quitting.
return;
}
// This must be in a local variable, in case a UI event sets the logger
Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
msg.target.dispatchMessage(msg);
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
// Make sure that during the course of dispatching the
// identity of the thread wasn't corrupted.
final long newIdent = Binder.clearCallingIdentity();
if (ident != newIdent) {
Log.wtf(TAG, "Thread identity changed from 0x"
+ Long.toHexString(ident) + " to 0x"
+ Long.toHexString(newIdent) + " while dispatching to "
+ msg.target.getClass().getName() + " "
+ msg.callback + " what=" + msg.what);
}
msg.recycleUnchecked();
}
}loop方法很長,但是實際上需要關注的點就是for(;;)裡面的邏輯,在執行這樣一個死迴圈之後,每次迴圈都會搜尋MessageQueue裡面的內容,檢視是否會有新的message,如果有,就拿出來,執行以下方法:
msg.target.dispatchMessage(msg);msg.target屬性就是handler,畢竟訊息都是handler傳遞過來的嘛。
看一下handler是如何傳遞訊息的:
public final boolean sendMessage(Message msg)
{
return sendMessageDelayed(msg, 0);
}往下繼續呼叫,呼叫到sendMessageAtTime之後進入enqueueMessage的如下方法:
private boolean enqueueMessage(MessageQueue queue, Message msg, long uptimeMillis) {
msg.target = this;
if (mAsynchronous) {
msg.setAsynchronous(true);
}
return queue.enqueueMessage(msg, uptimeMillis);
}在這個方法裡對target屬性賦值,就是handler自己。
為什麼要用target呢? 我認為這樣的設計是為了解耦,降低耦合性。
那麼looper在loop方法裡重新讓hander執行dispatchMessage方法是意欲何為呢?看一下dispatchMessage方法:
public void dispatchMessage(Message msg) {
if (msg.callback != null) {
handleCallback(msg);
} else {
if (mCallback != null) {
if (mCallback.handleMessage(msg)) {
return;
}
}
handleMessage(msg);
}
}在上面的程式碼邏輯裡,首先判斷callback是否為空,若不為空就執行handleCallback方法;若為空,則執行handleMessage方法,這個方法就是我們熟悉handler回撥方法了,至此將後續邏輯切換到了Handler所線上程當中去執行了。
我們來回顧一下之前提出的問題,handler的構造方法裡為啥會有個callback。其實這要歸宿到handler派發訊息除了sendMessage之外的另一種姿勢:post
public final boolean post(Runnable r)
{
return sendMessageDelayed(getPostMessage(r), 0);
}我們可以new一個Runnable作為post方法的引數,然後handler會自動將這個Runnable物件包裝成一個Message:
private static Message getPostMessage(Runnable r) {
Message m = Message.obtain();
m.callback = r;
return m;
}這樣的話,loop裡的回撥方法就不是handleMessage而是我們自己建立Runnable時覆寫的run方法了。
這就是msg及handler要有callback的原因。
我們之前也提到過,“切換”是handler存在的意義,如果有兩個執行緒,Thread1和Thread2,我們完全可以在Thread1中建立一個Handler,但是使用的構造方法是帶參Looper的:
public Handler(Looper looper) {
this(looper, null, false);
}這個looper完全可以顯式的使用Thread2中的looper,這樣在Thread1中的操作就可以切換到Thread2中去了。具體可以參看HandlerThread的使用姿勢。
MesssageQueue:
講完了Handler和Looper,MessageQueue就顯而易見了。只是一個訊息佇列而已,內部採用單鏈表的資料結構來實現和維護。
(2)主執行緒入口
都說UI執行緒、主執行緒,問問誰誰誰這個主執行緒叫啥,好像初入android的都不知道。
其實這個主執行緒叫ActivityThread。而app的入口如果除去launcher這個程序和AMS的話,以app為單位,入口就是ActivityThread的main方法:
public static void main(String[] args) {
SamplingProfilerIntegration.start();
// CloseGuard defaults to true and can be quite spammy. We
// disable it here, but selectively enable it later (via
// StrictMode) on debug builds, but using DropBox, not logs.
CloseGuard.setEnabled(false);
Environment.initForCurrentUser();
// Set the reporter for event logging in libcore
EventLogger.setReporter(new EventLoggingReporter());
Security.addProvider(new AndroidKeyStoreProvider());
// Make sure TrustedCertificateStore looks in the right place for CA certificates
final File configDir = Environment.getUserConfigDirectory(UserHandle.myUserId());
TrustedCertificateStore.setDefaultUserDirectory(configDir);
Process.setArgV0("<pre-initialized>");
Looper.prepareMainLooper();
ActivityThread thread = new ActivityThread();
thread.attach(false);
if (sMainThreadHandler == null) {
sMainThreadHandler = thread.getHandler();
}
if (false) {
Looper.myLooper().setMessageLogging(new
LogPrinter(Log.DEBUG, "ActivityThread"));
}
Looper.loop();
throw new RuntimeException("Main thread loop unexpectedly exited");
}這個main方法是一個靜態方法,任務就是初始化主執行緒ActivityThread,並且啟動looper.loop:
ActivityThread thread = new ActivityThread();Looper.loop();在初始化ActivityThread的時候就初始化好mainLooper了。
(3)子執行緒更新UI報錯
我們知道在進行子執行緒更新的時候會報錯。
實際上各自UI控制元件都是最終派生自View,而UI的繪製離不開ViewRootImpl這個類,在這個類中實現了執行緒檢查:
void checkThread() {
if (mThread != Thread.currentThread()) {
throw new CalledFromWrongThreadException(
"Only the original thread that created a view hierarchy can touch its views.");
}
}但是ViewRootImpl的初始化完成在handleResumeActivity方法中:
final void handleResumeActivity(...){
//省略
if (r.activity.mVisibleFromClient) {
r.activity.makeVisible();
}
//省略
}進入到makeVisible方法:
void makeVisible() {
if (!mWindowAdded) {
ViewManager wm = getWindowManager();
wm.addView(mDecor, getWindow().getAttributes());
mWindowAdded = true;
}
mDecor.setVisibility(View.VISIBLE);
}在makeVisible方法裡,建立了一個WindowManager,而WindowManager的具體實現類是WindowManagerGlobal,所以進入到該類中可以找到addView的具體實現,在其中,我們可以找到ViewRootImpl的初始化:
root = new ViewRootImpl(view.getContext(), display);所以,當Resume方法執行完成之後就不能在子執行緒中更新UI了,但是可以在onCreate方法中(onResume方法執行完成之前),使用子執行緒更新UI。
這套規則的優勢和劣勢有哪些
在上一節裡,詳細再詳細的描述了整套UI規則背後承載的機制細節,那麼谷歌使用這套規則和機制,到底有什麼優勢和劣勢呢?
這裡本人也是簡單想了下,首先優勢我認為有以下幾個點:
1.UI使用效率得到提高;
2.UI體驗得到提高;
3.針對當前的裝置特點和產品特徵,具有一定的友好性和使用可行性;
4.輕量級;
那麼缺點呢?
1.在一個執行緒內充斥著各種邏輯難免會過於複雜,可維護行和擴充套件性有待商榷;
2.如果解決了多執行緒的一些弊端,可能多執行緒帶來的效率提升會高一些;
3.硬體在提升,技術在提升,新的系統以及在開發了,so?
所以,任何一個機制、規則的誕生都離不開一系列的需求背景和當前條件的限制,那麼如果一個個瓶頸被突破之後,技術也會持續改革和更新吧。
這套規則未來可能的前景有哪些
相信你們的意見會更好的。
反正我覺得谷歌在研究新系統已經想表達他們對android一些已經成型的機制的無奈了。如果推到重來,還不如投入更多的精力研發一個更好的系統呢。
以上就是對UI執行緒這個大眾所知的概念進行的一些研究和理解,如果有什麼興趣,可以聯絡:
QQ:526315041
微信:526315041
部落格:木有
電話:木有
地點:上海市長寧區