
SVM與ANN實現OCR字元識別
SVM -支援向量機原理與實踐之實踐篇
-
前言
最近太忙,這幾天還是抽空完成實踐篇,畢竟所有理論都是為實踐服務的,上一篇花了很大篇幅從小白的角度詳細的分析了SVM支援向量積的原理,當然還有很多內容沒有涉及到,例如支援向量迴歸,不敏感損失函式等內容,但是也不妨礙我們用支援向量機去實現一個分類系統,因為有了對前面說講述知識的一定的瞭解,就可以很好的為我們這一篇的實踐內容服務。
-
實驗內容和目標
下面我們的實驗內容,看下圖中的幾張圖片,我們的目標是將影象中白底的數字字串識別出來。

圖一

圖二
我們可以看到上圖中的兩張圖片,他們的照片效果都還好,預計識別的難度不會很大,但是我們還有很多的樣本,他們的效果可能會很不好,就像第一張圖片中有點歪,但是可能會有樣本歪得很厲害,第二張中我們看到字元後面還有陰影,我們看的很清晰,但是有的樣本後面的陰影會很大,可能達到導致人眼有時候都會有錯覺,最重要的是有時候我們的需求可能不是要我們識別圖片中的某一串數字字元,而不是所有字元,就像我們這個試驗中的目標一樣(要識別第二行中的字元),所以我們首先需要對字元進行定位,字元定位以後我們還需要對字元進行分割,分割之後還會運用ANN即人工神經網路演算法對它進行識別,當然這不是這一篇實踐內容的需要講解的內容。
我們這一篇實踐內容主要講解的是,在對原始影象的進行預處理以後,我們會得出一些有效的樣本和一些無效的樣本,也就是說,我們通過影象處理技術,處理和定位之後,我們仍然會得到一些有用的和沒用的樣本,我們如何將這些樣本區分開來,也就是運用SVM支援向量機演算法對這些樣本進行分類,分類好以後,將有效的樣本傳到ANN模型對字元進行識別。
-
準備工作
我們前面講到,在獲取原始的影象樣本以後我們還需要對影象進行預處理,處理後我們還是會的到一些不無效的樣本,我們要將這些無效的樣本區分和有效樣本區分開來,這就是我們SVM的工作。
但是如何對影象進行處理呢? 處理的動作包括一系列操作,我們如何完成這些一系列的操作呢?
我們運用OpenCV,一個開源的視覺識別庫。
-
OpenCV 介紹
OpenCV是一個開源的計算機視覺庫,它包含了一些完整的視覺處理演算法的實現,當然還有一些機器學習的演算法,例如SVM,決策樹等。其中我們的講解中就是用到它的SVM分類演算法的實現。
這裡不打算大筆墨的介紹OpenCV影象學操作的原理進行詳細的講解,因為這篇是講SVM的,但是會展示我們要進行相關影象處理的一些步驟以及這些步驟達到的效果,當然我們後面會以原始碼的形式講解OpenCV對原始影象的處理過程.
-
影象樣本處理
在一般的原始樣本中,我們總需要定位到我們感興趣-ROI的區域,這個實驗中的感興趣的區域就是我們這些數字字元,如果樣本質量好的,也就是說沒有我們之前提到的一些不好定位和區分圖片中字元的因素在裡面,也就是說那些高曝光,模糊的圖片等等,這些樣本圖片還是比較好定位和萃取ROI內容的,下面列舉了圖片處理的一些基本步驟,步驟的順序不是絕對,這一點一定要注意,畢竟是最終只是想要達到我們的目的。
-
原始樣本輸入:
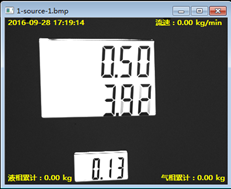
-
灰度化
灰度化簡單的就是說把色彩的影象處理成計算機處理相對容易的灰度影象,用以下函式實現灰度化的處理:
cvtColor(src_in, grey, CV_BGR2GRAY);//轉化為灰度影象處理後的影象效果如下:
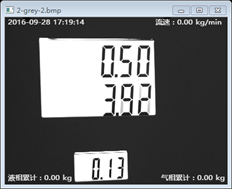
我們看到灰度化後的效果不太明顯,因為影象本身就是黑白的,但是灰度化的操作是必須的,因為不是所有樣本影象的效果都很好。
-
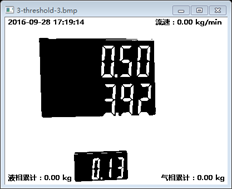
二值化
二值化的操作就是對影象畫素做一個閥值化的處理,根據不同的光照的程度選擇不同的閥值,使得影象中的畫素只有黑白兩種屬性,用以下的處理可以取自適應閥值:
threshold(grey, grey, 0, 255, CV_THRESH_OTSU + CV_THRESH_BINARY_INV);下面是二值化的效果:
-
取輪廓
由於我們的原始影象有比較分明的橫線和直線,也不需要要用Sobel運算元等一些其他的演算法去找影象的邊緣,所以處理起來就更簡單了,直接用Opencv找影象的輪廓即可,我們可以看到樣本中有兩個我們感興趣的區域,都是長方體。直接上Opencv取輪廓操作,其中CV_RETR_TREE是取所有輪廓:
findContours(grey,
contours,// a vector of contours
CV_RETR_TREE,
CV_CHAIN_APPROX_NONE); // all pixels of each contours
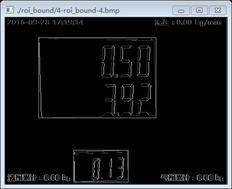
仔細看白底外邊的方框,我們找到了我們定位的數字字元方框,有兩個,一大一小如下:
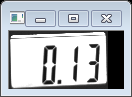
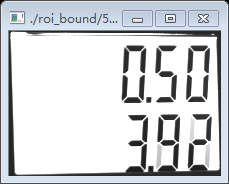
我們看到上面的兩個圖不是非常正,還是有點歪,後面還要進一步處理,最後定位到我們要找的數字字串3.92和0.13.
-
旋轉校正
為了把影象校正一些,需要取影象的最小外接矩形:
Rect mr = roi_rect.boundingRect();然後再從原影象中擷取原影象的ROI圖塊,進而獲得擁有獨立座標的ROI影象:
Rect_<float> safeBoundRect = Rect_<float>(mr.x, mr.y, mr.width, mr.height);
bound_mat = src_in(safeBoundRect);
最後通過rotation()函式獲得校正後的影象,注意要旋轉影象首先必須要知道的旋轉的中心點以及角度:
float roi_angle = roi_rect.angle;
Point2f roi_ref_center = roi_rect.center - safeBoundRect.tl();
rotation(bound_mat, rotated_mat, roi_rect.size, roi_ref_center, roi_angle);
其中rotated_mat為輸出旋轉校正後的影象:
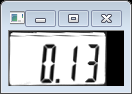
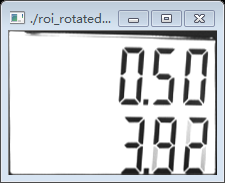
我們看到旋轉校正過後的兩個影象相對校正之前更加端正了,這樣有利於我們後面對數字字元的分割。
-
形態學開操作
這裡開操作的作用是將我們要定位的字元從影象中截取出來,丟棄其它不相關的部分。如下圖
黑色的陰影部分就是有效的數字區域。
注:開操作就是先做腐蝕操作,再做膨脹操作,即將白色的區域先用模板腐蝕,將黑色的部分連通起來,然後再對仍然是白色的部分進行膨脹,將黑色和白色分開得更加鮮明。下面是開操作的函式:
morphologyEx(temp_mat, temp_mat, MORPH_OPEN, element);開操作的效果如下:
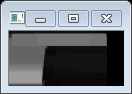
其中,我們可以看到黑色的部分就是我們的真正需要提取的區域。
-
閥值化
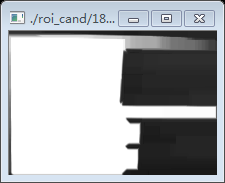
分別對上一步驟中的出兩個圖進行後續的處理,這裡用第一個圖做演示。這一步驟是閥值化的過程。
-
取輪廓
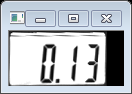
再次取輪廓後我們得出了兩個輪廓,一個是數字字串的有效區域,第二個是數字字元上邊的模糊的陰影部分,看程式碼實現:
findContours(grey,
contours, // a vector of contours
CV_RETR_EXTERNAL, // retrieve the external contours
CV_CHAIN_APPROX_NONE); // all pixels of each contours
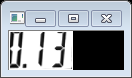

注意這裡和之前的取所有輪廓不一樣,這次再次取的輪廓是CV_RETR_EXTERNAL即最大外接輪廓。
-
大小歸一化
對上面得出的兩個候選圖片做大小歸一化,即先create一個固定大小的影象,然後將前面處理好的影象按照這個大小進行resize,大小歸一化的實現程式碼:
Mat cand_mat;
cand_mat.create(36, 136, CV_8UC3);
if (temp_cand_mat.cols >= 36 || temp_cand_mat.rows >= 136)
resize(temp_cand_mat, cand_mat, cand_mat.size(), 0, 0, INTER_AREA);
else
resize(temp_cand_mat, cand_mat, cand_mat.size(), 0, 0, INTER_CUBIC);
於是我們得到以下歸一化效果:


我們看到大小歸一化後,所有得到的候選圖片都是一樣大小的,這樣有助於我們後面的對圖片的有效
性進行分析,並且也有助於後面進行字元分割。(本文還會講到字元分割。)
-
SVM模型訓練
在對樣本圖片進行預處理後,我們得到了一些候選圖片,但是就如上面歸一化後得到的候選圖片的結果一樣,這些圖片中還是有一些是有效的圖片和一些無效的圖片,有效的圖片中包含了我們要識別的內容,無效的圖片中並沒有包含這些內容,所以我們就需要將有效的圖片和無效的圖片區分開來,這個區分開來的工作就是SVM需要做的事情。
-
貼標籤
開始用SVM做訓練之前,我們必須把處理後的樣本分為兩類,一類是有效的圖片,另一類是無效的圖片,然後從這兩類圖片中分別取出一部分用來做SVM模型訓練,然後另一部分用來做測試集,這個測試集中同樣包含有效的圖片和無效的圖片,用以驗證SVM模型訓練號的分類效果。
可建成上面面的目錄結構,用以存放有效的圖片和無效的圖片,分別包含用於訓練的資料和用於測試驗證的資料。這個過程就是所謂大的貼標籤過程。但是要注意的是,我們的用於訓練的資料圖片一般是要多於用於驗證的圖片集的,我們這裡分成的是訓練70%,測試30%。
-
樣本特徵提取
將樣本分好類後的資料還不是我們可以用來給訓練模型訓練的資料,我們還需要對這些訓練的圖片進行取特徵的操作,這裡不打算對如何取樣本特徵進行展開。
樣本的特徵有幾種形式:
|
特徵 |
描述 |
|
HOG |
即Histogram of Oriented Gradient, HOG特徵是一種在計算機視覺和影象處理中用來進行物體檢測的特徵描述子。它通過計算和統計影象區域性區域的梯度方向直方圖來構成特徵。 |
|
LBP |
即Local Binary Pattern,區域性二值模式,是一種用來描述影象區域性紋理特徵的運算元;它具有旋轉不變性和灰度不變性等顯著的優點。 |
|
HAAR |
Haar特徵分為三類:邊緣特徵、線性特徵、中心特徵和對角線特徵,組合成特徵模板。 |
-
SVM引數說明
SVM型別:SVM設定型別(預設0)
0 -- C-SVC
1 --v-SVC
2 – 一類SVM
3 -- e -SVR
4 -- v-SVR
-t 核函式型別:核函式設定型別(預設2)
0 – 線性:u'v
1 – 多項式:(r*u'v + coef0)^degree
2 – RBF函式:exp(-gamma|u-v|^2)
3 –sigmoid:tanh(r*u'v + coef0)
-d degree:核函式中的degree設定(針對多項式核函式)(預設3)
-g r(gama):核函式中的gamma函式設定(針對多項式/rbf/sigmoid核函式)(預設1/ k)
-r coef0:核函式中的coef0設定(針對多項式/sigmoid核函式)((預設0)
-c cost:設定C-SVC,e -SVR和v-SVR的引數(損失函式)(預設1)
-n nu:設定v-SVC,一類SVM和v- SVR的引數(預設0.5)
-p p:設定e -SVR 中損失函式p的值(預設0.1)
-m cachesize:設定cache記憶體大小,以MB為單位(預設40)
-e eps:設定允許的終止判據(預設0.001)
-h shrinking:是否使用啟發式,0或1(預設1)
-wi weight:設定第幾類的引數C為weight*C(C-SVC中的C)(預設1)
-v n: n-fold互動檢驗模式,n為fold的個數,必須大於等於2
其中-g選項中的k是指輸入資料中的屬性數。option -v 隨機地將資料剖分為n部
-
開始訓練
在提取特徵後我們就可以將特徵集合帶入到opencv訓練演算法中訓練,在這裡我們直接選用RBF核進行訓練,對於RBF核而言模型的效能由懲罰因子和r(gamma)決定。所以為了使SVM的效能最優,我們就必須尋找C和r的最優組合。如何找到C和r的最優組合,最簡單的辦法就是所謂的窮舉法,即分別取C和r的不同組合訓練SVM模型,然後通過測試得到模型的效能,簡單點說就是識別率,這樣就必須嘗試n*n中組合,這個過程比較耗時,當訓練樣本很大模型訓練量就更多更耗時了,當然還有其他模型引數的選擇方法,例如運用Fisher準則的方法等,後面會用單獨的文章來介紹這種方法。
void svm_train_test(void)
{
//#define AutoTrain
svm_ = cv::ml::SVM::create();
svm_->setType(cv::ml::SVM::C_SVC);
svm_->setKernel(cv::ml::SVM::RBF);
auto train_data = tdata();
#ifndef AutoTrain
double v_gamma = svm_->getGamma();
double v_C = svm_->getC();
fprintf(stdout,">> Training SVM RBF model gamma = %f C = %f, please wait...\n", v_gamma, v_C);
#else
svm_->trainAuto(train_data, 10, svm_->getDefaultGrid(svm_->C),
svm_->getDefaultGrid(svm_->GAMMA), svm_->getDefaultGrid(svm_->P),
svm_->getDefaultGrid(svm_->NU), svm_->getDefaultGrid(svm_->COEF),
svm_->getDefaultGrid(svm_->DEGREE),true);
double v_gamma = svm_->getGamma();
double v_coef0 = svm_->getCoef0();
double v_C = svm_->getC();
double v_Nu = svm_->getNu();
double v_P = svm_->getP();
fprintf(stdout,">> Auto Training SVM paramter gamma %f,coef0 %f C %f Nu %f P %f\n", v_gamma, v_coef0, v_C, v_Nu, v_P);
system("pause");
#endif
do {
svm_->setGamma(v_gamma);
svm_->setC(v_C);
long start =utils::getTimestamp();
svm_->train(train_data);
long end =utils::getTimestamp();
fprintf(stdout,">> Training done. Time elapse: %ldms\n", end - start); fprintf(stdout,">> Saving model file...\n");
svm_->save(svm_xml_);
fprintf(stdout,">> Your SVM Model was saved to %s\n", svm_xml_);
fprintf(stdout,">> Testing...\n");
svm_test_tmp(v_gamma, v_C, start, end);
#ifndef AutoTrain
v_gamma += 0.2;
v_C += 0.2;
#else
break;
#endif
}while (v_gamma && v_C < 30.0);
}
載入訓練訓練和測試資料:
開始訓練:
-
SVM引數調優
從原理的分析中我們知道SVM中的懲罰因子C和r是影響SVM效能的關鍵因素。引數C的作用是確定資料子空間中調節學習機器的置信區間範圍,不同資料子空間中最優的C是不同的,而核引數r的改變實際上隱含地改變對映函式從而改變樣本資料子空間分佈的複雜程度,即線性分類的最大VC維,也就決定了線性分類達到的最小誤差。
下面兩個圖是根據固定C和r其中的某一因子訓練出的模型對測試樣本進行預測的出的各項效能曲線,分別反映引數C和r對SVM效能的影響。
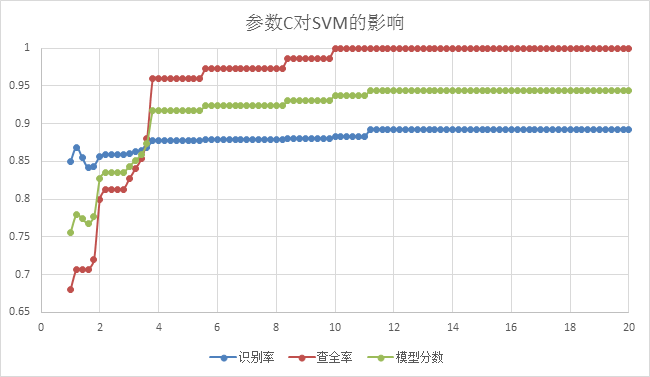
從上圖我們可以看到在固定r,C作為變數,對模型進行訓練後,C對SVM效能的影響情況。很明顯當C越來越大,在達到12以上後,模型無論是從識別率、查全率還是綜合的評估分數都達到了最優,隨著C再往上增大,曲線則區域穩定,甚至沒有變化了。
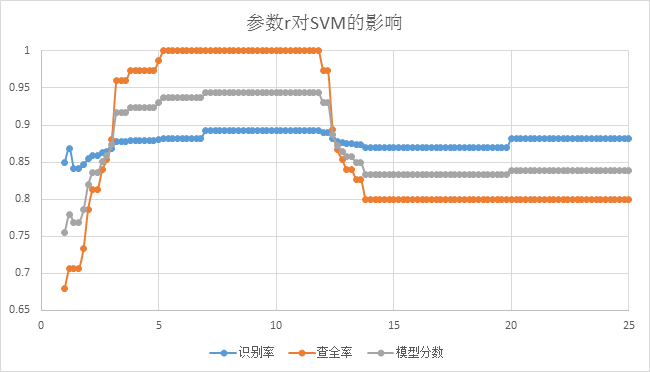
上圖為固定懲罰因子C, 引數r對SVM效能影響,我們可以看到當r取值逐漸上升在大概7到11的區間時候SVM模型效能達到最優,然後隨著r取值再增大,SVM的效能隨之下降,最終在20以後趨於平穩。
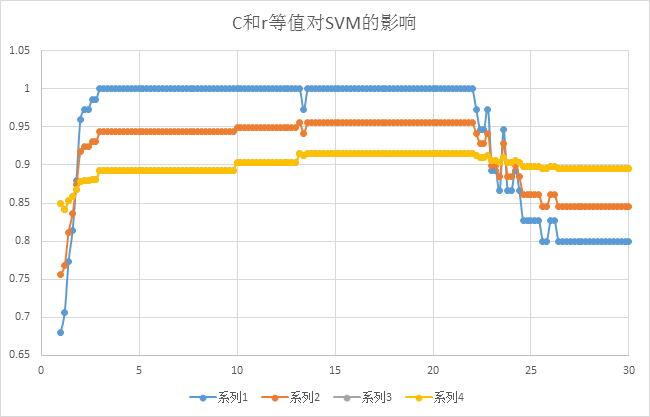
從上圖我們可以看到在C和r等值的情況下,逐漸增加,在14至22的區間內SVM的效能達到最優,所以進一步的縮小了SVM引數C和r的取值範圍,可以為最終的取值做參考,當然針對訓練取得最優的C和r的同時優化圖片處理效果和對特徵提取的優化也是極為重要的。一個好的模型的生成就是對系統的整個處理流程的優化過程。