
Google I/O 2017上推出的新 GC 演算法的原理
貌似之前的Compact Copying Collector並不是concurrent的,然後在Android O裡調整成為了Concurrent Copying Garbage Collector. 新的GC簡單來說就是利用了read barrier來使得應用程式程式碼可以在GC過程中耗時最大的那些階段依舊同GC一起執行。圖是從Presentation裡粘出來的,侵權刪。
新的GC分為Pause, Copying, Reclaim三個階段,以Region為單位進行GC。
Pause階段:
<img data-rawwidth="1112" data-rawheight="556" src="https://pic4.zhimg.com/v2-c5f39f0ca3f2a0d213218f971e87981b_b.png" class="origin_image zh-lightbox-thumb" width="1112" data-original="https://pic4.zhimg.com/v2-c5f39f0ca3f2a0d213218f971e87981b_r.png">
這個階段耗時非常少,這裡很重要的一塊兒工作是確定需要進行GC的region。當前程序中所有正被使用的那些region中存在高度碎片的region會被選中,而這些被選中的region被稱為source region。在GC完成後這些被選中的source region就可以被釋放了。從圖中可以看出本次GC選中了中間的兩個碎片比率很大的region作為source region。在Pause階段完成對所有執行緒stack的walk並得到最終的root set之後,就可以喚醒所有的執行緒並進入到GC的下一個Copying階段。
Copying階段:
<img data-rawwidth="1110" data-rawheight="570" src="https://pic2.zhimg.com/v2-e190108ce592c25dc3a062907c5728ad_b.png" class="origin_image zh-lightbox-thumb" width="1110" data-original="https://pic2.zhimg.com/v2-e190108ce592c25dc3a062907c5728ad_r.png">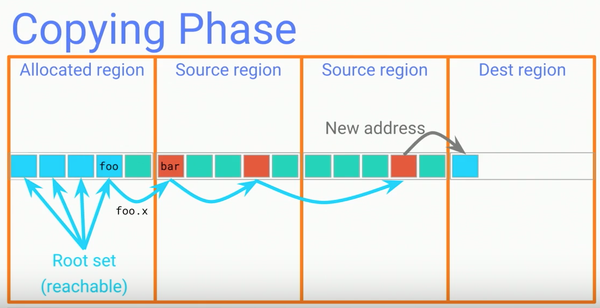
Copying階段是整個GC中耗時最長的階段。通過將source region中根據root set計算並標記為reachable的物件拷貝到destination region,並且確保在GC完成後沒有任何指向source region中記憶體的引用,然後修改所有指向source region的活物件使他們指向新的destination region中的新地址。由於現在應用程式執行緒正在同GC執行緒一同執行,GC需要確保其它執行緒不會讀到依舊指向source region的物件,而新的GC則使用了read barrier技術來達到這個目的。
<img data-rawwidth="1114" data-rawheight="564" src="https://pic3.zhimg.com/v2-742b6a5d48138f5661f838ff7603b97a_b.png" class="origin_image zh-lightbox-thumb" width="1114" data-original="https://pic3.zhimg.com/v2-742b6a5d48138f5661f838ff7603b97a_r.png">
所謂read barrier是一小段程式碼,並且被執行期環境(runtime)安插在field read前來防止其它執行緒看到指向source region的引用。如果其它執行緒在Copying階段需要訪問曾經存在於source region中的物件,GC的read barrier邏輯會負責截獲這個讀取並且將資料拷貝到destination region然後返回這個被拷貝到destination region的新引用。當所有的source region的所有reachable物件都被轉移到destination region之後就可以進入到GC的下一個Reclaim階段了
<img data-rawwidth="1102" data-rawheight="554" src="https://pic4.zhimg.com/v2-1bf2f9700cc0cea9c201d646ca9a1ee3_b.png" class="origin_image zh-lightbox-thumb" width="1102" data-original="https://pic4.zhimg.com/v2-1bf2f9700cc0cea9c201d646ca9a1ee3_r.png">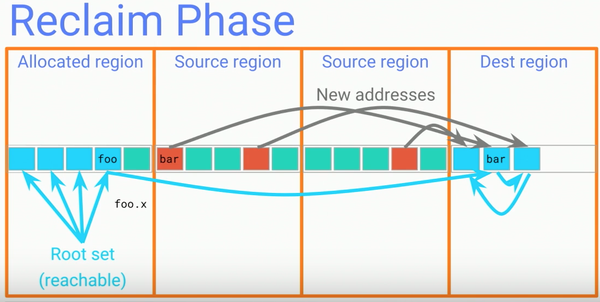
Reclaim階段:在經過Copying階段後,整個程序中就不再存在指向source regions的引用了,GC就可以將這些source region的記憶體釋放供以後使用了。
新的GC演算法在提高了GC效率的同時還得益於對後臺任務甚至系統後臺任務的支援,整個heap的平均尺寸得到了32%的下降。
<img data-rawwidth="992" data-rawheight="552" src="https://pic3.zhimg.com/v2-033fd4784aae7313d6e3fbc428b2f17e_b.png" class="origin_image zh-lightbox-thumb" width="992" data-original="https://pic3.zhimg.com/v2-033fd4784aae7313d6e3fbc428b2f17e_r.png">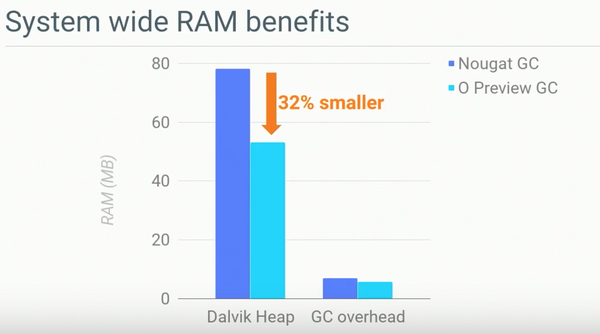
而平均GC Latency也得到了大大的降低,具體對比見圖
<img data-rawwidth="1102" data-rawheight="562" src="https://pic3.zhimg.com/v2-e8d728ed6bc65a240033cf3b4c2fdd0a_b.png" class="origin_image zh-lightbox-thumb" width="1102" data-original="https://pic3.zhimg.com/v2-e8d728ed6bc65a240033cf3b4c2fdd0a_r.png">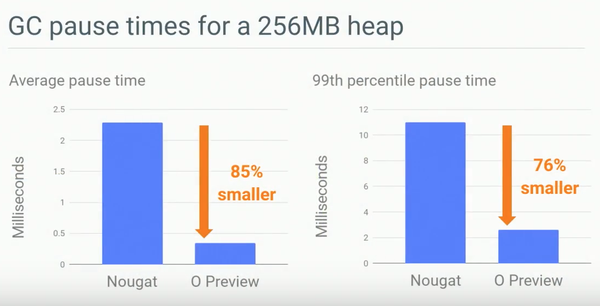
另外由於heap總是經過compact的,從而可以實現Thread Local Bump Pointer的簡單記憶體分配器,因為現在分配記憶體不再需要複雜的free list管理只需要一個簡單的pointer bump,記憶體分配的速度也得到了顯著的提升。
<img data-rawwidth="1116" data-rawheight="544" src="https://pic3.zhimg.com/v2-d1501d9d10c4789cbc05c6cfbcba6ef6_b.png" class="origin_image zh-lightbox-thumb" width="1116" data-original="https://pic3.zhimg.com/v2-d1501d9d10c4789cbc05c6cfbcba6ef6_r.png">