
《mysql必知必會》筆記(一)
一:瞭解SQL
1:列是表中的欄位,所有表都由一個或多個列組成的。行是表中的記錄,表中的資料都按行儲存。
2:表中每一行都應該有可以唯一標識自己的一列或一組列。主鍵(一列或一組列),其值能夠唯一區分每個行。雖然並不總是都需要主鍵,但應該是每個表都有一個主鍵。
主鍵滿足條件:任意兩行不能有相同的主鍵值;每個行都必須具有一個主鍵值。
可以使用多個列作為主鍵,所有列值的組合必須唯一(但單個列的值可以不唯一)。
3:SQL是結構化查詢語言,一種專門用來與資料庫通訊的語言。幾乎所有的重要DBMS都支援SQL,但是事實上任意兩個DBMS實現的SQL都不完全相同,本書的SQL專門針對mysql。
二:Mysql簡介
DBMS,資料庫管理系統,Mysql就是一種DBMS。
mysql命令,都以”;”結束。
三:使用mysql
1:mysql使用之前,必須要登陸連線資料庫。mysql在內部儲存自己的使用者列表,並且把每個使用者和各種許可權關聯起來。
2:最初連線資料庫後,沒有任何資料庫開啟,在執行任何資料庫操作之前,必須要選擇一個數據庫。使用use關鍵字,eg:use test;
3: show databases;返回可用資料庫的一個列表。
show tables;返回當前選擇的資料庫的所有表。
4: show columns from

5: show status;顯示伺服器狀態資訊;
show grants; 顯示授予使用者的安裝許可權;
show errors; show warnings; 顯示伺服器錯誤或警告資訊。
四:檢索資料
1:每個sql語句都是由一個或多個關鍵字構成的。
2:select語句,必須給出兩條資訊:選擇什麼,從什麼地方選擇,比如select cust_id from testtable; 得到的資料沒有過濾,也沒有排序。
3:多條sql語句必須以分號分隔。sql語句不區分大小寫。
4:檢索多個列,select後面給出多個列名,列名之間必須以逗號分隔,最後一個列名不加。比如:select cust_id, cust_name from testtable;
5:distinct關鍵字,可以返回不同的值,比如select distinct cust_id from testtable; distinct關鍵字必須直接位於列名的前面,它應用於所有列而不僅是前置它的列。
6:limit子句,返回限定數量的行。eg:select cust_id from testtable limit 5; 或 select cust_id from testtable limit 5,5; 返回從行5開始的5行。第一個數為開始位置,第二個數為行數。第一行為0.
五:排序檢索資料
1:檢索出的資料順序,可能是新增到表中的資料的順序。但是如果不明確控制的話,不能依賴該排序順序。
2:order by子句,取一個列或多個列的名字,對輸出進行排序。eg:select cust_name from testtable order by cust_name; 用非檢索的列排序資料是完全合法的,eg:select cust_id from testtable order by cust_name;
可以按多個列進行排序,列名之間用逗號分隔。多列排序時,按照循序進行,eg:select * from testtable order by cust_name, cust_id; 首先按照cust_name進行排序,如果有相同的cust_name的話,則按照cust_id排序,如下圖:

3:預設的排序為升序排序,可以用desc關鍵字指定降序排序,eg:select cust_id from testtable order by cust_id desc; desc關鍵字只能應用到直接位於其前面的列名,eg:select * from testtable order by cust_name desc, cust_id; 該語句只對cust_name列指定降序,而cust_id還是升序。
4:再給出order by子句的時候,應該保證它位於from子句之後,如果使用limit,則必須位於order by之後。順序不對會出錯。
六:過濾資料
1:在select語句中,資料根據where子句中指定的搜尋條件,對資料進行過濾。where子句在表名(from子句)之後給出。eg;select cust_id, cust_name from testtable where cust_id = 1;2:如果同時使用order by和 where子句,應該讓order by子句位於where之後。
3:where子句支援的操作符有:
|
操 作 符 |
說 明 |
|
= |
等於 |
|
<> |
不等於 |
|
!= |
不等於 |
|
< |
小於 |
|
<= |
小於等於 |
|
> |
大於 |
|
>= |
大於等於 |
|
BETWEEN |
在指定的兩個值之間 |
|
IS NULL |
為NULL值 |
4:舉例如下:
a: select* from testtable where cust_id = 5;
b: select* from testtable where cust_id < 5;
c: select* from testtable where cust_name = 'john'; //單引號用來限定字串,如果將值與串型別的列進行比較,則需要限定引號。用來與數值列進行比較的值不需要引號。所以,這裡如果john不加引號的話,會出錯。
d: select* from testtable where cust_id between 1 and 3; //使用between時,必須指定範圍的兩個值,這兩個值必須用and關鍵字分隔。
5:在一個列不包含值時,稱其為包含空值NULL。NULL與包含0,空字串不同。
一個特殊的where子句,用來判斷具有NULL值的列:is null;eg:select * from testtable where cust_city is null; 得到結果如下:

注意:在匹配過濾和不匹配過濾時,並不返回NULL值的列,比如下面的語句,都不會返回任何資料:
mysql> select * from testtable where cust_city = NULL; //” = null” 不等於 “is null”
Empty set (0.00 sec)
mysql> select * from testtable where cust_city != '1';
Empty set (0.00 sec)
mysql> select * from testtable where cust_city != '';
Empty set (0.00 sec)
mysql> select * from testtable where cust_city = '';
Empty set (0.00 sec)
七:資料過濾
1:mysql允許給出多個where子句,多個where子句可以通過and或者or進行組合。eg:
select * from testtable where cust_id < 5 and cust_name = ‘john’;
select* from testtable where cust_id < 5 or cust_name = ‘john’;
2:如果組合使用and和or,應該使用括號明確優先順序,儘管預設情況下and具有比or更高的優先順序。eg:
select * from testtable where (cust_id < 5 or cust_name = 'john') and cust_address is null;
3:in操作符,可以指定或的關係。eg: select * from testtable where cust_id in (1,3);返回如下結果:

注意:in操作符一般比or操作符更快。要注意in和between之間的區別。
4:not操作符表示否定關係,eg:
select * from testtable where not cust_id >=5 order by cust_name;
八:用萬用字元進行過濾
1:在搜尋語句中使用萬用字元,必須使用like操作符,like指示mysql,後面的搜尋模式利用萬用字元匹配,而不是直接相等匹配。
2:mysql支援兩種萬用字元,%表示任意字元出現任意次數;_匹配單個字元。eg:
select * from testtable where cust_name like '%i%'; //注意引號

select * from testtable where cust_name like '_i%';

3:注意,萬用字元的搜尋一般要比其他搜尋花費更長的時間,所以不要過度使用萬用字元。
九:用正則表示式進行搜尋
1:mysql用where子句對正則表示式提供初步的支援,允許指定正則表示式過濾select檢索出的資料。但是,mysql僅支援多數正則表示式實現的一個很小的子集。
2:例如:select * from testtable where cust_name regexp ‘ik’; regexp後跟的就是正則表示式。注意regexp和like的區別,如果上面的例子中,regexp換成like的話,則不會輸出任何結果。因為like要求欄位值完全匹配,儘管’mike’包含’ik’,但是like依然不會輸出任何行。但是regexp僅僅要求包含即可。
3:mysql中的正則表示式匹配不區分大小寫,也就是上面的例子,可以這樣寫:
select* from testtable where cust_name regexp ‘IK’。如果需要區分,則可以使用binray關鍵字:select * from testtable where cust_name regexp binary ‘IK’。
4:mysql支援的正則表示式:
|:或的關係,匹配其中之一;
[]:匹配其中的字元之一;
[a-z]:匹配a到z的任意字元;
*:0或多個匹配
+:1或多個匹配
?:0或1個匹配;
{n}:指定書目的匹配;
{n,}:不少於指定數目的匹配;
{n,m}:從n到m個匹配;
^:文字的開始
$:文字的結尾
[[:<:]]:詞的開始
[[:>:]]:詞的結尾
5:mysql中的轉義字元是\\,比如,如果需要匹配”.”,則regexp “\\.”
6:可以在用帶字串的regexp來測試,比如:select ‘hello’ regexp ‘[0-9]’
十:建立計算欄位
1:有時,儲存在表中的資料並不是應用程式直接需要的,需要直接從資料庫中檢索出轉換、計算或格式化過的資料。這就是計算欄位的作用。
2:計算欄位並不實際存在於資料表中,它是執行時在select語句內建立的。從應用程式的角度來看,計算欄位與資料庫中其他列的形式是一樣的。只有資料庫知道select語句中哪些列是實際的表列,哪些是計算欄位。
3:在sql語句中完成的轉換和格式化工作,都可以直接在應用程式內完成。但一般來說,在資料庫中完成這些操作要比在應用程式中完成要快很多。
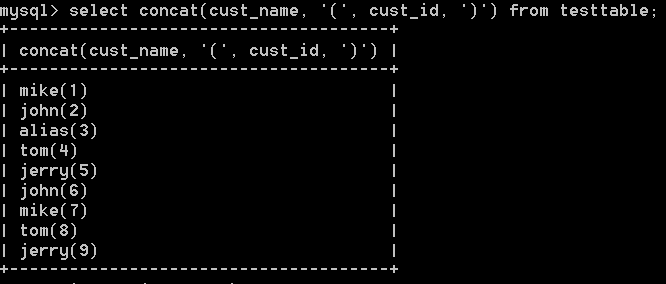
4:concat()函式可以實現字串的拼接,eg:
select concat(cust_name, '(', cust_id, ')')from testtable;
5:rtrim()函式,刪除資料右側多餘的空格。eg:select rtrim(cust_name) from testtable;
類似的,ltrim()函式,刪除資料左側多餘的空格;trim()函式,刪除串兩邊多餘的空格。
6:計算欄位預設沒有名字,可以使用別名。這樣在應用程式中就可以引用它了。別名使用as關鍵字。eg:
select concat(cust_name, '(', cust_id, ')') as cust_nameid from testtable;
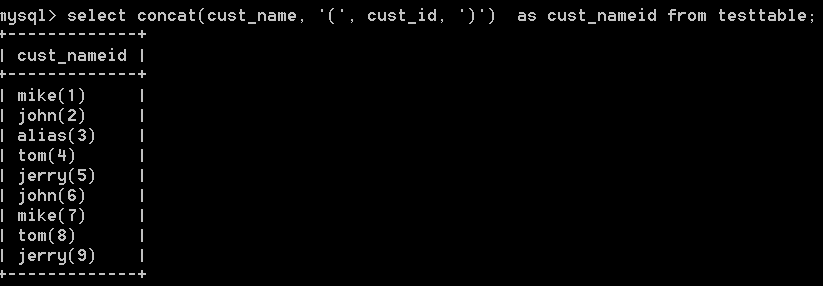
這樣,任何應用程式都可以按cust_nameid這個別名引用這個列,就像它是一個實際的表列一樣。
7:計算欄位,還可以對檢索出的資料進行數學運算,比如:select cust_id * 2 from testtable;
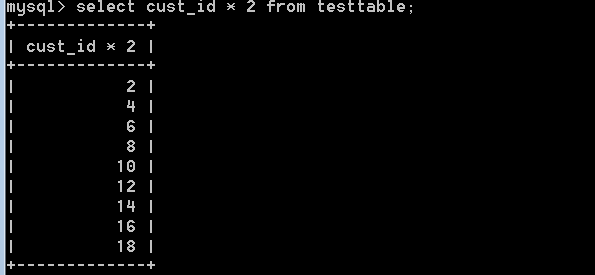
可以得到所有cust_id 乘以2之後的值。mysql支援的算術操作有:+, -, *, /。
8:select語句,可以省略from子句,來測試和實驗函式。比如:select 3*2; 將返回6. select trim(‘ abc ’); 將返回’abc’。
十一:使用資料處理函式
1:sql支援利用函式來處理資料。但是函式的可移植性不強,這點要注意。
2:大多數sql實現支援以下型別的函式:處理字串的函式;處理數值的函式;處理日期和時間的函式;返回DBMS資訊的函式。
3:upper(),將文字轉換為大寫。比如:select upper(cust_name) as nocasename from testtable;
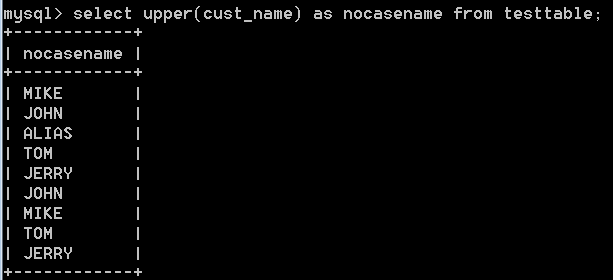
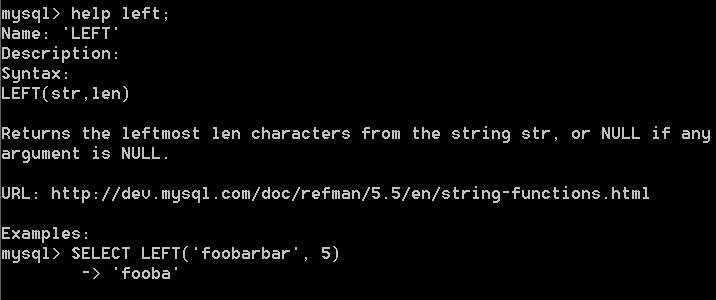
其他的文字處理函式有:left(), length(), locate(), lower(), ltrim(), right(), rtrim(), substring(), upper(), soundex()等。可以使用help函式名,檢視函式用法,比如:help left;
4:mysql中,日期和時間,採用特殊的格式儲存,以便能夠快速和有效的排序或過濾,並節省記憶體。在應用程式中,一般都要使用日期和時間函式來對資料庫中的日期時間進行處理。
5:mysql使用的日期格式,不管是插入或更新表值,還是使用where子句進行過濾,日期必須為yyyy-mm-dd格式。比如:select * from testtable where cust_date = '2014-10-01 10:21:34';

雖然其他的日期格式可能也行,但是這是首選的日期格式,因為它排除了多義性。
6:日期時間格式的資料,包含日期和時間。date()函式,可以從日期時間格式的資料中,提取出日期。比如:
select * from testtable where date(cust_date) = '2014-12-01';

其他的日期時間處理函式:adddate(), addtime(),curdate(), curtime(), date(), datediff(), date_add(), date_format(), day(),dayofweek(), hour(), minute(), month(), now(), second(), time(), year()。
7:數值處理函式,這些函式一般用於代數,三角或幾何運算。因此沒有字元處理或日期時間處理函式使用那麼頻繁。常用的數值處理函式有:abs(), cos()等。
十二:彙總資料
1:mysql提供了彙總資料的函式,比如統計行數,計算最大值,最小值,平均值等。
2:avg()函式計算某列的平均值。比如:select avg(cust_num) from testtable;
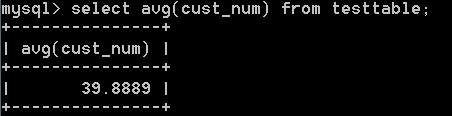
avg還可以計算特定行的平均值,比如:select avg(cust_num) from testtable where cust_name = ‘john’;

avg函式只能確定單個列的平均值;avg函式忽略列值為NULL的行。
3:count()函式,統計行數。它有兩種使用方式:
count(*) 對行數進行統計,不管列中包含的是空值NULL,還是非空值;
count(column)對特定列中具有值的行進行統計,忽略NULL值的行。
比如:select count(*) from testtable;返回 9;
select count(*) from testtable where cust_name = 'john';返回2;
select count(cust_name) from testtable where cust_name ='john';返回2;
select count(cust_email) from testtable ;返回0.
4:max()函式,返回指定列中的最大值,max必須指定列名,比如:
select max(cust_num) from testtable;返回98
select max(cust_num) from testtable where cust_name = 'john';返回98
select max(cust_num) from testtable where cust_name = 'tom';返回34
max函式也可以用在時間日期格式,或者字串上。比如:

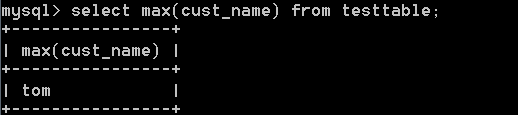
max函式忽略值為NULL的行
min函式返回最小值,與max相反,不再贅述。
5:sum()函式,用來返回指定列值的和。比如:
select sum(cust_num) from testtable; 返回359
select sum(cust_num) from testtable where cust_name = 'john'; 返回152
sum忽略NULL值的列。
6:distinct關鍵字,可以只對具有不同值行進行計算。它只適用於mysql 5及以後版本。all關鍵字是它的反義,不過all是預設的,所以可以不加。
比如:select avg(distinctcust_num) from testtable; 返回43.3750
select sum(distinct cust_num) from testtable; 返回347
select count(distinct cust_name) from testtable; 返回5
可見加了distinct關鍵字之後,返回結果的不同。注意,distinct 不能用於count(*),也就是不能count(distinct *),會出錯。
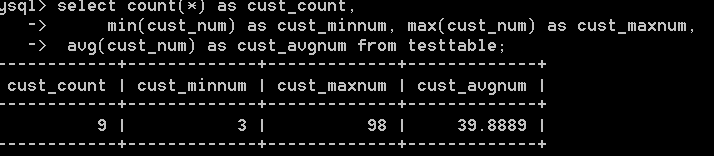
7:組合使用,比如:
select count(*) as cust_count,
min(cust_num) as cust_minnum, max(cust_num) as cust_maxnum,
avg(cust_num) as cust_avgnum from testtable;
十三:分組資料
1:目前為止,所有的計算都是在表的所有資料或匹配特定的where子句的資料上進行的,比如:select count(*) as num_pords from products where vend_id = 1003; products表是產品表,每行一個產品,該表中記錄了產品ID,供應商ID,產品名,價格,描述等資訊,如下:
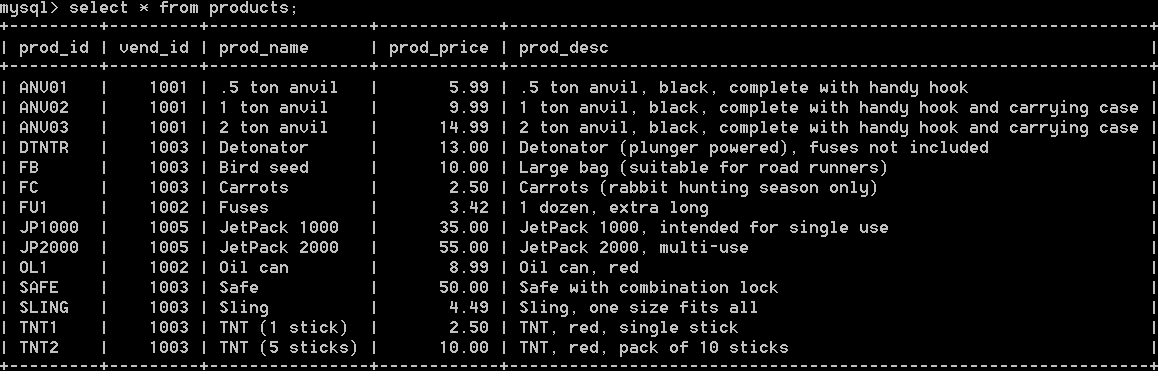
上面那句sql語句,就是在該表中,查詢供應商1003所供應產品的總數。
但是,如果需要返回所有供應商提供的產品數怎麼辦?此時需要分組,分組允許把資料分為多個邏輯組,以便能夠對每個組進行聚集計算。
2:分組通過select語句中的group by子句建立。比如:select vend_id, count(*) as num_prods from products group by vend_id; 該語句返回結果如下:
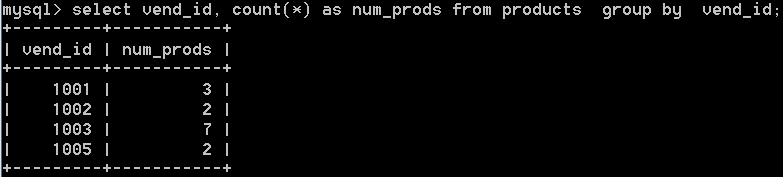
group by子句,指示mysql分組資料,然後對每個組而不是整個結果集進行聚集運算。所以上面的例子中,group by子句指示mysql按vend_id排序並分組資料,因而count(*)是針對每個分組進行計算。
3:除了聚集計算之外,select語句中的每個列都必須在group by子句中給出;如果分組列中具有NULL值,則NULL將作為一個分組返回,如果列中有多行NULL值,它們將分為一組。
4:group by必須在where子句之後,order by子句之前。
5:mysql允許過濾分組,規定包括哪些分組,排除哪些分組。但是因為where沒有分組的概念,where過濾的是行而不是分組,所以,提供了having子句。
having子句非常類似於where,它們的句法是相同的,只是關鍵字有差別。
6:比如:
select cust_id, count(*) as orders from orders group by cust_id having count(*) >=2;
orders表儲存顧客訂單。每個訂單具有訂單號,訂單日期,訂單顧客id資訊。如下:
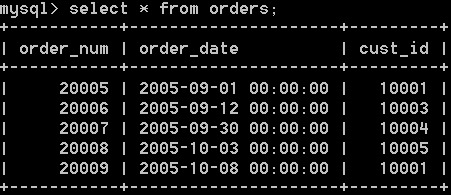
所以,上面的sql語句,返回訂單數超過2個的客戶id,結果如下:

7:where是在分組前進行過濾,having是在分組後進行過濾。where排除的行不包括在分組中。下面是一個組合使用where和having的例子:
select vend_id, count(*) as num_prods from products where prod_price >= 10 group by vend_id having count(*) >= 2;
該語句返回具有2個以上,並且價格在10以上的產品的供應商。結果如下:

上面的語句,首先通過where prod_price >= 10對整體資料進行過濾,然後在過濾的基礎上,找到提供兩個產品以上的供應商ID。執行的順序就是:首先where過濾,然後通過vend_id進行分組,然後having進行分組過濾。
8:雖然group by分組的資料可能以分組順序給出,但不能保證情況總是這樣,因為這不是sql規範要求的。所以,如果需要按序輸出,則應該提供明確的order by語句。比如:
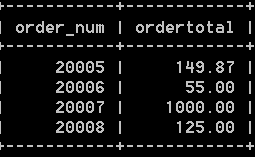
select order_num, sum(quantity * item_price) as ordertotal from orderitems group by order_num having sum(quantity *item_price) >= 50;
orderitmes表儲存每個訂單的實際物品,每個訂單的每個物品站一行,其中記錄了訂單號,訂單物品,物品數量,物品價格等。如下:
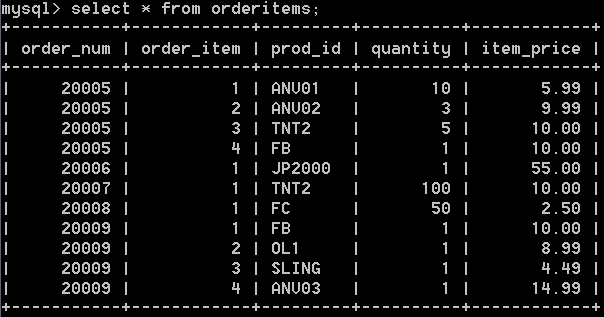
所以,上面的sql語句,返回,所有訂單總價超過50的訂單,結果如下:
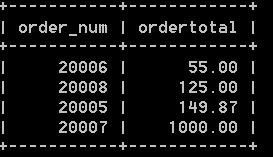
如果需要按照總價排序,可以這樣:
select order_num, sum(quantity*item_price) as ordertotal from orderitems group by order_num having sum(quantity*item_price) >= 50 order by ordertotal; 結果如下:
9:迄今為止,所有的子句順序如下:
|
子句 |
說明 |
是否必須使用 |
|
SELECT |
要返回的列或表示式 |
是 |
|
FROM |
從中檢索資料的表 |
僅在從表選擇資料時使用 |
|
WHERE |
行級過濾 |
否 |
|
GROUP BY |
分組說明 |
僅在按組計算聚集時使用 |
|
HAVING |
組級過濾 |
否 |
|
ORDER BY |
輸出排序順序 |
否 |