
python爬蟲使用Cookie的兩種方法
阿新 • • 發佈:2019-01-22
場景:當我們以未登入身份使用瀏覽器訪問一個看書的相關網址時,只顯示了亞馬遜的購買連結。隱藏了書籍的下載連結。
但是當我們登入以後,下載連結會顯示出來,這樣在爬蟲的時候,可以把下載連結解析出來使用。
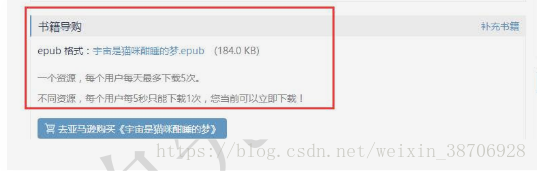
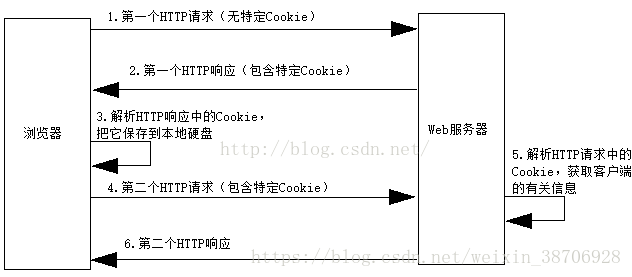
登入前後網頁Headers-Request Headers顯示的Cookie不同。下圖為瀏覽器和Web伺服器之間的互動,也顯示了Cookie的資訊。
Cookie的引文原意是“點心”,它是在客戶端訪問Web伺服器時,伺服器在客戶端硬碟上存放的資訊,好像是伺服器傳送給客戶的“點心”。伺服器可以根據Cookie來跟蹤客戶狀態,這對於需要區別客戶的場合(如電子商務)特別有用。
當客戶端首次請求訪問伺服器時,伺服器先在客戶端存放包含該客戶的相關資訊的Cookie,以後客戶端每次請求訪問伺服器時,都會在HTTP請求資料中包含Cookie,伺服器解析HTTP請求中的Cookie,就能由此獲得關於客戶的相關資訊。
因此我們使用登入以後的Cookie。自己編輯Cookie訪問Web伺服器。網路爬蟲中Cookie的兩種使用方式,程式碼中網頁已經不存在,但是可以自己在其他網頁中嘗試。我們使用的是登入之後的Cookie。
1、直接將Cookie寫在header頭部
# coding:utf-8 import requests from bs4 import BeautifulSoup cookie = '''cisession=19dfd70a27ec0eecf1fe3fc2e48b7f91c7c83c60;CNZZDATA1000201968=181584 6425-1478580135-https%253A%252F%252Fwww.baidu.com%252F%7C1483922031;Hm_lvt_f805f7762a9a2 37a0deac37015e9f6d9=1482722012,1483926313;Hm_lpvt_f805f7762a9a237a0deac37015e9f6d9=14839 26368''' header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Geck o) Chrome/53.0.2785.143 Safari/537.36', 'Connection': 'keep-alive', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'Cookie': cookie} url = 'https://kankandou.com/book/view/22353.html' wbdata = requests.get(url,headers=header).text soup = BeautifulSoup(wbdata,'lxml') print(soup)
2、使用requests插入Cookie
# coding:utf-8 import requests from bs4 import BeautifulSoup cookie = { "cisession":"19dfd70a27ec0eecf1fe3fc2e48b7f91c7c83c60", "CNZZDATA100020196":"1815846425-1478580135-https%253A%252F%252Fwww.baidu.com%252F%7C1483 922031", "Hm_lvt_f805f7762a9a237a0deac37015e9f6d9":"1482722012,1483926313", "Hm_lpvt_f805f7762a9a237a0deac37015e9f6d9":"1483926368" } url = 'https://kankandou.com/book/view/22353.html' wbdata = requests.get(url,cookies=cookie).text soup = BeautifulSoup(wbdata,'lxml') print(soup)
這樣我們就輕鬆的使用Cookie獲取到了需要登入驗證後才能瀏覽的網頁和資源了。上面的Cookie是從自己瀏覽的網頁中複製貼上得到的。
參考自:《python爬蟲實戰入門教程》