K近鄰估計
阿新 • • 發佈:2019-01-22
Kn-----近鄰估計
KN近鄰估計基本思想:預先確定n的某個函式Kn,然後再x點周圍選擇一個區域,調整區域體積大小,直至Kn個樣本落入區域中。這些樣本被稱為點x的Kn個最近鄰。
如果x點附近的密度比較高,則V的體積自然就相對較小,從而可以提升分辨力;
如果x點附近的密度比較低,則V的體積就較大,但一進入高密度區就會停止增長。
固定樣本數Kn,在x附近選取與之最近的Kn個樣本,計算該Kn個樣本的最小體積V。在x處的概率密度估計值為: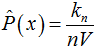
通常選擇: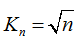
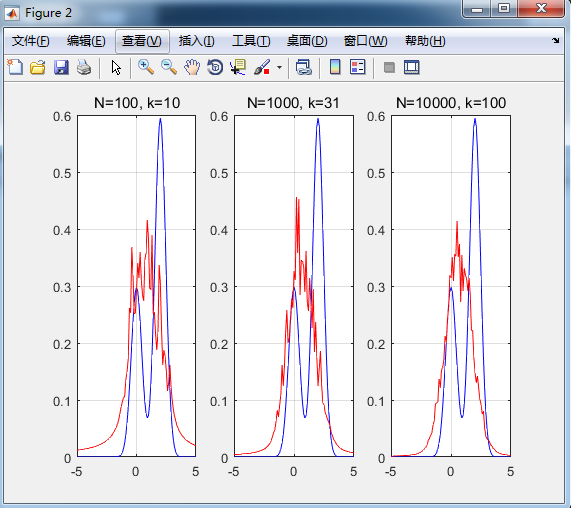
一個例子:

MATLAB實現:
kn_estimate.m
generate_gauss_classes.m(生成正態分佈資料)clc; clear; % 資料的均值向量 Mu = [0; 1]'; % 協方差矩陣 S(:, :, 1) = 1; S(:, :, 2) = 1; P = [1/3 2/3]; % 樣本資料規模 N = 100; knn = fix( sqrt(N) ); % 1.生成資料 randn('seed', 0); [X] = generate_gauss_classes(Mu, S, P, N); % 待估計的概率密度函式 x = -5:0.1:5; pdfx = (1/3)*(1/sqrt(2*pi*0.2))*exp(-.5*(x.^2)/0.2)+... (2/3)*(1/sqrt(2*pi*0.2))*exp(-.5*((x-2).^2)/0.2); figure(); hold on; plot(x, pdfx, '-b'); % 使用knn估計方法 pdfx_approx = knn_density_estimate(X, knn, -5, 5, 0.1); plot(x, pdfx_approx, '-r'); hold off; xlabel(['N=', num2str(N), ', k=', num2str(knn)]); legend('真實概率密度函式','knn估計密度函式','Location','best'); % 取不同的N和k看估計的變化 range_N = [100, 1000, 10000]; range_k = fix( sqrt(range_N) ); figure(); k = 1; for i=1:3 temp_N = range_N(i); [temp_X] = generate_gauss_classes(Mu, S, P, temp_N); pdfx_approx = knn_density_estimate(temp_X, range_k(i), -5, 5, 0.1); subplot(1,3,k); plot(x, pdfx, '-b', x, pdfx_approx, '-r'); grid on; title(['N=', num2str(temp_N), ', k=', num2str(range_k(i))]); k = k+1; end
knn_density_estimate.m(k近鄰估計)function [ data, C ] = generate_gauss_classes( M, S, P, N ) %{ 函式功能: 生成樣本資料,符合正態分佈 引數說明: M:資料的均值向量 S:資料的協方差矩陣 P:各類樣本的先驗概率,即類別分佈 N:樣本規模 函式返回 data:樣本資料(2*N維矩陣) C:樣本資料的類別資訊 %} [~, c] = size(M); data = []; C = []; for j = 1:c % z = mvnrnd(mu,sigma,n); % 產生多維正態隨機數,mu為期望向量,sigma為協方差矩陣,n為規模。 % fix 函式向零方向取整 t = mvnrnd(M(:,j), S(:,:,j), fix(P(j)*N))'; data = [data t]; C = [C ones(1, fix(P(j) * N)) * j]; end end
function [ px ] = knn_density_estimate( X, knn, xleftlimit, xrightlimit, xstep )
%{
函式功能:
使用knn方法估計概率密度函式
引數說明:
X:樣本資料
knn:k的取值大小
xleftlimit和xrightlimit:表示左右邊界
xstep:前進的步長
函式返回:
px:估計得到的概率密度函式
%}
[l, N] = size(X);
if l>1
px=[];
fprintf('Feature set has more than one dimensions');
return;
end
k=1;
x=xleftlimit;
while x<xrightlimit+xstep/2
eucl=[];
for i=1:N
eucl(i)=sqrt( sum((x-X(:,i)).^2) );
end
eucl=sort( eucl, 'ascend' );
ro=eucl(knn);
V=2*ro;
px(k)=knn/(N*V);
k=k+1;
x=x+xstep;
end
end實驗結果: