
XML序列化與反序列化+自定義XML註解框架XmlUtils
背景
前面一篇總結了Serializable的序列化與反序列化,現在接著總結XML。主要內容:XML基本的序列化與反序列化方法、一些注意事項、以及自定義了一個XML註解框架(簡潔程式碼,解放雙手)。
XML的序列化與反序列化
先與Serializable進行簡單的對比:
- Serializable儲存的檔案,開啟後無法正常檢視,安全性高。xml檔案可通過文字編輯器檢視與編輯,可讀性高(瀏覽器會格式化xml檔案,更方便檢視),安全性低;
- Serializable檔案通過了簽名,只能在自己的程式中反序列化,或RMI(Remote Method Invocation,遠端呼叫)來解析。xml檔案,只要開啟後知道標籤結構,誰都可以解析出來,跨平臺性好;
- 上面一篇提到過,xml檔案有很多成雙成對的tag標籤,所以會導致xml檔案所需的儲存空間更大(Json較xml最大的優勢也就是,沒有那麼多冗餘的tag標籤)
下面要對PersonBean的List集合進行序列化與反序列化。
一個標準的JavaBean——PersonBean.java
public class PersonBean {
private int id;
private String name;
private boolean isMale;
private String interest;
public PersonBean() {
}
public List集合中三個PersonBean物件:
PersonBean person1 = new PersonBean(101, "張三", true, "<遊戲>CS、紅警</遊戲>,運動<籃球、游泳、健身>");
PersonBean person2 = new PersonBean(102, "小麗", false, "");
PersonBean person3 = new PersonBean(103, "喬布斯", true, "<程式設計>IOS、Android、Linux</程式設計>,運動<健身、登山、游泳>");序列化後,persons.xml內容:
<?xml version='1.0' encoding='UTF-8' ?><!--********註釋:人員資訊********--><Persons date="2016-07-24 22:09:56"><person id="101"><name>張三</name><isMale>true</isMale><interest><遊戲>CS、紅警</遊戲>,運動<籃球、游泳、健身></interest></person><person id="102"><name>小麗</name><isMale>false</isMale><interest></interest></person><person id="103"><name>喬布斯</name><isMale>true</isMale><interest><程式設計>IOS、Android、Linux</程式設計>,運動<健身、登山、游泳></interest></person></Persons>瀏覽器檢視結果:(注意與上面xml中interest為”“的內容比較)

序列化
使用系統自帶的進行XmlSerializer進行序列化,把集合轉變成xml檔案,沒啥好說的,直接上程式碼:
import android.util.Xml;
import org.xmlpull.v1.XmlSerializer;
...
private void serialize(List<PersonBean> personList, File file) {
FileOutputStream fileOS = null;
XmlSerializer serializer = Xml.newSerializer();
StringWriter writer = new StringWriter();
try {
fileOS = new FileOutputStream(file);
serializer.setOutput(writer);
// 第二引數,表示是否定義了外部的DTD檔案。
// true -xml中為yes,沒有定義,預設值;
// false-xml中為no,表示定義了
// null -xml中不顯示
// serializer.startDocument("UTF-8", true);
serializer.startDocument("UTF-8", null);
serializer.comment("********註釋:人員資訊********");
serializer.startTag("", "Persons");
serializer.attribute("", "date", new SimpleDateFormat("yyyy-MM-dd HH:mm:ss", Locale.CHINESE).format(new Date()));
for (PersonBean person : personList) {
serializer.startTag("", "person");
serializer.attribute("", "id", String.valueOf(person.getId()));
serializer.startTag("", "name");
serializer.text(person.getName());
serializer.endTag("", "name");
serializer.startTag("", "isMale");
serializer.text(String.valueOf(person.isMale()));
serializer.endTag("", "isMale");
serializer.startTag("", "interest");
serializer.text( person.getInterest());
serializer.endTag("", "interest");
serializer.endTag("", "person");
}
serializer.endTag("", "Persons");
serializer.endDocument();
fileOS.write(writer.toString().getBytes("UTF-8"));
toast("xml序列化成功"); // -------吐司,可刪,下同-------
} catch (IOException e) {
e.printStackTrace();
toast("xml序列化失敗,原因:" + e.getMessage()); // --------------
}finally {
if (fileOS != null) {
try {
fileOS.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}反序列化
import org.xmlpull.v1.XmlPullParser;
import org.xmlpull.v1.XmlPullParserException;
...
private List<PersonBean> unserialize(File file) {
List<PersonBean> list = new ArrayList<>(0);
FileInputStream fileIS = null;
try {
fileIS = new FileInputStream(file);
XmlPullParser xpp = Xml.newPullParser();
xpp.setInput(fileIS, "UTF-8");
int eventType = xpp.getEventType();
PersonBean person = null;
while (eventType != XmlPullParser.END_DOCUMENT) {
switch (eventType) {
case XmlPullParser.START_TAG:
String tagName = xpp.getName();
if ("person".equals(tagName)) {
person = new PersonBean();
int id = Integer.parseInt(xpp.getAttributeValue("", "id"));
person.setId(id);
} else if ("name".equals(tagName)) {
person.setName(xpp.nextText());
} else if ("isMale".equals(tagName)) {
person.setIsMale(new Boolean(xpp.nextText()));
} else if ("interest".equals(tagName)) {
person.setInterest(xpp.nextText());
}
break;
case XmlPullParser.END_TAG:
if ("person".equals(xpp.getName())) {
list.add(person);
}
break;
}
eventType = xpp.next();
}
toast("解析完畢");
} catch (XmlPullParserException | IOException e) {
e.printStackTrace();
toast("解析失敗,原因:" + e.getMessage());
}finally {
if (fileIS != null) {
try {
fileIS.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return list;
}結果列印到介面上,沒問題

注意事項
反序列化中next()、getName()、getText()、nextText()的理解
next():進入到下一個待解析事件,返回事件的型別。
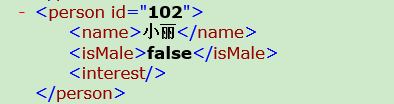
以上圖為例,假設next()進入到了<person id="102">,next()下去,事件依次是:<name> 小麗 </name> <isMale> false </isMale> <interest> </interest> </person>getName():返回標籤的名稱,不包含”/”及attribute屬性值。
如果是非標籤,則返回null。如果上面的解析事件<person id="102">返回person,小麗返回null,</name>返回name。
注:標籤代表當前的事件型別eventType是XmlPullParser.START_TAG或XmlPullParser.END_TAG;TEXT代表eventType是XmlPullParser.TextgetText():返回非標籤,即TEXT的內容值。如果是標籤,返回null。
nextText():下一個Text的內容值,但不是一直找下去。如果下一個事件不是TEXT,是END_TAG,則返回”“。
它的實現程式碼就是醬紫的(參考:API之家):if(getEventType() != START_TAG) { throw new XmlPullParserException( "parser must be on START_TAG to read next text", this, null); } int eventType = next(); if(eventType == TEXT) { String result = getText(); eventType = next(); if(eventType != END_TAG) { throw new XmlPullParserException( "event TEXT it must be immediately followed by END_TAG", this, null); } return result; } else if(eventType == END_TAG) { return ""; } else { throw new XmlPullParserException( "parser must be on START_TAG or TEXT to read text", this, null); }如:上面的小麗的
<interest></interest>,當前事件在<interest>上,如果用xpp.next(); String text = xpp.getText();text得到的是null(空物件,非字串”null”),因為getText()是針對
</interest>標籤了,所以返回null。這肯定不是我們想要的,當然我們可以用判斷來處理。顯然麻煩,而nextText()返回的就是”“,That is what I want。當然,如果在確定都有值的情況下,那修改成如下這樣,要比nextText()少了些判斷,執行效率會高一點點點:
xpp.next(); person.setInterest(xpp.getText()); xpp.next();Bean中物件欄位為null的處理
假設,萬一,上面的PersonBean物件一不小心中傳入了一個空物件null,如name或interest被設定成了null,在序列化時要報空指標異常。
如果為了程式碼程式碼的健壯性,還是有必要做處理的。個人提供兩種方法:- 在Bean的欄位定義時賦預設初值,並在構造方法和setter中進行非null判斷。
- 用一個固定值表示null,如字串”null”,在序列化與反序列化時進行null和”null”的判斷。
序列化:serializer.text(person.getInterest() == null ? "null" : person.getInterest());
反序列化:person.setInterest("null".equals(xpp.getText()) ? null : xpp.getText());
CDATA資料的處理
上面特意用了跟標籤一樣的字串作為資訊輸入。如:"<遊戲>CS、紅警</遊戲>,運動<籃球、游泳、健身>"。在序列化的時候使用的是serializer.text(),此方法會自動把尖括號變成轉義字元,
"<"轉"<",">"轉">",在上面的xml檔案內容中就可以看到了很多這些轉義字元。而在瀏覽器中,會自動換成原字元,讓你看起來舒服。而我們的getText()也會識別轉義字元,並自動轉換成原字元(nextText()內部用的也是getText())。小曲:如果你把瀏覽器中的內容複製到xml檔案中,然後去解析,肯定報錯。
解決小曲問題。就要使用另一個方法cdsect()來序列化,它會把內容用
<![CDATA[和]]>包裹起來,表示character data,不用xml解析器解析的文字資料。serializer.cdsect(person.getInterest());比較一下:
text()的xml檔案內容及瀏覽器格式化:<interest><遊戲>CS、紅警</遊戲>,運動<籃球、游泳、健身></interest>
cdsect()的xml檔案內容及瀏覽器格式化:<interest><![CDATA[<遊戲>CS、紅警</遊戲>,運動<籃球、游泳、健身>]]></interest>
CDATA的反序列化:
經測試,使用原來的nextText()可以直接解析出來。也可以使用看上去更專業一點的nextToken()和getText(),這裡,空字串的CDATA也能解析出來。xpp.nextToken(); person.setInterest(xpp.getText());
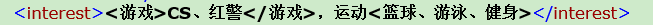

自定義XML註解框架XmlUtils
前一篇提出來說可以用註解+反射來簡化程式碼,ButterKnife也家喻戶曉的註解框架,它們的原理都差不多,很簡單:
- 給類和欄位添加註解,註解資訊用來表示標籤名。無註解的欄位不序列化
- 通過反射獲取欄位值
XmlUtils註解框架
XmlUtils註解框架共三個類:類註解、欄位註解、工具類。
工具類包含四個主要方法,實現四大功能:Bean物件 ←→ xml檔案流,List集合 ←→ xml檔案流
XmlClassInject.java
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* Created by Ralap on 2016/7/24.
*/
@Retention(RetentionPolicy.RUNTIME) // 生命週期:執行時
@Target(ElementType.TYPE) // 作用的目標:類
public @interface XmlClassInject {
String value();
}XmlFiledInject.java
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* Created by Ralap on 2016/7/24.
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
public @interface XmlFiledInject {
String value();
}XmlUtils.java
import android.util.Xml;
import org.xmlpull.v1.XmlPullParser;
import org.xmlpull.v1.XmlSerializer;
import java.io.InputStream;
import java.io.StringWriter;
import java.lang.reflect.Field;
import java.util.ArrayList;
import java.util.List;
/**
1. Created by Ralap on 2016/7/24.
*/
public class XmlUtils {
/**
* Bean物件序列化成xml對應的位元組陣列
*/
public static <T> byte[] serialize_bean2Xml(final T bean) throws Exception{
StringWriter writer = new StringWriter();
XmlSerializer serializer = Xml.newSerializer();
// 獲取類上的註解資訊
Class clazz = bean.getClass();
XmlClassInject classAnno = (XmlClassInject) clazz.getAnnotation(XmlClassInject.class);
if (null == classAnno) {
throw new Exception("Bean類上無@XmlClassInject註解名稱");
}
String beanName = classAnno.value();
serializer.setOutput(writer);
serializer.startDocument("UTF-8", true);
serializer.startTag("", beanName);
// 獲取欄位上的註解資訊
Field[] fields = clazz.getDeclaredFields();
for (Field field : fields) {
XmlFiledInject fieldAnno = field.getAnnotation(XmlFiledInject.class);
if (null == fieldAnno) {
continue;
}
String tagName = fieldAnno.value();
serializer.startTag("", tagName);
field.setAccessible(true);
serializer.text(String.valueOf(field.get(bean)));
serializer.endTag("", tagName);
}
serializer.endTag("", beanName);
serializer.endDocument();
return writer.toString().getBytes("UTF-8");
}
/**
* List集合物件轉換成xml序列化中的一部分。如List中bean的序列化
*/
public static <T> byte[] serialize_list2Xml(final List<T> list) throws Exception{
StringWriter writer = new StringWriter();
XmlSerializer serializer = Xml.newSerializer();
// 獲取類上的註解資訊
Class clazz = list.get(0).getClass();
XmlClassInject classAnno = (XmlClassInject) clazz.getAnnotation(XmlClassInject.class);
if (null == classAnno) {
throw new Exception("Bean類上無@XmlClassInject註解名稱");
}
String beanName = classAnno.value();
// 獲取欄位上的註解資訊,並暴力反射欄位
Field[] fields = clazz.getDeclaredFields();
List<String> tagNames = new ArrayList<>(fields.length);
for (Field field : fields) {
XmlFiledInject fieldAnno = field.getAnnotation(XmlFiledInject.class);
if (null == fieldAnno) {
tagNames.add(null);
} else {
tagNames.add(fieldAnno.value());
field.setAccessible(true);
}
}
serializer.setOutput(writer);
serializer.startDocument("UTF-8", true);
serializer.startTag("", beanName + "List");
for (T bean : list) {
serializer.startTag("", beanName);
for (int i = 0; i < fields.length; i++) {
String name = tagNames.get(i);
if (null != name) {
serializer.startTag("", name);
Field field = fields[i];
serializer.text(field.get(bean).toString());
serializer.endTag("", name);
}
}
serializer.endTag("", beanName);
}
serializer.endTag("", beanName + "List");
serializer.endDocument();
return writer.toString().getBytes("UTF-8");
}
/**
* 把xml輸入流反序列化成Bean物件
*/
public static <T> T unserialize_xml2Bean(final InputStream xmlIn, final Class clazz) throws Exception {
T bean = null;
XmlPullParser xpp = Xml.newPullParser();
xpp.setInput(xmlIn, "UTF-8");
XmlClassInject classAnno = (XmlClassInject) clazz.getAnnotation(XmlClassInject.class);
if (null == classAnno) {
throw new Exception("Bean類上無@XmlClassInject註解名稱");
}
String beanName = classAnno.value();
Field[] fields = clazz.getDeclaredFields();
List<String> tagNames = new ArrayList<>(fields.length);
for (Field field : fields) {
XmlFiledInject fieldAnno = field.getAnnotation(XmlFiledInject.class);
if (null == fieldAnno) {
tagNames.add(null);
} else {
tagNames.add(fieldAnno.value());
}
field.setAccessible(true);
}
int eventType = xpp.getEventType();
while (eventType != XmlPullParser.END_DOCUMENT) {
switch (eventType) {
case XmlPullParser.START_TAG:
int index = tagNames.indexOf(xpp.getName());
if (index > -1) {
Field field = fields[index];
field.set(bean, convertString(xpp.nextText(), field.getType()));
}else if (beanName.equals(xpp.getName())) {
bean = (T) clazz.newInstance();
}
break;
case XmlPullParser.START_DOCUMENT:
case XmlPullParser.END_TAG:
default: break;
}
eventType = xpp.next();
}
return bean;
}
/**
* 把xml輸入流反序列化成Bean物件
*/
public static <T> List<T> unserialize_xml2List(final InputStream xmlIn, final Class clazz) throws Exception {
List<T> list = null;
T bean = null;
XmlPullParser xpp = Xml.newPullParser();
xpp.setInput(xmlIn, "UTF-8");
XmlClassInject classAnno = (XmlClassInject) clazz.getAnnotation(XmlClassInject.class);
if (null == classAnno) {
throw new Exception("Bean類上無@XmlClassInject註解名稱");
}
String beanName = classAnno.value();
Field[] fields = clazz.getDeclaredFields();
List<String> tagNames = new ArrayList<>(fields.length);
for (Field field : fields) {
XmlFiledInject fieldAnno = field.getAnnotation(XmlFiledInject.class);
if (null == fieldAnno) {
tagNames.add(null);
} else {
tagNames.add(fieldAnno.value());
field.setAccessible(true);
}
}
int eventType = xpp.getEventType();
while (eventType != XmlPullParser.END_DOCUMENT) {
switch (eventType) {
case XmlPullParser.START_TAG:
int index = tagNames.indexOf(xpp.getName());
if (index > -1) {
Field field = fields[index];
field.set(bean, convertString(xpp.nextText(), field.getType()));
}else if (beanName.equals(xpp.getName())) {
bean = (T) clazz.newInstance();
}
break;
case XmlPullParser.START_DOCUMENT:
list = new ArrayList();
case XmlPullParser.END_TAG:
if (beanName.equals(xpp.getName())) {
list.add(bean);
}
default: break;
}
eventType = xpp.next();
}
return list;
}
/**
* 把字串轉換成指定類的值,即資料型別的轉換
*/
private static Object convertString(String value, Class clazz) {
if (clazz == String.class) {
return value;
}else if (clazz == boolean.class || clazz == Boolean.class) {
return Boolean.parseBoolean(value);
}else if (clazz == byte.class || clazz == Byte.class) {
return new Byte(value);
}else if (clazz == short.class || clazz == short.class) {
return Short.valueOf(value);
}else if (clazz == int.class || clazz == Integer.class) {
return Integer.valueOf(value);
}else if (clazz == long.class || clazz == Long.class) {
return Long.valueOf(value);
}else if (clazz == float.class || clazz == Float.class) {
return Float.valueOf(value);
}else if (clazz == double.class || clazz == Double.class) {
return Double.valueOf(value);
}else if (clazz == char.class || clazz == Character.class) {
return value.charAt(0);
} else {
return null;
}
}
}XmlUtils的使用
- 給Bean類添加註解
- 呼叫XmlUtils內的序列化與反序列化方法
JavaBean中添加註解:
@XmlClassInject("Human")
public class HumanBean {
@XmlFiledInject("Id") private int id;
@XmlFiledInject("Name") private String name;
private boolean isMale;
@XmlFiledInject("興趣") private String interest;
...
}呼叫:
// 測試資料
HumanBean human1 = new HumanBean(201, "張三", true, "<遊戲>魔獸</遊戲>,運動<籃球、足球>");
HumanBean human2 = new HumanBean(202, "小麗", false, "");
HumanBean human3 = new HumanBean(203, "喬布斯", true, "<語言>Java、C、C++</程式設計>,運動<健身、登山>");
mMan = new HumanBean(2007, "貝爺", true, "<武器>AK47、95、AWP<武器>,運動<探險、登山、游泳>");
mHumanList = new ArrayList<>();
mHumanList.add(human1);
mHumanList.add(human2);
mHumanList.add(human3);
...
// 序列化
try {
// list -> xml
new FileOutputStream(xmlFile).write(XmlUtils.serialize_list2Xml(mHumanList));
// bean -> xml
new FileOutputStream(humanFile).write(XmlUtils.serialize_bean2Xml(mMan));
} catch (Exception e) {
e.printStackTrace();
}
...
// 反序列化
List<HumanBean> xmlHumans = null;
HumanBean hb = null;
try {
// xml -> list
xmlHumans = XmlUtils.unserialize_xml2List(new FileInputStream(xmlFile), HumanBean.class);
// xml -> bean
hb = XmlUtils.unserialize_xml2Bean(new FileInputStream(humanFile), HumanBean.class);
} catch (Exception e) {
e.printStackTrace();
}集合序列化後的xml顯示:

反序列化後的結果展示:

上面的HumanBean中沒有對isMale進行註解,所以序列化後xml沒有,反序列化後值為預設值false。
此XmlUtils是粗略寫的,基本簡單的夠用了。但有很多地方有待完善,如這裡只能註解9種資料型別(8種基本資料型別+String引用資料型別)……