
hive 底層模組實現-distinct
阿新 • • 發佈:2019-01-22
準備資料
語句
SELECT COUNT, COUNT(DISTINCT uid) FROM logs GROUP BY COUNT;
hive> SELECT * FROM logs;
OK
a 蘋果 3
a 橙子 3
a 燒雞 1
b 燒雞 3
hive> SELECT COUNT, COUNT(DISTINCT uid) FROM logs GROUP BY COUNT;根據count分組,計算獨立使用者數。
計算過程

預設設定了hive.map.aggr=true,所以會在mapper端先group by一次,最後再把結果merge起來,為了減少reducer處理的資料量。注意看explain的mode是不一樣的。mapper是hash,reducer是mergepartial。如果把hive.map.aggr=false,那將groupby放到reducer才做,他的mode是complete.
Operator
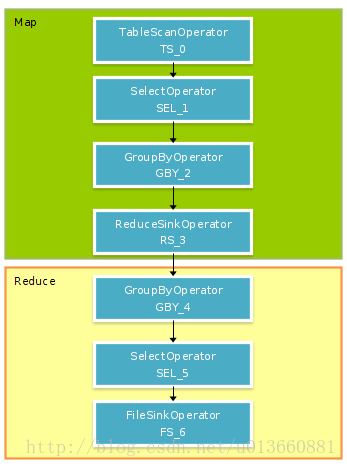
Explain
hive> explain SELECT uid, sum(count) FROM logs group by uid;
OK
ABSTRACT SYNTAX TREE:
(TOK_QUERY (TOK_FROM (TOK_TABREF (TOK_TABNAME logs))) (TOK_INSERT (TOK_DESTINATION (TOK_DIR TOK_TMP_FILE)) (TOK_SELECT (TOK_SELEXPR (TOK_TABLE_OR_COL uid)) (TOK_SELEXPR (TOK_FUNCTION sum