
GAN(Generative Adversarial Network)的學習歷程
2)DCGAN篇:
注:要知道自從2014年Ian Goodfellow提出以來,GAN就存在著訓練困難、生成器和判別器的loss無法指示訓練程序、生成樣本缺乏多樣性等問題。從那時起,很多論文都在嘗試解決,但是效果不盡人意,比如最有名的一個改進DCGAN依靠的是對判別器和生成器的架構進行實驗列舉,最終找到一組比較好的網路架構設定,但是實際上是治標不治本,沒有徹底解決問題。
4)WGAN篇:
注:針對於DCGAN的治標能不治本而言,Wasserstein GAN(下面簡稱WGAN)成功地做到了以下爆炸性的幾點:
- 徹底解決GAN訓練不穩定的問題,不再需要小心平衡生成器和判別器的訓練程度
- 基本解決了collapse mode的問題,確保了生成樣本的多樣性
- 訓練過程中終於有一個像交叉熵、準確率這樣的數值來指示訓練的程序,這個數值越小代表GAN訓練得越好,代表生成器產生的影象質量越高(如題圖所示)
- 以上一切好處不需要精心設計的網路架構,最簡單的多層全連線網路就可以做到

WGAN前作分析了Ian Goodfellow提出的原始GAN兩種形式各自的問題,第一種形式等價在最優判別器下等價於最小化生成分佈與真實分佈之間的JS散度,由於隨機生成分佈很難與真實分佈有不可忽略的重疊以及JS散度的突變特性,使得生成器面臨梯度消失的問題;第二種形式在最優判別器下等價於既要最小化生成分佈與真實分佈直接的KL散度,又要最大化其JS散度,相互矛盾,導致梯度不穩定,而且KL散度的不對稱性使得生成器寧可喪失多樣性也不願喪失準確性,導致collapse mode現象。
WGAN前作針對分佈重疊問題提出了一個過渡解決方案,通過對生成樣本和真實樣本加噪聲使得兩個分佈產生重疊,理論上可以解決訓練不穩定的問題,可以放心訓練判別器到接近最優,但是未能提供一個指示訓練程序的可靠指標,也未做實驗驗證。
WGAN本作引入了Wasserstein距離,由於它相對KL散度與JS散度具有優越的平滑特性,理論上可以解決梯度消失問題。接著通過數學變換將Wasserstein距離寫成可求解的形式,利用一個引數數值範圍受限的判別器神經網路來最大化這個形式,就可以近似Wasserstein距離。在此近似最優判別器下優化生成器使得Wasserstein距離縮小,就能有效拉近生成分佈與真實分佈。WGAN既解決了訓練不穩定的問題,也提供了一個可靠的訓練程序指標,而且該指標確實與生成樣本的質量高度相關。作者對WGAN進行了實驗驗證。
5)LS-GAN(loss-sensitive GAN)篇:
在最後一篇部落格中,給出如下參考:
程式碼
1. LS-GAN: https://github.com/guojunq/lsgan
2. GLS-GAN: https://github.com/guojunq/glsgan
參考文獻
1. Qi G J. Loss-Sensitive GenerativeAdversarial Networks on Lipschitz Densities[J]. arXiv preprintarXiv:1701.06264, 2017.
4.f-GAN:Training generative neural samplers using variational divergence minimization[C]//Advances in Neural Information Processing Systems. 2016:271-279.
到目前為止,講解了GAN;DCGAN;LSGAN;WGAN;LS-GAN
那麼究竟GAN,WGAN和LS-GAN誰更好呢?
持平而論,筆者認為是各有千秋。究竟誰更好,還是要在不同問題上具體分析。
這三種方法只是提供了一個大體的框架,對於不同的具體研究物件(影象、視訊、文字等)、資料型別(連續、離散)、結構(序列、矩陣、張量),應用這些框架,對具體問題可以做出很多不同的新模型。
當然,在具體實現時,也有非常多的要考慮的細節,這些對不同方法的效果都會起到很大的影響。畢竟,細節是魔鬼!
筆者在實現LS-GAN也很多的具體細緻的問題要克服。一直到現在,我們還在不斷持續的完善相關程式碼。
對LS-GAN有興趣的讀者,可以參看我們分享的程式碼,並提出改進的建議
6)WGAN-GP(WGAN with gradient penalty)篇
本論文在github上開源了程式碼:github
注1:生成對抗網路(GAN)是一種強大的生成模型,但是自從2014年Ian Goodfellow提出以來,GAN就存在訓練不穩定的問題。後來提出的 Wasserstein GAN(WGAN)在訓練穩定性上有極大的進步,但是在某些設定下仍存在生成低質量的樣本,或者不能收斂等問題。
隨後蒙特利爾大學的研究者們在WGAN的訓練上又有了新的進展,他們將論文《Improved Training of Wasserstein GANs》釋出在了arXiv上。研究者們發現失敗的案例通常是由在WGAN中使用權重剪枝來對critic實施Lipschitz約束導致的。在本片論文中,研究者們提出了一種替代權重剪枝實施Lipschitz約束的方法:懲罰critic對輸入的梯度。該方法收斂速度更快,並能夠生成比權重剪枝的WGAN更高質量的樣本
注2:我們現在大概可以把目前已經開發出來的GAN模型分個類。
第一類是要假設無限建模能力、以此證明能夠生成真實樣本的模型。Goodfellow的經典GAN,EBGAN,還有最近出現的最小二乘GAN,都基於這樣的假設。
而這些GAN都存在梯度消失的問題:即當真實樣本和生成樣本的流型沒有重疊或者重疊可以忽略時,它們優化生成網路的目標函式是一個常數。
對GAN來說是J-S距離,EB-GAN是total variation距離,最小二乘GAN是Pearson 距離。這時,這些梯度就消失了。
這裡似乎可以建立個猜想:一旦要假設無限建模能力,那麼梯度消失就是不可避免的。也就是說無限建模能力是引起梯度消失的本質原因。不過我現在還沒有證明這點。
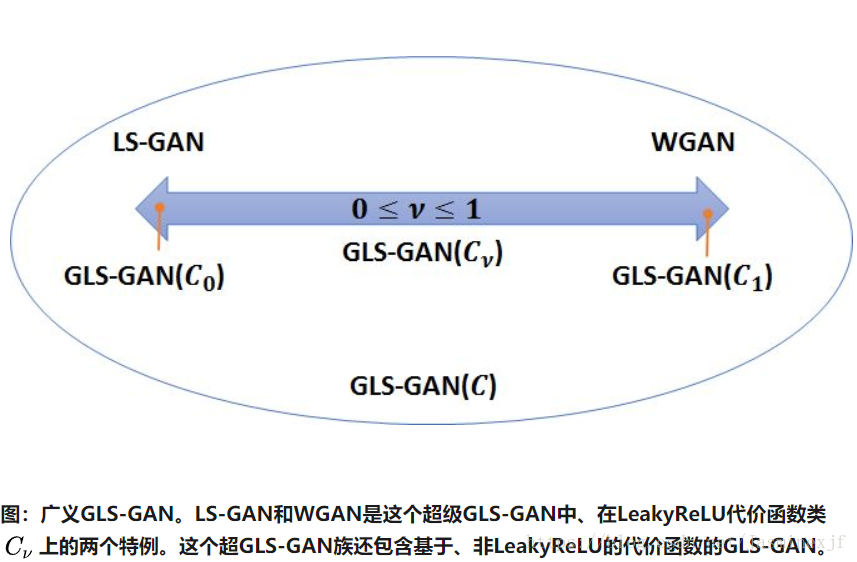
第二類就是GLS-GAN了。代表就是LS-GAN和WGAN,它們都是GLS-GAN特例了。這第二類不用假設無限建模能力,也沒有梯度消失問題。
那有沒有第三類呢?現在我也不知道:)
7)InfoGAN+Improved GAN
注:提出許多訓練GAN的小trick,有著很強的實際意義;Improved GAN實際上是提出了幾個使得GANs更穩定的技術,包括:feature matching、minibatch discrimination、historicalaveraging、one-sided label smoothing、virtual batch normalization。
InfoGAN程式碼:https://github.com/openai/InfoGAN
Improved GAN程式碼:https://github.com/openai/improved-gan