
Scrapy 框架簡介 抓取一點資訊
什麼是scrapy ?
1 Scrapy是用純Python實現一個為了爬取網站資料、提取結構性資料而編寫的應用框架,用途非常廣泛
2 Scrapy 使用了 Twisted['twɪstɪd](其主要對手是Tornado)非同步網路框架來處理網路通訊
3 Scrapy非常的靈活 ,我們可以自己修改一些引數,或者是自己寫程式碼豐富,非常的方便這張圖片是scrapy的流程圖,開始看可能感覺 什麼鬼,但是瞭解它的工作方式後,並不是那麼的難以理解。

-
Scrapy Engine(引擎): 負責Spider、ItemPipeline、Downloader、Scheduler中間的通訊,訊號、資料傳遞等。 -
Scheduler(排程器): 它負責接受引擎傳送過來的Request請求,並按照一定的方式進行整理排列,入隊,當引擎需要時,交還給引擎。 -
Downloader(下載器):負責下載Scrapy Engine(引擎)傳送的所有Requests請求,並將其獲取到的Responses交還給Scrapy Engine(引擎),由引擎交給Spider來處理, -
Spider(爬蟲):它負責處理所有Responses,從中分析提取資料,獲取Item欄位需要的資料,並將需要跟進的URL提交給引擎,再次進入Scheduler(排程器), -
Item Pipeline(管道):它負責處理Spider中獲取到的Item,並進行進行後期處理(詳細分析、過濾、儲存等)的地方. -
Downloader Middlewares(下載中介軟體):你可以當作是一個可以自定義擴充套件下載功能的元件。 -
Spider Middlewares(Spider中介軟體):你可以理解為是一個可以自定擴充套件和操作引擎和Spider中間通訊的功能元件(比如進入Spider的Responses;和從Spider出去的Requests)
Scrapy的安裝
關於 Windows 和 linux 的安裝 可以根據自己的作業系統進行安裝,搜尋一下其他安裝部落格,很多。我這就跳過
新建專案的簡介 (linux作業系統為例)
當我們安裝好scrapy 時候,我們可以通過命令快速的建立一個爬蟲專案
scrapy startproject Spider_name >>>> (Spider_name為你的爬蟲專案名稱,可根據自己專案要求取名)
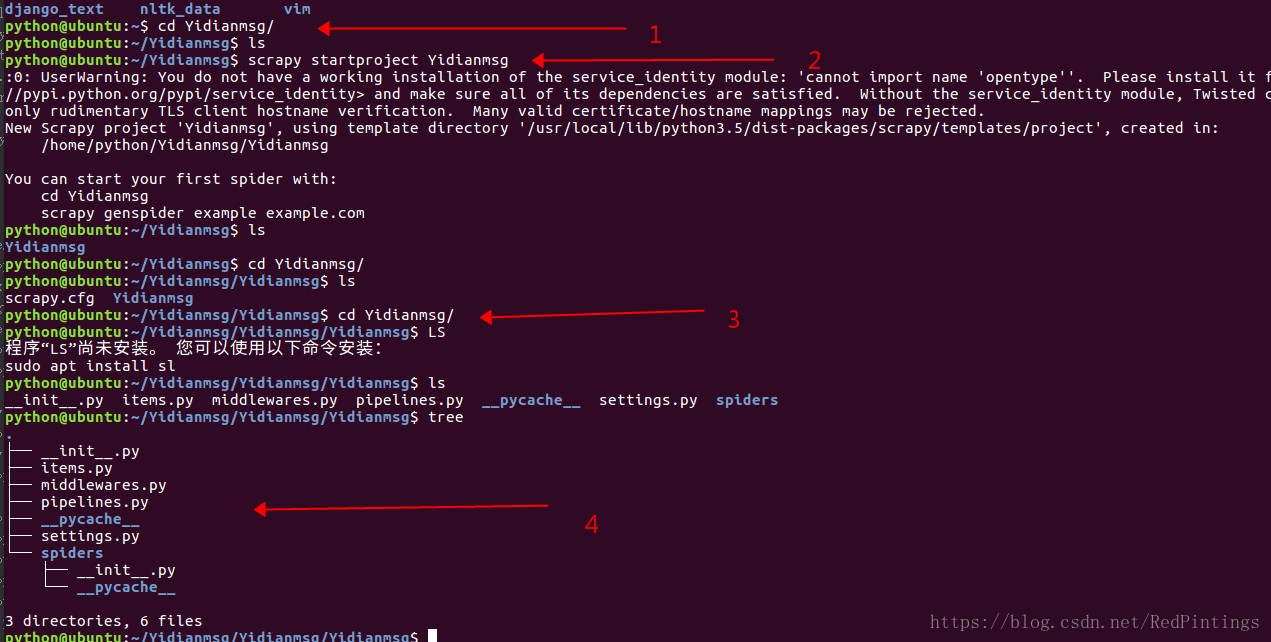
第一步 新建一個資料夾
第二步 我們通過命令新建一個爬蟲專案
第三步 我們cd 到這個專案中去
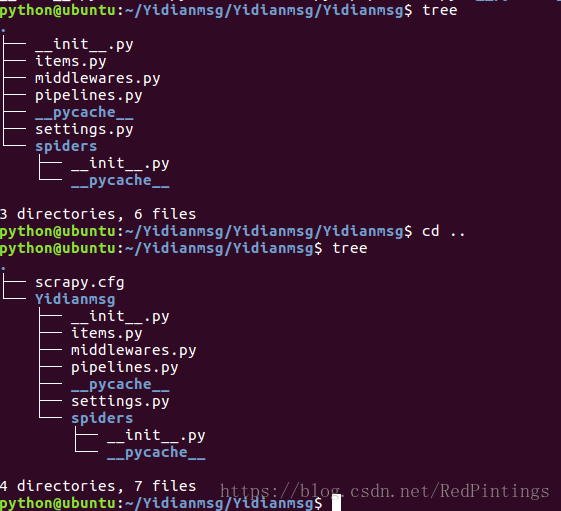
第四步 我們tree一下看看專案的目錄結構
發現這個架構的起始檔案就這麼幾個,他們的具體是做什麼用的:
scrapy.cfg :專案的配置檔案 可以掛載專案到伺服器
Yidianmsg/ :專案的Python模組
items.py :專案的目標檔案 這裡主要是定義我們要抓取的欄位
pipelines.py :專案的管道檔案 這裡主要是檔案的儲存,以及其他的一些處理
settings.py :專案的設定檔案 這裡是專案的一些配置檔案
spiders/ :儲存爬蟲程式碼目錄 這裡使我們寫爬蟲程式碼的地方,
專案新建完成了,但是spider目錄裡面是空的,我們怎麼快速的建立一個爬蟲,這裡scrapy也提供了快捷鍵
當然了,也可以自己寫,但是我更喜歡用命令直接建立,方便快捷,何樂不為。
scrapy有兩個爬蟲類 他們的建立方式不同
scrapy genspider spider_name xx.com # spider_name 是你爬蟲名字,xx.com 允許爬蟲爬取的域名
scrapy genspider -t crawl spider_name xxxx.com # 名稱 和域名範圍 快速建立命令
我們這裡只說第一個spider類,也就是第一條命令,關於第二條命令 crawlspider有興趣的課去查下,它的爬取速度更快,行為更為粗暴
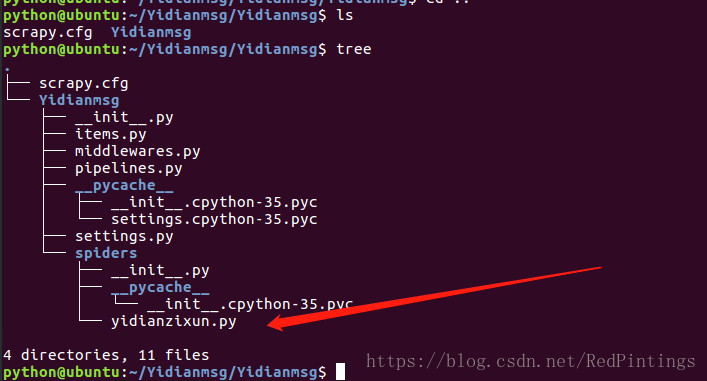
專案和爬蟲都建立完畢後我們會發現,spiders檔案下多了一個爬蟲檔案,這是我們寫爬蟲的地方 名字為 yidianzixun.py
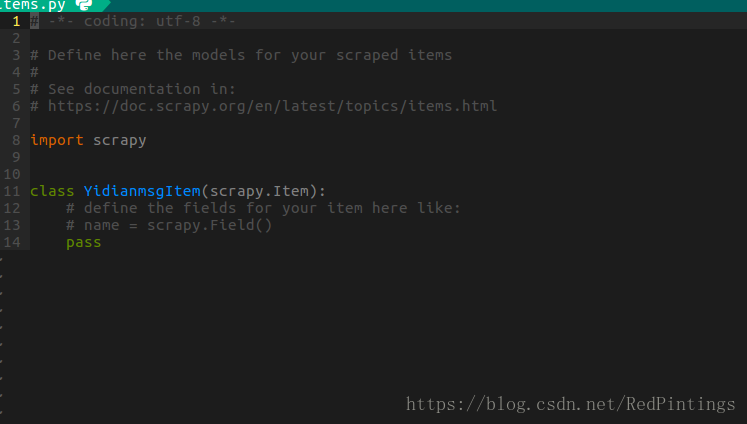
items.py 可以定義我們的爬取欄位
pipelines.py 檔案儲存路徑
import something
class SomethingPipeline(object):
def __init__(self):
# 可選實現,做引數初始化等
# doing something
def process_item(self, item, spider):
# item (Item 物件) – 被爬取的item
# spider (Spider 物件) – 爬取該item的spider
# 這個方法必須實現,每個item pipeline元件都需要呼叫該方法,
# 這個方法必須返回一個 Item 物件,被丟棄的item將不會被之後的pipeline元件所處理。
return item
def open_spider(self, spider):
# spider (Spider 物件) – 被開啟的spider
# 可選實現,當spider被開啟時,這個方法被呼叫。
def close_spider(self, spider):
# spider (Spider 物件) – 被關閉的spider
# 可選實現,當spider被關閉時,這個方法被呼叫spider
檔案裡面的 .py檔案是寫爬蟲的檔案,name是爬蟲的名稱,allowed_domains允許的爬取域名,start_urls是起始url
裡面的parse方法 是第一個回撥函式(注意用crawlspider不能使用parse方法,原始碼中已經實現parse方法,重寫會覆蓋)
middlewares.py
這裡是書寫中介軟體的地方,這裡的作用是下載器和引擎中間的鉤子。在settings.py開啟後我們傳送的請求會經過這裡,我們可以做一些處理,比如可以在這裡加ip代理,user-agent等 可以參考以下圖中例項
settings.py 常用設定
自上往下 【 user_agent ,自行設定】【是否遵守robots協議】【請求併發量,預設為16,可根據頻寬自行調解】
【下載延遲,防止爬蟲被網站遮蔽】【cookie】【新增預設的頭部資訊】【啟用中介軟體】【啟用pipeline】

下邊我們以一點資訊為例 帶來一個scrpy 爬蟲例項
注:(程式碼僅作參考,有一些引用自寫工具類卻沒有貼出來)
items.py
import scrapy
class YidianspiderItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
channel = scrapy.Field()
title = scrapy.Field()
item_type = scrapy.Field()
create_type = scrapy.Field()
original_url = scrapy.Field()
body = scrapy.Field()
images = scrapy.Field()
spider
# -*- coding: utf-8 -*-
# @Time : 18-5-23 下午2:10
# @Author : 楊星星
# @Email : [email protected]
# @File : YidianSpider
# @Software: PyCharm
import logging
import scrapy
import re
from YidianSpider.items import YidianspiderItem
from YidianSpider.MyUtils import Util
class YidianSpider(scrapy.Spider):
name = 'yidian'
allowed_domains = ['yidianzixun.com']
start_urls = ['http://yidianzixun.com/']
child_channel_dicts = {"育兒":['t10449','e212806','t9651','u7916','u9392','u7934','e1595662','u7744','e268214','t19398','u7682','t10447','u7699']}
emotion_channel_dicts = {"情感":['u141','u9384','u575','u9387','u338','e2654','e288452','e929007','e158508','t9436','u655']}
headers = {
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1",
"Referer": "http://www.yidianzixun.com/",
}
def parse(self,response):
for channel, ids in self.child_channel_dicts.items():
for id in ids:
print('---id----', id)
url = "http://www.yidianzixun.com/channel/" + str(id)
yield scrapy.Request(url=url, callback=self.parse_page_links,headers=self.headers, meta={"channel": channel})
def parse_page_links(self,response):
channel = response.meta['channel']
# print(channel)
# url = response.url
response_html = response.body.decode('utf-8')
article_links = re.findall(r'href="(.*?)"',response_html)
for article_link in article_links:
if 'article' in article_link:
article_url = "http://www.yidianzixun.com" + str(article_link)
print('--flag1---url----',article_url)
yield scrapy.Request(url=article_url,callback=self.parse_article_detail,meta={"channel": channel},headers=self.headers)
else:
continue
def parse_article_detail(self,response):
channel = response.meta['channel']
item = YidianspiderItem()
# class="doc-source">福建吃喝玩樂</ <div class="source imedia">福建吃喝玩樂</div><
name = re.findall(r'<div class="source imedia">(.*?)</div>', response.body.decode('utf-8'))[0]
title = re.findall(r'<h3>(.*?)</h3>', response.body.decode('utf-8'))[0]
OriginalBody = re.findall(r'<body>(.*?)</body>', response.body.decode('utf-8'))[0]
NeedRepImageUrls = re.findall(r'"url":"(.*?)"', re.findall(r'"images":\[(.*?)\]', response.body.decode('utf-8'))[0])
BodyFlags = re.findall(r'<div id="article-img-\d+"class="a-image" .*?></div>', response.body.decode('utf-8'))
if '.mp4' in OriginalBody:
print('>>>----視訊資源---PASS--')
return
else:
rep_body = OriginalBody
for flag, image in zip(BodyFlags, NeedRepImageUrls):
rep_body = rep_body.replace(flag, '<img src="http:' + image + '">')
RemoveBodyId = re.sub(r'id=".*?"', '', rep_body)
RemoveBodyClass = re.sub(r'class=".*?"', '', RemoveBodyId)
ImageUrl = re.findall(r'src="(.*?)"', RemoveBodyClass)
item['image_urls'] = ImageUrl
try:
tag = Util.get_tags_by_jieba(RemoveBodyClass)
if tag:
tag.append(channel)
item['tag'] = tag
except Exception as error:
logging.info(error,'---tag--error--')
return
if title:
item['title'] = title
else:
return
try:
Temp_Content = RemoveBodyClass
for content_img_url in ImageUrl:
content_url_temp = Util.generate_pic_time_yidian_lazy(content_img_url)
Temp_Content = Temp_Content.replace(content_img_url, content_url_temp)
item['body'] = Temp_Content
except Exception as e:
print(e)
logging.info('----BODY---ERROR--')
return
try:
item['images'] = []
data_echo_url = re.findall(r'data-echo="(.*?)"', item['body'])
for num, image_url in enumerate(data_echo_url):
temp_image_url = Util.generate_pic_time_yd(image_url) + '.jpg'
image_dict = {"index": num, "url": temp_image_url, "title": ""}
item['images'].append(image_dict)
except Exception as e:
print('---ERROR---', e, '--IMAGES---ERROR---')
logging.info('---IMAGES--ERROR---')
return
item['channel'] = channel
item['source'] = '一點號'
if name:
item['name'] = name
else:
item['name'] = '一點號'
item['original_url'] = response.url
if not item['body']:
return
if len(item['body']) < 200:
return
CheckItem = Util.check_item(item)
print('---',CheckItem ,'---')
if CheckItem == 1:
return
yield item
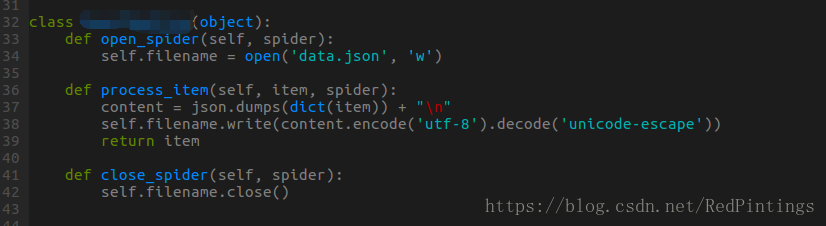
pipeline.py
import json
class NewsPipeline(object):
def open_spider(self, spider):
self.filename = open('data.json', 'w')
def process_item(self, item, spider):
content = json.dumps(dict(item)) + "\n"
self.filename.write(content.encode('utf-8').decode('unicode-escape'))
return item
def close_spider(self, spider):
self.filename.close()
settings.py
# -*- coding: utf-8 -*-
# Scrapy settings for YidianSpider project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'YidianSpider'
SPIDER_MODULES = ['YidianSpider.spiders']
NEWSPIDER_MODULE = 'YidianSpider.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 16
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 2
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'YidianSpider.middlewares.YidianspiderSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'YidianSpider.middlewares.YidianspiderDownloaderMiddleware': 543,
}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'YidianSpider.pipelines.YidianspiderPipeline': 300,
}
相關推薦
Scrapy 框架簡介 抓取一點資訊
什麼是scrapy ? 1 Scrapy是用純Python實現一個為了爬取網站資料、提取結構性資料而編寫的應用框架,用途非常廣泛 2 Scrapy 使用了 Twisted['twɪstɪd](其主要對手是Tornado)非同步網路框架來處理網路通訊3 Scrapy非常的靈
使用scrapy框架進行抓取伯樂線上所有文章(一)
這是跟著相關視訊學習進行的程式碼,(一)學習思路的程式碼在整個完整程式碼中存在一部分,如果看到這些內容或思路有不懂的給我下面部落格留言。完整程式碼github地址:https://github.com/spider-liu/jobbole-,主要是作為學習交流之用。 一、scrapy框架簡介
python 爬蟲 如何通過scrapy框架簡單爬取網站資訊--以51job為例
Scrapy框架三大優點: Scrapy框架是用純Python實現一個為了爬取網站資料、提取結構性資料而編寫的應用框架,用途非常廣泛。 框架的力量,使用者只需要定製開發幾個模組就可以輕鬆的實現一個爬蟲,用來抓取網頁內容以及各種圖片,非常之方便。 Scrapy
爬蟲框架Scrapy實戰之批量抓取招聘資訊--附原始碼
瞭解更多Python爬蟲內容請微信公眾號關注:Python技術博文 所謂網路爬蟲,就是一個在網上到處或定向抓取資料的程式,當然,這種說法不夠專業,更專業的描述就是,抓取特定網站網頁的HTML資料。不過由於一個網站的網頁很多,而我們又不可能事先知道所有網頁的URL地址
【爬蟲】Scrapy爬蟲框架教程-- 抓取AJAX非同步載入網頁
前一段時間工作太忙一直沒有時間繼續更新這個教程,最近離職了趁著這段時間充裕趕緊多寫點東西。之前我們已經簡單瞭解了對普通網頁的抓取,今天我就給大家講一講怎麼去抓取採用Ajax非同步加的網站。 工具和環境 語言:python 2.7 IDE: Pycharm 瀏覽器:Ch
scrapy爬蟲框架(一):scrapy框架簡介
一、安裝scrapy框架 #開啟命令列輸入如下命令: pip install scrapy 二、建立一個scrapy專案 安裝完成後,python會自動將 scrapy命令新增到環境變數中去,這時我們就可以使用 scrapy命令來建立我們的第一個 scrapy專案了。
scrapy框架爬蟲爬取糗事百科 之 Python爬蟲從入門到放棄第不知道多少天(1)
Scrapy框架安裝及使用 1. windows 10 下安裝 Scrapy 框架: 前提:安裝了python-pip 1. windows下按住win+R 輸入cmd 2. 在cmd 下 輸入 pip install scrapy pip inst
scrapy框架簡介和配置使用
scrapy框架的簡介和基礎使用 概念:為了爬取網站資料而編寫的一款應用框架。框架其實就是一個集成了相應的功能且具有很強通用性的專案模板。 安裝: 1. linux mac os:pip install scrapy 直接pip就能安裝完成 2. win:安裝比較麻煩,按下面步驟
爬蟲-scrapy框架簡介和基礎應用
一.什麼是Scrapy? Scrapy是一個為了爬取網站資料,提取結構性資料而編寫的應用框架,非常出名,非常強悍。所謂的框架就是一個已經被集成了各種功能(高效能非同步下載,佇列,分散式,解析,持久化等)的具有很強通用性的專案模板。對於框架的學習,重點是要學習其框架的特性、各個功能的用法即可。 二.安裝
Python網路爬蟲之抓取訂餐資訊
本文以大眾點評網為例,獲取頁面的餐館資訊,以達到練習使用python的目的。 1.抓取大眾點評網中關村附近的餐館有哪些 import urllib.request import re def fetchFood(url):
用python 通過12306api抓取列車資訊
PS:本文為學習參考例項。程式碼與上述大體相同。 首先了解這些查詢介面是怎麼來的 chrome是個好東西,特別是它的控制檯能看到很多細節。 12306網站通過chrome可以看到查詢票的api 其中有log? 和 queryA?兩種開頭的介面
(六--一)scrapy框架簡介和基礎應用
一 什麼是scrapy框架 官方解釋 Scrapy是一個為了爬取網站資料,提取結構性資料而編寫的應用框架。 可以應用在包括資料探勘,資訊處理或儲存歷史資料等一系列的程式中。 其最初是為了 頁面抓取 (更確切來說, 網路抓取 )所設計的, 也可以應用在獲取API所返回的資料(例如 Amazon
Python利用scrapy框架,爬取大眾點評部分商鋪資料~
分享一下,自己從0開始,用python爬取資料的歷程。希望可以可以幫到一起從0開始的小夥伴~~加油。首先,我的開發環境是:電腦:macOS Sierra 10.12.6 編譯器:PyCharm + 終端我的電腦自帶的Python版本為2.7,我下載了一個Python3.6。使
python網路爬蟲--抓取股票資訊到Mysql
1.建表mysql -u root -p 123456create database test default character set utf8;create table stocks --a股( code varchar(10) comment '程式碼', nam
爬蟲requests庫簡單抓取頁面資訊功能實現(Python)
import requests import re, json,time,random from requests import RequestException UserAgentList = [ "Mozilla/5.0 (Windows NT 6.1; WO
10.scrapy框架簡介和基礎應用
今日概要 scrapy框架介紹 環境安裝 基礎使用 今日詳情 一.什麼是Scrapy? Scrapy是一個為了爬取網站資料,提取結構性資料而編寫的應用框架,非常出名,非常強悍。所謂的框架就是一個已經被集成了各種功能(高效能非同
(PHP)用cURL抓取網頁資訊並替換部分內容
<?php /** * 用cURL抓取網頁資訊並替換部分內容 * User: Ollydebug * Date: 2015/11/11 * Time: 19:13 */ $curlo
scrapy框架簡介和基礎應用
一.什麼是Scrapy? Scrapy是一個為了爬取網站資料,提取結構性資料而編寫的應用框架,非常出名,非常強悍。所謂的框架就是一個已經被集成了各種功能(高效能非同步下載,佇列,分散式,解析,持久化等)的具有很強通用性的專案模板。對於框架的學習,重點是要學習其框架的特性、各個功能的用法即可。 二.安裝
(python解析js)scrapy結合ghost抓取js生成的頁面,以及js變數的解析
現在頁面用ajax的越來越多, 好多程式碼是通過js執行結果顯示在頁面的(比如:http://news.sohu.com/scroll/,搜狐滾動新聞的列表是在頁面請求時由後臺一次性將資料渲染到前臺js變數newsJason和arrNews裡面的,然後再由js生
Python3抓取頁面資訊,網路程式設計,簡單傳送QQ郵件
資料收集,資料整理,資料描述,資料分析 # coding=utf-8 import sys import urllib.request req = urllib.request.Request(