
大資料基礎架構方案
大資料架構方案,主要包括整個大資料的軟體棧,主要功能包括:資料抽取,資料儲存,資料分析,資料探勘
下面是整個架構設計圖:
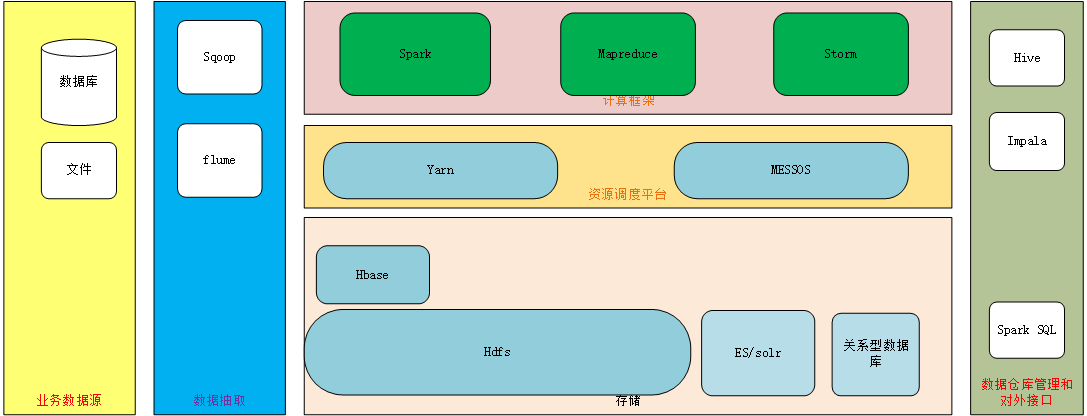
資料抽取
關係型資料庫,通過sqoop匯入
日誌檔案通過flume匯入資料儲存
採用hdfs,hbase等為資料儲存的主體
對於文字檢索則採用es/solr等搜尋技術
分析後的結果資料可以採用關係型資料庫儲存資料分析
採用spark,mapreduce,storm等計算框架分析
批處理:spark,mapreduce
流式處理:spark,storm資料探勘
採用 spark MLIB,mathout等進行資料建模分析資料查詢
利用hive元資料來建立資料倉庫檢視,通過hive thirft,impala, spark SQL等提供JDBC/ODBC介面供報表展示工具查詢
通過以上架構,實現大資料應用的落地,大資料的目標還是為了提高業務能力,通過大資料架構帶來的技術變革,提升資料價值,改革業務模式,才是大資料的紅利
相關推薦
大資料基礎架構方案
大資料架構方案,主要包括整個大資料的軟體棧,主要功能包括:資料抽取,資料儲存,資料分析,資料探勘 下面是整個架構設計圖: 資料抽取 關係型資料庫,通過sqoop匯入 日誌檔案通過flume匯入 資料儲存 採用hdfs,hbase等為資料儲存的主體
大資料-平臺-解決方案-基礎架構一覽
排名不分先後:哈哈 1、talkingdata (資料平臺) 2、明略資料(解決方案) 3、百融金服(金融大資料) 4、國雙科技(營銷大資料) 5、國信優易(媒體大資料) 6、百分點(營銷大資料) 7、華院集團(解決方案) 8、個推(資料平臺) 9、奧維雲網(資料平臺)
大資料基礎(1)zookeeper原始碼解析
五 原始碼解析 public enum ServerState { LOOKING, FOLLOWING, LEADING, OBSERVING;}zookeeper伺服器狀態:剛啟動LOOKING,follower是FOLLOWING,leader是LEADING,observer是
大資料基礎之Oozie vs Azkaban
概括: Azkaban是一個非常輕量的開源排程框架,適合二次開發,但是無法直接用於生產環境,存在致命缺陷(比如AzkabanWebServer是單點,1年多時間沒有修復),在一些情景下的行為簡單粗暴(比如重啟AzkabanExecutorServer會導致該server上正在執行的所有流程fail),很多時
大資料基礎之Quartz(1)簡介、原始碼解析
一簡介 官網 http://www.quartz-scheduler.org/ What is the Quartz Job Scheduling Library? Quartz is a richly featured, open source job scheduling libra
大資料基礎概論
一、大資料概念 1.大資料的定義: 指無法在一定時間範圍內用常規軟體工具進行捕捉、管理和處理的資料集合,是需要新處理模式才能具有更強的決策力、洞察發現力和流程優化能力的海量、高增長率和多樣化的資訊資產。補充:主要解決,海量資料的儲存和海量資料的分析計算問題。 2.資料的單位:
大資料 基礎概念
前言 大資料 基礎概念 大資料 Centos基礎 大資料 Shell基礎 大資料 ZooKeeper 大資料 Hadoop介紹、配置與使用 大資料 Hadoop之HDFS 大資料 MapReduce 大資料 Hive 大資料 Y
大資料基礎之Kafka(1)簡介、安裝及使用
http://kafka.apache.org 一 簡介 Kafka® is used for building real-time data pipelines and streaming apps. It is horizontally scalable,&nb
大資料基礎之Spark(1)Spark Submit即Spark任務提交過程
Spark版本2.1.1 一 Spark Submit本地解析 1.1 現象 提交命令: spark-submit --master local[10] --driver-memory 30g --class app.package.AppClass app-1
大資料基礎必備,大資料是什麼?
隨著網際網路時代的到來,顛覆了傳統行業的盈利模式,大家都把注意力集中在了網際網路上。前幾年大資料時代的來臨,為各行各業提供了更加開闊的資料用作分析。 百科對於大資料是這樣解釋的:麥肯錫全球研究所給出的定義是:一種規模大到在獲取、儲存、管理、分析方面大大超出了傳統資料庫軟體工具能力範圍的資料
大資料平臺架構思考
筆者早期從事資料開發時,使用spark開發一段時間,感覺大資料開發差不多學到頭了,該會的似乎都會了。在後來的實踐過程中,發現很多事情需要站在更高的視角來看問題,不然很容易陷入“不識廬山真面目”的境界。最近在思考資料資產管理平臺的建設,進行血緣分析開發,有如下感悟: 大資料平臺從資料層面來說,包括資料本身和元
學習大資料基礎筆記02——新手必須掌握的Linux命令
最近在看一本暑假買過的書,但沒怎麼看過,名字叫《Linux就該這麼學》,或許會有人好奇為什麼不是《鳥哥的私房菜》? 其實,我也有鳥哥的這本書,只是頁數太多看起來還是會些許吃力不易懂。在這裡記下這些常用的Linux命令,這些命令與實戰相結合,應該在未來的某一天也會受用! 後續相
學習大資料基礎筆記01——Linux入門與基礎
終於等到大三開學了,新學期昨晚才得到朝思暮想的課表,課表裡的有一門行業前沿技術(心想:前沿技術是個啥技術..) 其實是大資料... 好了,我要開始學東西了...(窘迫) 備註:其實操作步驟是看老師來的,哈哈哈..大資料小白 &nb
學習Hadoop大資料基礎框架
什麼是大資料?進入本世紀以來,尤其是2010年之後,隨著網際網路特別是移動網際網路的發展,資料的增長呈爆炸趨勢,已經很難估計全世界的電子裝置中儲存的資料到底有多少,描述資料系統的資料量的計量單位從MB(1MB大約等於一百萬位元組)、GB(1024MB)、TB(1024GB),一直向上攀升,目
大資料基礎
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
分分鐘理解大資料基礎之Spark
一背景 Spark 是 2010 年由 UC Berkeley AMPLab 開源的一款 基於記憶體的分散式計算框架,2013 年被Apache 基金會接管,是當前大資料領域最為活躍的開源專案之一 Spark 在 MapReduce 計算框架的基礎上,支援計算物件資料可以直接快取到記憶體中,大大提高了整體
大資料基礎之Spark
一背景 Spark 是 2010 年由 UC Berkeley AMPLab 開源的一款 基於記憶體的分散式計算框架,2013 年被Apache 基金會接管,是當前大資料領域最為活躍的開源專案之一 Spark 在 MapReduce 計算框架的基礎上,支援計算物件資料可以直接快取到
大資料基礎學習路線(從零開始)
大資料已經火了很久了,一直想了解它學習它結果沒時間,瞭解了一些資料,結合我自己的情況,整理了一個學習路線,。 學習路線 Linux(shell,高併發架構,lucene,solr) Hadoop(Hadoop,HDFS,Mapreduce,yarn,hive,hbase,sqoop,zookeeper,
重溫大資料---Hbase架構進階
這一講主要是對Hbase JavaApi使用的介紹,程式設計還是挺簡單的,重點在於理解程式設計實現的過程。其次深入講解了Hbase的架構。以及Hbase如何實現資料的遷移。 Hbase Java API Hbase提供了java開發的介面,可以使用java語
大資料基礎Hadoop 2.x入門
hadoop概述 儲存和分析網路資料 三大元件 MapReduce 對海量資料的處理 思想: 分而治之 每個資料集進行邏輯業務處理map 合併統計資料結果reduce