
sqoop匯入匯出表/資料到Hive
筆記:
將關係型資料庫表及表中的資料複製到hive中
sqoop import : RMDBS——>hive
語法:
sqoop import --connect jdbc:mysql://IP:PORT/database --username root --password PWD --table tablename --hive-import --hive-table hivetable -m 1
[[email protected] src]$ sqoop import --connect jdbc:mysql://192.168.2.251:3306/from_66internet?characterEncoding=UTF-8 --username root --password root --table t_user --hive-import --hive-table hivetest1 -m 1
以下是返回結果:
16/04/22 15:16:48 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6 16/04/22 15:16:48 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead. 16/04/22 15:16:48 INFO tool.BaseSqoopTool: Using Hive-specific delimiters for output. You can override 16/04/22 15:16:48 INFO tool.BaseSqoopTool: delimiters with --fields-terminated-by, etc. 16/04/22 15:16:48 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. 16/04/22 15:16:48 INFO tool.CodeGenTool: Beginning code generation 16/04/22 15:16:49 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `t_user` AS t LIMIT 1 16/04/22 15:16:49 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `t_user` AS t LIMIT 1 16/04/22 15:16:49 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /home/hadoop/hadoop/src/hadoop-2.5.0 注: /tmp/sqoop-hadoop/compile/14d08d5f7ecc890e985eeb17942619db/t_user.java使用或覆蓋了已過時的 API。 注: 有關詳細資訊, 請使用 -Xlint:deprecation 重新編譯。 16/04/22 15:16:54 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/14d08d5f7ecc890e985eeb17942619db/t_user.jar 16/04/22 15:16:54 WARN manager.MySQLManager: It looks like you are importing from mysql. 16/04/22 15:16:54 WARN manager.MySQLManager: This transfer can be faster! Use the --direct 16/04/22 15:16:54 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path. 16/04/22 15:16:54 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql) 16/04/22 15:16:54 INFO mapreduce.ImportJobBase: Beginning import of t_user 16/04/22 15:16:55 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 16/04/22 15:16:55 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar 16/04/22 15:16:56 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps 16/04/22 15:16:56 INFO client.RMProxy: Connecting to ResourceManager at nameNode/192.168.2.246:8032 16/04/22 15:17:00 INFO db.DBInputFormat: Using read commited transaction isolation 16/04/22 15:17:00 INFO mapreduce.JobSubmitter: number of splits:1 16/04/22 15:17:01 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1461290770642_0013 16/04/22 15:17:01 INFO impl.YarnClientImpl: Submitted application application_1461290770642_0013 16/04/22 15:17:01 INFO mapreduce.Job: The url to track the job: http://nameNode:8088/proxy/application_1461290770642_0013/ 16/04/22 15:17:01 INFO mapreduce.Job: Running job: job_1461290770642_0013 16/04/22 15:17:16 INFO mapreduce.Job: Job job_1461290770642_0013 running in uber mode : false 16/04/22 15:17:16 INFO mapreduce.Job: map 0% reduce 0% 16/04/22 15:17:25 INFO mapreduce.Job: map 100% reduce 0% 16/04/22 15:17:25 INFO mapreduce.Job: Job job_1461290770642_0013 completed successfully 16/04/22 15:17:25 INFO mapreduce.Job: Counters: 30 File System Counters FILE: Number of bytes read=0 FILE: Number of bytes written=118487 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=87 HDFS: Number of bytes written=1111 HDFS: Number of read operations=4 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Other local map tasks=1 Total time spent by all maps in occupied slots (ms)=6570 Total time spent by all reduces in occupied slots (ms)=0 Total time spent by all map tasks (ms)=6570 Total vcore-seconds taken by all map tasks=6570 Total megabyte-seconds taken by all map tasks=6727680 Map-Reduce Framework Map input records=11 Map output records=11 Input split bytes=87 Spilled Records=0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=95 CPU time spent (ms)=1420 Physical memory (bytes) snapshot=107536384 Virtual memory (bytes) snapshot=2064531456 Total committed heap usage (bytes)=30474240 File Input Format Counters Bytes Read=0 File Output Format Counters Bytes Written=1111 16/04/22 15:17:25 INFO mapreduce.ImportJobBase: Transferred 1.085 KB in 29.4684 seconds (37.7015 bytes/sec) 16/04/22 15:17:25 INFO mapreduce.ImportJobBase: Retrieved 11 records. 16/04/22 15:17:25 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `t_user` AS t LIMIT 1 16/04/22 15:17:25 WARN hive.TableDefWriter: Column create_date had to be cast to a less precise type in Hive 16/04/22 15:17:26 INFO hive.HiveImport: Loading uploaded data into Hive 16/04/22 15:17:28 INFO hive.HiveImport: 16/04/22 15:17:28 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive 16/04/22 15:17:28 INFO hive.HiveImport: 16/04/22 15:17:28 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize 16/04/22 15:17:28 INFO hive.HiveImport: 16/04/22 15:17:28 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize 16/04/22 15:17:28 INFO hive.HiveImport: 16/04/22 15:17:28 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack 16/04/22 15:17:28 INFO hive.HiveImport: 16/04/22 15:17:28 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node 16/04/22 15:17:28 INFO hive.HiveImport: 16/04/22 15:17:28 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces 16/04/22 15:17:28 INFO hive.HiveImport: 16/04/22 15:17:28 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative 16/04/22 15:17:29 INFO hive.HiveImport: 16/04/22 15:17:29 INFO hive.HiveImport: Logging initialized using configuration in jar:file:/home/hadoop/hadoop/src/hive-0.12.0-bin/lib/hive-common-0.12.0.jar!/hive-log4j.properties 16/04/22 15:17:29 INFO hive.HiveImport: SLF4J: Class path contains multiple SLF4J bindings. 16/04/22 15:17:29 INFO hive.HiveImport: SLF4J: Found binding in [jar:file:/home/hadoop/hadoop/src/hadoop-2.5.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] 16/04/22 15:17:29 INFO hive.HiveImport: SLF4J: Found binding in [jar:file:/home/hadoop/hadoop/src/hive-0.12.0-bin/lib/slf4j-log4j12-1.6.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] 16/04/22 15:17:29 INFO hive.HiveImport: SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. 16/04/22 15:17:29 INFO hive.HiveImport: SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] 16/04/22 15:17:39 INFO hive.HiveImport: OK 16/04/22 15:17:39 INFO hive.HiveImport: Time taken: 8.927 seconds 16/04/22 15:17:39 INFO hive.HiveImport: Loading data to table default.hivetest1 16/04/22 15:17:39 INFO hive.HiveImport: Table default.hivetest1 stats: [num_partitions: 0, num_files: 2, num_rows: 0, total_size: 1111, raw_data_size: 0] 16/04/22 15:17:39 INFO hive.HiveImport: OK 16/04/22 15:17:39 INFO hive.HiveImport: Time taken: 0.789 seconds 16/04/22 15:17:40 INFO hive.HiveImport: Hive import complete. 16/04/22 15:17:40 INFO hive.HiveImport: Export directory is empty, removing it.
顯示這樣說明OK Sqoop匯入到Hive中成功
查詢Hive結果
hive> <span style="color:#ff0000;">show databases;</span>
OK
default
Time taken: 6.138 seconds, Fetched: 1 row(s)
hive><span style="color:#ff0000;"> use default;</span>
OK
Time taken: 0.038 seconds
hive> <span style="color:#ff0000;">show tables;</span>
OK
hivetest1
test
Time taken: 0.336 seconds, Fetched: 2 row(s)
hive> select * from hivetest1;
OK
6 2014-01-12 13:36:19.0 hive-------->mysql
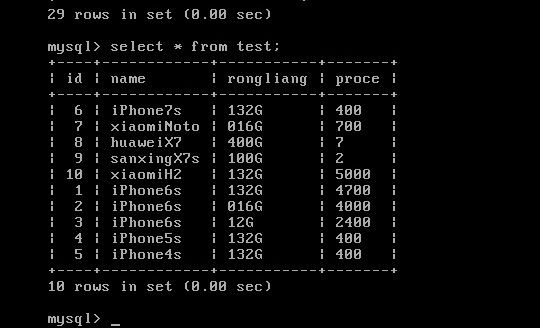
1.查詢hive test表中的資料hive> select * from test;
OK
1 iPhone6s 132G 4700
2 iPhone6s 016G 4000
3 iPhone6s 12G 2400
4 iPhone5s 132G 400
5 iPhone4s 132G 400
6 iPhone7s 132G 400
7 xiaomiNoto 016G 700
8 huaweiX7 400G 7
9 sanxingX7s 100G 2
10 xiaomiH2 132G 5000
2.Hive儲存在HDFS上的元資料
[[email protected] ~]$ hadoop fs -cat /user/hive/warehouse/test/ce.txt
16/04/22 15:44:35 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
1 iPhone6s 132G 4700
2 iPhone6s 016G 4000
3 iPhone6s 12G 2400
4 iPhone5s 132G 400
5 iPhone4s 132G 400
6 iPhone7s 132G 400
7 xiaomiNoto 016G 700
8 huaweiX7 400G 7
9 sanxingX7s 100G 2
10 xiaomiH2 132G 5000
3.將Hive中的表匯入到mysql中
使用:sqoop export --connect jdbc:mysql://192.168.2.251:3306/from_66internet?characterEncoding=UTF-8 --username root --password root --table test --export-dir /user/hive/warehouse/test/ce.txt
出現bug
Error: java.io.IOException: Can't export data, please check failed map task logs
at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:112)
at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:39)
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:145)
at org.apache.sqoop.mapreduce.AutoProgressMapper.run(AutoProgressMapper.java:64)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:764)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:340)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:168)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1614)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:163)
Caused by: java.lang.RuntimeException: Can't parse input data: '1 iPhone6s 132G 4700'
at test.__loadFromFields(test.java:335)
at test.parse(test.java:268)
at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:83)
... 10 more
Caused by: java.lang.NumberFormatException: For input string: "1 iPhone6s 132G 4700"
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Integer.parseInt(Integer.java:580)
at java.lang.Integer.valueOf(Integer.java:766)
at test.__loadFromFields(test.java:317)
... 12 more
16/04/22 16:04:27 INFO mapreduce.Job: Task Id : attempt_1461290770642_0018_m_000001_0, Status : FAILED
Error: java.io.IOException: Can't export data, please check failed map task logs
at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:112)
at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:39)
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:145)
at org.apache.sqoop.mapreduce.AutoProgressMapper.run(AutoProgressMapper.java:64)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:764)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:340)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:168)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1614)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:163)
Caused by: java.lang.RuntimeException: Can't parse input data: '6 iPhone7s 132G 400'
at test.__loadFromFields(test.java:335)
at test.parse(test.java:268)
at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:83)
... 10 more
Caused by: java.lang.NumberFormatException: For input string: "6 iPhone7s 132G 400"
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Integer.parseInt(Integer.java:580)
at java.lang.Integer.valueOf(Integer.java:766)
at test.__loadFromFields(test.java:317)
... 12 more
更改為:sqoop export --connect "jdbc:mysql://192.168.2.251:3306/from_66internet?characterEncoding=UTF-8" --username root --password root --table test --input-fields-terminated-by '\t' --export-dir '/user/hive/warehouse/test/ce.txt' -m 2
檢視資料是否匯入mysql表中
相關推薦
sqoop匯入匯出表/資料到Hive
筆記: 將關係型資料庫表及表中的資料複製到hive中 sqoop import : RMDBS——>hive 語法: sqoop import --connect jdbc:mysql://IP:PORT/database --username root --pass
MySQL匯入匯出表結構和資料
匯出 從Linux伺服器資料庫中倒出表結構和資料(想倒出的.sql檔案放在哪個資料夾下就在哪個資料夾下執行) mysqldump -u資料庫的使用者名稱 -h資料庫連線地址 -p資料庫密碼
使用EXPDP/IMPDP匯入匯出表中資料/元資料測試
首先建立匯出目錄: --更詳細命令及引數,見:http://blog.csdn.net/haibusuanyun/article/details/12584727 [email protected] bys3>create directory dir_dp
大資料Sqoop系列之Sqoop匯入匯出資料
一、Sqoop介紹 Sqoop是一個用來將關係型資料庫和Hadoop中的資料進行相互轉移的工具,可以將一個關係型資料庫(例如Mysql、Oracle)中的資料匯入到Hadoop(例如HDFS、Hive、Hbase)中,也可以將Hadoop(例如HDFS、Hive、Hbase
plsql developer如何匯入匯出表結構和資料以及如何複製表結構和資料?
轉自:https://zhidao.baidu.com/question/480244927.html plsql developer如何匯入匯出表結構和資料: 工具欄: 工具-》匯出表(X) 或者在tables中右鍵要匯出的表,選擇匯出資料,匯出為.dmp格式(二進位制檔
sqoop 匯入mysql資料到hive中,把多個mysql欄位資料型別轉換hive資料型別
如:sqoop import --connect "jdbc:mysql://192.168.2.42:3306/test?useUnicode=true&characterEncoding=utf-8" --username smap --password ****
工作中,sqoop匯入匯出hive,mysql 出現的問題.
1.從mysql匯入到Hive 出現數據帶入錯誤:當欄位中存在輸入tab鍵,會被hive識別多建立一條欄位。 解決:sqoop import 語句中 新增 --hive-drop-import-delims 來把匯入資料中包含的hive預設的分隔符去掉。 2.出現PRIM
Oracle匯入匯出表結構和表資料
測試使用PL/SQL匯出表結構和表資料: 1、選擇匯出的表結構和表資料 點選工具->匯出表選單,選擇匯出表所在的使用者和匯出資料使用的程式,以及匯出資料的輸出檔案。 其中匯出程式一般是Oracle安裝目錄下的BIN下的sqlplus.exe程式。執行完成後可以在指
plsql匯入匯出表結構和資料物件
一、Tools的匯出表結構:export User objects 二、Tools的Export Tables選項 匯出表資料:export tables (選擇:exp.exe) 三、 匯入表結構:import tables -->sqlInse
plsql 匯入匯出表、資料、序列、檢視
一、匯出: 1、開啟plsql-->工具----》匯出使用者物件(可以匯出表結構和序列、檢視) ps:如果上面不選中"包括所有者",這樣到匯出的表結構等就不包含所有者, 這樣就可以將A所有者的表結構等匯入到B所有者的表空間中 2、匯出表結構和表資料: 二、
mysql匯入匯出指定資料指令碼(含遠端)及弊端
有時候,需要匯出表中的指定列的資料,拼接成INSERT語句。如下: Code(遠端匯出需要加入引數"-h+ip";本地則去掉該引數,或者將ip換為本地ip即可) mysql -h+ip -uusername -ppassword -e "select concat('insert i
mysql匯入匯出全部資料指令碼(含遠端)及錯誤收集
使用mysql的mysqldump命令進行資料的匯入匯出。 1、匯出 匯出(遠端): 以下指令碼為預設語句,其他引數預設 mysqldump -h127.0.0.1 -uusername -ppassword --databases dbname --tables tablenam
Laravel使用反向migrate 和 iseed擴充套件匯出表資料
欄目: 我們想要在程式安裝完成時,自動生成表資料(如預設的管理員賬號密碼,後臺管理選單等),可以使用iseed將指定表的資料匯出成seeder檔案,供laravel的seed類使用。 migrate : https://github.com
PE檔案學習筆記(一)---匯入匯出表
最近在看《黑卡免殺攻防》,對講解的PE檔案匯入表、匯出表的作用與原理有了更深刻的理解,特此記錄。 首先,要知道什麼是匯入表? 匯入表機制是PE檔案從其他第三方程式(一般是DLL動態連結庫)中匯入API,以提供本程式呼叫的機制。而在Windows平臺下,PE檔案中的匯入表結構就
MySQL mysqldump 匯入/匯出 結構&資料&儲存過程&函式&事件&觸發器
一、使用mysqldump匯出/匯入sql資料檔案 二、使用infile/outfile匯入/匯出txt/csv資料檔案 ———————————————-庫操作———————————————- 1.①匯出一個庫結構 mysqldump -d dbname -u ro
MongoDB 匯入匯出和資料遷移
遷移需求 現有測試伺服器A 和 測試伺服器 B,需要實現從測試伺服器A向測試伺服器B進行mongoDB 資料庫的遷移。 可以使用 mongoDB 的匯出工具 mongoexport 和匯入工具 mongoimport 實現。 官方英文文件連結 mongoDB mongoexport
Oracle匯入匯出表
使用PL SQL Developer進行操作 一、匯出 工具<<匯出表<<sql插入<<選擇使用者和要匯出的表,勾選建立表,選擇輸出檔案(格式最好為.sql),點選匯出。 二、匯入 匯入之前用記事本更改替換匯出資料的使用者名稱,表空間,資料庫。 工具<<匯入
利用navicat匯入excel表資料到資料庫
注意,表頭為欄位名,,必須資料庫中表欄位名一一對應 第二步:檔案另存為CSV格式 第三步:notepad++開啟儲存的csv檔案選擇編碼轉為UTF-8無BOM編碼格式 一直下一步,直到選擇目標表,可以新建表,也可以手動選擇目標表
5.非關係型資料庫(Nosql)之mongodb:建立集合,備份與匯入匯出, 資料還原,匯入匯出
1固定集合固定集合值得是事先建立而且大小固定的集合2固定集合的特徵:固定集合很像環形佇列,如果空間不足,最早文件就會被刪除,為新的文件騰出空間。一般來說,固定集合適用於任何想要自動淘汰過期屬性的場景
mysql匯出表資料到檔案的幾種方法
方法一:SELECT...INTO OUTFILE mysql> select * from mytbl into outfile '/tmp/mytbl.txt'; Query OK, 3 rows affected (0.00 sec) 檢視mytbl.t