
Spark核心原始碼深度剖析:SparkContext原理剖析與原始碼分析
阿新 • • 發佈:2019-01-22
1.SparkContex原理剖析
1.圖解:
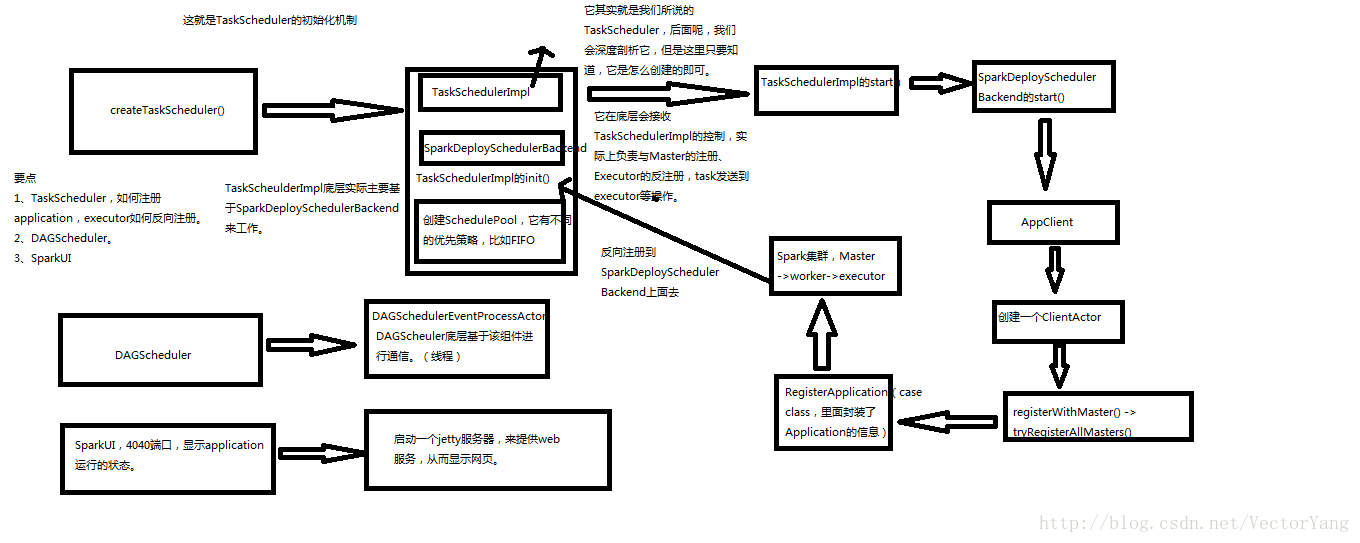
2.SparkContext原始碼分析
1.TaskScheduler建立:
SparkContext.scala
// Create and start the scheduler
private[spark] var (schedulerBackend, taskScheduler) =
SparkContext.createTaskScheduler(this, master)//不同的提交模式,會建立不同的TaskScheduler
private def createTaskScheduler(
sc: SparkContext,
master: String): (SchedulerBackend, TaskScheduler) = {
master match TaskSchedulerImpl.scala
def initialize(backend: SchedulerBackend) {
this 1.TaskScheduler啟動:
TaskSchedulerImpl.scala
override def start() {
//重點是呼叫了SparkDeploySchedulerBackend類的start
backend.start()
if (!isLocal && conf.getBoolean("spark.speculation", false)) {
logInfo("Starting speculative execution thread")
import sc.env.actorSystem.dispatcher
sc.env.actorSystem.scheduler.schedule(SPECULATION_INTERVAL milliseconds,
SPECULATION_INTERVAL milliseconds) {
Utils.tryOrExit { checkSpeculatableTasks() }
}
}
}SparkDeploySchedulerBackend.scala
override def start() {
super.start()
// The endpoint for executors to talk to us
val driverUrl = AkkaUtils.address(
AkkaUtils.protocol(actorSystem),
SparkEnv.driverActorSystemName,
conf.get("spark.driver.host"),
conf.get("spark.driver.port"),
CoarseGrainedSchedulerBackend.ACTOR_NAME)
val args = Seq(
"--driver-url", driverUrl,
"--executor-id", "{{EXECUTOR_ID}}",
"--hostname", "{{HOSTNAME}}",
"--cores", "{{CORES}}",
"--app-id", "{{APP_ID}}",
"--worker-url", "{{WORKER_URL}}")
val extraJavaOpts = sc.conf.getOption("spark.executor.extraJavaOptions")
.map(Utils.splitCommandString).getOrElse(Seq.empty)
val classPathEntries = sc.conf.getOption("spark.executor.extraClassPath")
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil)
val libraryPathEntries = sc.conf.getOption("spark.executor.extraLibraryPath")
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil)
// When testing, expose the parent class path to the child. This is processed by
// compute-classpath.{cmd,sh} and makes all needed jars available to child processes
// when the assembly is built with the "*-provided" profiles enabled.
val testingClassPath =
if (sys.props.contains("spark.testing")) {
sys.props("java.class.path").split(java.io.File.pathSeparator).toSeq
} else {
Nil
}
// Start executors with a few necessary configs for registering with the scheduler
val sparkJavaOpts = Utils.sparkJavaOpts(conf, SparkConf.isExecutorStartupConf)
val javaOpts = sparkJavaOpts ++ extraJavaOpts
val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend",
args, sc.executorEnvs, classPathEntries ++ testingClassPath, libraryPathEntries, javaOpts)
val appUIAddress = sc.ui.map(_.appUIAddress).getOrElse("")
//ApplicationDescription非常重要,它代表了當前的這個
//application的一切情況
//包括application最大需要多少CPU core,每個slave上需要多少記憶體
val appDesc = new ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command,
appUIAddress, sc.eventLogDir, sc.eventLogCodec)
//建立APPClient
//APPClient是一個介面,它負責為application與Spark叢集進行通
//信。它會接收一個Spark Master的URL,以及一個application,和
//一個叢集事件的監聽器,以及各種事件發生時監聽器的回撥函式
client = new AppClient(sc.env.actorSystem, masters, appDesc, this, conf)
client.start()
waitForRegistration()
}2.DAGScheduler建立:
SparkContext.scala
@volatile private[spark] var dagScheduler: DAGScheduler = _
try {
//DAGScheduler類實現了面向stage的排程機制的高層次的排程層,他會為每個job計算一個stage的DAG(有向無環圖),
//追蹤RDD和stage的輸出是否被物化了(物化就是說,寫入了磁碟或者記憶體等地方),並且尋找一個最少
//消耗(最優、最小)排程機制來執行job,它會將stage作為tasksets提交到底層的TaskSchedulerImple上,
//來在叢集上執行它們(task)
//除了處理stage的DAG,它還負責決定執行每個task的最佳位置,基於當前的快取狀態,將這些最佳位置提交底層的
//TaskSchedulerImpl。此外,它會處理理由於shuffle輸出檔案丟失導致的失敗,在這種情況下,舊的stage可能就會
//被重新提交,一個stage內部的失敗,如果不是由於shuffle檔案丟失所導致的,會被TAskSchedule處理,它會多次重試
//每一個task,直到最後,實在是不行了,才會去取消整個stage
dagScheduler = new DAGScheduler(this)
} catch {
case e: Exception => {
try {
stop()
} finally {
throw new SparkException("Error while constructing DAGScheduler", e)
}
}
}3.SparkUI的建立:
SparkContext.scala
// Initialize the Spark UI
private[spark] val ui: Option[SparkUI] =
if (conf.getBoolean("spark.ui.enabled", true)) {
Some(SparkUI.createLiveUI(this, conf, listenerBus, jobProgressListener,
env.securityManager,appName))
} else {
// For tests, do not enable the UI
None
}SparkUI.scala
//預設埠
val DEFAULT_PORT = 4040
def createLiveUI(
sc: SparkContext,
conf: SparkConf,
listenerBus: SparkListenerBus,
jobProgressListener: JobProgressListener,
securityManager: SecurityManager,
appName: String): SparkUI = {
create(Some(sc), conf, listenerBus, securityManager, appName,
jobProgressListener = Some(jobProgressListener))
}