
OpenStack Swift學習筆記
1 概述
OpenStack Object Storage(Swift)是OpenStack開源雲端計算專案的子專案之一。Swift的目的是使用普通硬體來構建冗餘的、可擴充套件的分散式物件儲存叢集,儲存容量可達PB級。
Swift並不是檔案系統或者實時的資料儲存系統,它是物件儲存,用於永久型別的靜態資料的長期儲存,這些資料可以檢索、調整,必要時進行更新。最適合儲存的資料型別的例子是虛擬機器映象、圖片儲存、郵件儲存和存檔備份。
Swift無需採用RAID(磁碟冗餘陣列),也沒有中心單元或主控結點。Swift通過在軟體層面引入一致性雜湊技術和資料冗餘性,犧牲一定程度的資料一致性來達到高可用性(High Availability,簡稱HA)和可伸縮性,支援多租戶模式、容器和物件讀寫操作,適合解決網際網路的應用場景下非結構化資料儲存問題。
2 技術特性
2.1 Swift的主要特徵
Swift的主要特性如下:
- 極高的資料永續性(Durability)。
- 完全對稱的系統架構:“對稱”意味著Swift中各節點可以完全對等,能極大地降低系統維護成本。
- 無限的可擴充套件性:一是資料儲存容量無限可擴充套件;二是Swift效能(如QPS、吞吐量等)可線性提升。
- 無單點故障:Swift的元資料儲存是完全均勻隨機分佈的,並且與物件檔案儲存一樣,元資料也會儲存多份。整個Swift叢集中,也沒有一個角色是單點的,並且在架構和設計上保證無單點業務是有效的。
- 簡單、可依賴。
2.2 Swift和HDFS的技術差異
Swift和Hadoop分散式檔案系統(HDFS)都有著相似的目的:實現冗餘、快速、聯網的儲存,它們的技術差異如下:
- 在Swift中,元資料呈分散式,跨叢集複製。而在HDFS使用了中央系統來維護檔案元資料(Namenode,名稱節點),這對HDFS來說無異於單一故障點,因而擴充套件到規模非常大的環境顯得更困難。
- Swift在設計時考慮到了多租戶架構,而HDFS沒有多租戶架構這個概念。
- 在Swift中,檔案可以寫入多次;在併發操作環境下,以最近一次操作為準。而在HDFS中,檔案寫入一次,而且每次只能有一個檔案寫入。
- Swift用Python來編寫,而HDFS用Java來編寫。
- Swift被設計成了一種比較通用的儲存解決方案,能夠可靠地儲存數量非常多的大小不一的檔案;而HDFS被設計成可以儲存數量中等的大檔案(HDFS針對更龐大的檔案作了優化),以支援資料處理。
3 關鍵技術
3.1 一致性雜湊(ConsistentHashing)
在分散式物件儲存中,一個關鍵問題是資料該如何存放。Swift是基於一致性雜湊技術,通過計算可將物件均勻分佈到虛擬空間的虛擬節點上,在增加或刪除節點時可大大減少需移動的資料量;虛擬空間大小通常採用2的n次冪,便於進行高效的移位操作;然後通過獨特的資料結構 Ring(環)再將虛擬節點對映到實際的物理儲存裝置上,完成定址過程。
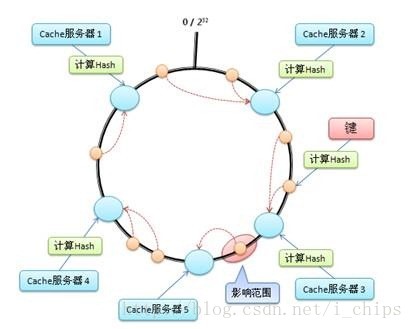
圖1 一致性雜湊環結構
衡量一致性雜湊的4個指標:
- 平衡性(Balance):平衡性是指Hash的結果能夠儘可能分佈均勻,充分利用所有快取空間。
- 單調性(Monotonicity):單調性是指如果已經有一些內容通過雜湊分派到了相應的緩衝中,又有新的緩衝加入到系統中。雜湊的結果應能夠保證原有已分配的內容可以被對映到新的緩衝中去,而不會被對映到舊的緩衝集合中的其他緩衝區。
- 分散性(Spread):分散性定義了分散式環境中,不同終端通過Hash過程將內容對映至快取上時,因可見快取不同,Hash結果不一致,相同的內容被對映至不同的緩衝區。
- 負載(Load):負載是對分散性要求的另一個緯度。既然不同的終端可以將相同的內容對映到不同的緩衝區中,那麼對於一個特定的緩衝區而言,也可能被不同的使用者對映為不同的內容。
Swift使用該演算法的主要目的是在改變叢集的node數量時(增加/刪除伺服器),能夠儘可能少地改變已存在key和node的對映關係,以滿足單調性。
考慮到雜湊演算法在node較少的情況下,改變node數會帶來巨大的資料遷移。為了解決這種情況,一致性雜湊引入了“虛擬節點”(vnode,也稱為partition)的概念: “虛擬節點”是實際節點在環形空間的複製品,一個實際節點對應了若干個“虛擬節點”,“虛擬節點”在雜湊空間中以雜湊值排列。
總的來說,Swift中存在兩種對映關係,對於一個檔案,通過雜湊演算法(MD5)找到對應的虛節點(一對一的對映關係),虛節點再通過對映關係(ring檔案中二維陣列)找到對應的裝置(多對多的對映關係),這樣就完成了一個檔案儲存在裝置上的對映。
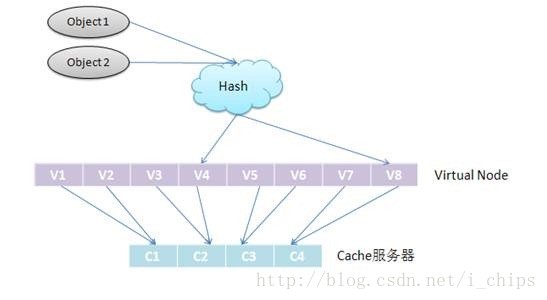
圖2 物件、虛結點、節點間的對映關係
在設定虛結點數的時候,需要對系統預期的規模做充分考慮,假如叢集的規模不會超過6000個結點,那麼可以將虛結點數設定為結點數的100倍。這樣,變動任意一個結點的負載僅影響1%的資料項。此時有6百萬個vnode數,使用2bytes來儲存結點數(0~65535)。基本的記憶體佔用是6*(10^6)*2bytes=12Mb,對於伺服器來說完全可以承受。
假設有65536(2^16)個node,有128(2^7)倍的partition數(2^23,則PARTITION_POWER=23)。由於MD5碼是32位的,使用PARTITION_SHIFT(等於32- PARTITION_POWER)將資料項的MD5雜湊值對映到partition的2^23的空間中。
3.2 資料一致性模型(ConsistencyModel)
按照Eric Brewer的CAP(Consistency,Availability,PartitionTolerance)理論,無法同時滿足3個方面,Swift放棄嚴格一致性(滿足ACID事務級別),而採用最終一致性模型(Eventual Consistency),來達到高可用性和無限水平擴充套件能力。
為了實現這一目標,Swift採用Quorum仲裁協議(Quorum有法定投票人數的含義):
- 定義:N:資料的副本總數;W:寫操作被確認接受的副本數量;R:讀操作的副本數量。
- 強一致性:R+W>N,以保證對副本的讀寫操作會產生交集,從而保證可以讀取到最新版本;如果 W=N,R=1,則需要全部更新,適合大量讀少量寫操作場景下的強一致性;如果 R=N,W=1,則只更新一個副本,通過讀取全部副本來得到最新版本,適合大量寫少量讀場景下的強一致性。
- 弱一致性:R+W<=N,如果讀寫操作的副本集合不產生交集,就可能會讀到髒資料;適合對一致性要求比較低的場景。
Swift針對的是讀寫都比較頻繁的場景,所以採用了比較折中的策略,即寫操作需要滿足至少一半以上成功W>N/2,再保證讀操作與寫操作的副本集合至少產生一個交集,即R+W>N。
在分散式系統中,資料的單點是不允許存在的。線上正常存在的replica數量是1的話將非常危險的,因為一旦這個replica再次錯誤,就可能發生資料的永久性錯誤。假如我們把N設定成為2,那麼,只要有一個儲存節點發生損壞,就會有單點的存在。所以N必須大於2。但N越高,系統的維護和整體成本就越高。所以,工業界通常把N設定為3。
Swift預設配置是N=3,W=2>N/2,R=1或2,即每個物件會存在3個副本,這些副本會被儘量儲存在不同區域的節點上;W=2表示至少需要更新2個副本才算寫成功。
當R=1時,意味著某一個讀操作成功便立刻返回,此種情況下可能會讀取到舊版本(弱一致性模型)。
當R=2時,需要通過在讀操作請求頭中增加x-newest=true引數來同時讀取2個副本的元資料資訊,然後比較時間戳來確定哪個是最新版本(強一致性模型)。
如果資料出現了不一致,後臺服務程序會在一定時間視窗內通過檢測和複製協議來完成資料同步,從而保證達到最終一致性。
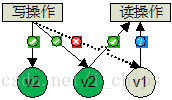
圖3 Quorum協議示例
3.3 環(Ring)
Ring是Swift中最重要的元件,用於記錄儲存物件與物理位置間的對映關係。在涉及查詢Account、Container、Object資訊時就需要查詢叢集的Ring資訊。
環是為了將虛擬節點(partition,分割槽)均衡地對映到一組物理儲存裝置上,並提供一定的冗餘度而設計的,其資料結構由以下資訊組成:
儲存裝置列表、裝置資訊包括唯一標識號(id)、區域號(zone)、權重(weight)、IP 地址(ip)、埠(port)、裝置名稱(device)、元資料(meta)。
Swift為賬戶、容器和物件分別定義了的Ring,其查詢過程是相同的。Ring中每個partition在叢集中都預設有3個replica。每個partition的位置由ring來維護,並存儲在對映中。
Ring使用zone來保證資料的物理隔離。每個partition的replica都確保放在了不同的zone中。Zone只是個抽象概念,它可以是一個磁碟(disk drive),一個伺服器(server),一個機架(cabinet),一個交換機(switch),甚至是一個數據中心(datacenter),以提供最高級別的冗餘性,建議至少部署5個zone。
權重引數是個相對值,可以來根據磁碟的大小來調節,權重越大表示可分配的空間越多,可部署更多的分割槽。
當叢集中發生儲存節點宕機、新增(刪)儲存節點、新增(刪)zone等必須改變partition和node間的對映關係時,還可以對Ring檔案通過重新平衡(rebalance)來進行更新。當虛節點需要移動時,環會確保一次移動最少數量的虛節點數,並且一次只移動一個虛節點的一個副本。
總的來說,Ring引入一致性雜湊的原因是為了減少由於增加結點導致資料項移動的數量來提高單調性;引入partition的原因是為了減少由於節點數過少導致移動過多的資料項;引入replica的原因是防止資料單點、提高冗餘性;引入zone的原因是為了保證分割槽容忍性;引入weight的原因是為了保證partition分配的均衡。
4 架構設計
4.1 Swift資料模型
Swift採用層次資料模型,共設三層邏輯結構:Account/Container/Object(賬戶/容器/物件)。每層節點數均沒有限制,可以任意擴充套件。這裡的賬戶和個人賬戶不是一個概念,可理解為租戶,用來做頂層的隔離機制,可以被多個個人賬戶所共同使用;容器類似資料夾,代表封裝一組物件;物件由元資料和資料兩部分組成。
4.2 Swift系統架構
Swift採用完全對稱、面向資源的分散式系統架構設計,所有元件都可擴充套件,避免因單點失效而擴散並影響整個系統運轉;通訊方式採用非阻塞式 I/O 模式,提高了系統吞吐和響應能力。
Swift元件包括:
- 代理服務(ProxyServer):Swift通過Proxy Server向外提供基於HTTP的REST服務介面,會根據環的資訊來查詢服務地址並轉發使用者請求至相應的賬戶、容器或者物件,進行CRUD(增刪改查)等操作。由於採用無狀態的REST請求協議,可以進行橫向擴充套件來均衡負載。在訪問Swift服務之前,需要先通過認證服務獲取訪問令牌,然後在傳送的請求中加入頭部資訊 X-Auth-Token。代理伺服器負責Swift架構的其餘元件間的相互通訊。代理伺服器也處理大量的失敗請求。例如,如果對於某個物件PUT請求時,某個儲存節點不可用,它將會查詢環可傳送的伺服器並轉發請求。物件以流的形式到達(來自) 物件伺服器,它們直接從代理伺服器傳送到(來自)使用者—代理伺服器並不緩衝它們。
- 認證服務(AuthenticationServer):驗證訪問使用者的身份資訊,並獲得一個物件訪問令牌(Token),在一定的時間內會一直有效;驗證訪問令牌的有效性並快取下來直至過期時間。
- 快取服務(CacheServer):快取的內容包括物件服務令牌,賬戶和容器的存在資訊,但不會快取物件本身的資料;快取服務可採用Memcached叢集,Swift會使用一致性雜湊演算法來分配快取地址。
- 賬戶服務(AccountServer):提供賬戶元資料和統計資訊,並維護所含容器列表的服務,每個賬戶的資訊被儲存在一個SQLite資料庫中。
- 容器服務(ContainerServer):提供容器元資料和統計資訊(比如物件的總數,容器的使用情況等),並維護所含物件列表的服務。容器服務並不知道物件存在哪,只知道指定容器裡存的哪些物件。 這些物件資訊以SQLite資料庫檔案的形式儲存,和物件一樣在叢集上做類似的備份。
- 物件服務(ObjectServer):提供物件元資料和內容服務,可以用來儲存、檢索和刪除本地裝置上的物件。在檔案系統中,物件以二進位制檔案的形式儲存,它的元資料儲存在檔案系統的擴充套件屬性(xattr)中,建議採用預設支援擴充套件屬性(xattr)的XFS檔案系統。每個物件使用物件名稱的雜湊值和操作的時間戳組成的路徑來儲存。最後一次寫操作總可以成功,並確保最新一次的物件版本將會被處理。刪除也被視為檔案的一個版本(一個以".ts"結尾的0位元組檔案,ts表示墓碑)。
- 複製服務(Replicator):會檢測本地分割槽副本和遠端副本是否一致,具體是通過對比雜湊檔案和高階水印來完成,發現不一致時會採用推式(Push)更新遠端副本:對於物件的複製,更新只是使用rsync同步檔案到對等節點。帳號和容器的複製通過HTTP或rsync來推送整個資料庫檔案上丟失的記錄;另外一個任務是確保被標記刪除的物件從檔案系統中移除:當有一項(物件、容器、或者帳號)被刪除,則一個墓碑檔案被設定作為該項的最新版本。複製器將會檢測到該墓碑檔案並確保將它從整個系統中移除。
- 更新服務(Updater):當物件由於高負載或者系統故障等原因而無法立即更新時,任務將會被序列化到在本地檔案系統中進行排隊,以便服務恢復後進行非同步更新;例如成功建立物件後容器伺服器沒有及時更新物件列表,這個時候容器的更新操作就會進入排隊中,更新服務會在系統恢復正常後掃描佇列並進行相應的更新處理。
- 審計服務(Auditor):在本地伺服器上會反覆地爬取來檢查物件,容器和賬戶的完整性,如果發現位元級的錯誤,檔案將被隔離,並複製其他的副本以覆蓋本地損壞的副本;其他型別的錯誤(比如在任何一個容器伺服器中都找不到所需的物件列表)會被記錄到日誌中。
- 賬戶清理服務(AccountReaper):移除被標記為刪除的賬戶,刪除其所包含的所有容器和物件。刪除賬號的過程是相當直接的。對於每個賬號中的容器,每個物件先被刪除然後容器被刪除。任何失敗的刪除請求將不會阻止整個過程,但是將會導致整個過程最終失敗(例如,如果一個物件的刪除超時,容器將不能被刪除,因此賬號也不能被刪除)。整個處理過程即使遭遇失敗也繼續執行,這樣它不會因為一個麻煩的問題而中止恢復叢集空間。賬號收割器將會繼續不斷地嘗試刪除賬號直到它最終變為空,此時資料庫在db_replicator中回收處理,最終移除這個資料庫檔案。
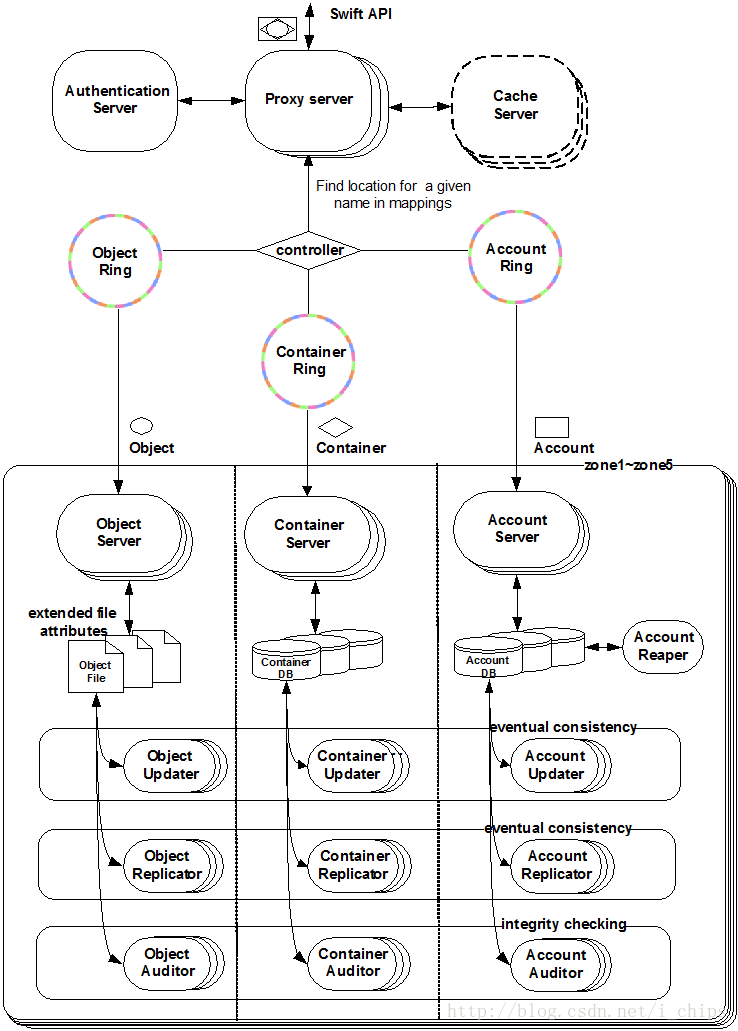
圖4 Swift系統架構
Swift支援的所有操作可以總結為下表:
表1 SwiftRESTful API總結
|
資源型別 |
URL |
GET |
PUT |
POST |
DELETE |
HEAD |
|
賬戶 |
/account/ |
獲取容器列表 |
- |
- |
- |
獲取賬戶元資料 |
|
容器 |
/account/container |
獲取物件列表 |
建立容器 |
更新容器元資料 |
刪除容器 |
獲取容器元資料 |
|
物件 |
/account/container/object |
獲取物件內容和元資料 |
建立、更新或拷貝物件 |
更新物件元資料 |
刪除物件 |
獲取物件元資料 |
4.3 Ring的資料結構
Ring 的資料結構由三個頂層域構成,其中:
- List of Devices,表示叢集中裝置的列表,在Ring類內部被稱為devs;
- Partition Assignment List,用於存放每個replica與device間對映關係,在Ring類內部被稱為_replica2part2dev_id;
- Partition Shift Value,表示計算資料hash的移位量,在Ring類內部稱為_part_shift。
使用python讀取/etc/swift/object.ring.gz存放的資料,可以獲得以devs、 part_shift、 replica2part2dev_id 為key的dict類資料。
4.4 Swift儲存結構
在Storage Node上執行著Linux系統並使用了XFS檔案系統,邏輯上使用一致性雜湊演算法將固定總數的partition對映到每個Storage Node上,每個data也使用同樣的雜湊演算法對映到partition上。
儲存內容一般放在/srv/node/sdb1之類的路徑下,其目錄結構如下所示:accounts、async_pending、containers、objects、quarantined和tmp。其中accounts、containers、objects分別是賬號、容器、物件的儲存目錄,async_pending是非同步待更新目錄,quarantined是隔離目錄,tmp是臨時目錄。
- objects:在objects目錄下存放的是各個partition目錄,其中每個partition目錄是由若干個suffix_path名的目錄和一個hashes.pkl檔案組成,suffix_path目錄下是由object的hash_path名構成的目錄,在hash_path目錄下存放了關於object的資料和元資料;object的資料存放在後綴為.data的檔案中,它的metadata存放在以後綴為.meta的檔案中,將被刪除的Object以一個0位元組字尾為.ts的檔案存放。
- accounts:在accounts目錄下存放的是各個partition,而每個partition目錄是由若干個suffix_path目錄組成,suffix_path目錄下是由account的hsh名構成的目錄,在hsh目錄下存放了關於account的sqlite db;在account的db檔案中,包含了account_stat、container、incoming_sync 、outgoing_sync 4張表;其中,表account_stat是記錄關於account的資訊,如名稱、建立時間、container數統計等等;表container記錄關於container的資訊;表incoming_sync記錄到來的同步資料項;表outgoing_sync表示推送出的同步資料項。
- containers:containers目錄結構和生成過程與accounts類似,containers的db中共有5張表,其中incoming_sync和outgoing_sync的schema與accounts中的相同。其他3張表分別為container_stat、object、sqlite_sequence;表container_stat與表account_stat相似,其區別是container_stat存放的是關於container資訊。
- tmp:tmp目錄作為account/container/object server向partition目錄內寫入資料前的臨時目錄。例如,client向server上傳某一檔案,object server呼叫DiskFile類的mkstemp方法建立在路徑為path/device/tmp的目錄。在資料上傳完成之後,再呼叫put()方法,將資料移動到相應路徑。
- async_pending:async_pending存放未能及時更新而被加入更新佇列的資料。本地server在與remote server建立HTTP連線或者傳送資料時超時導致更新失敗時,將把檔案放入async_pending目錄。這種情況經常發生在系統故障或者是高負荷的情況下。如果更新失敗,本次更新被加入佇列,然後由Updater繼續處理這些失敗的更新工作;account與container的db和object兩者的pending檔案處理方式有所不同:db的pending檔案在更新完其中的一項資料之後,刪除pending檔案中的相應的資料項,而object的資料在更新完成之後,移動pending檔案到目標目錄。
- quarantined:quarantined路徑用於隔離發生損壞的資料。Auditor程序會在本地伺服器上每隔一段時間就掃描一次磁碟來檢測account、container、object的完整性。一旦發現不完整的資料,該檔案就會被隔離,該目錄就稱為quarantined目錄。為了限制Auditor消耗過多的系統資源,其預設掃描間隔是30秒,每秒最大的掃描檔案數為20,最高速率為10Mb/s。account和container的Auditor的掃描間隔比object要長得多。
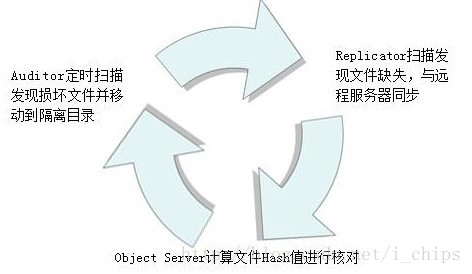
圖5 隔離物件的處理流程
5 小結
Swift犧牲一定程度的資料一致性,來達到高可用性和可伸縮性,支援多租戶模式、容器和物件讀寫操作,適合解決網際網路的應用場景下非結構化資料儲存問題。
有理由相信,因為其完全的開放性、廣泛的使用者群和社群貢獻者,Swift可能會成為雲端儲存的開放標準,從而打破Amazon S3在市場上的壟斷地位,推動雲端計算在朝著更加開放和可互操作的方向前進。