
Android 音訊技術開發總結
在文章開頭,我們先來了解幾個概念,這樣有利於對後面內容的理解。
1、概念理解
取樣率:即取樣頻率,百科的解釋是,每秒從連續訊號中提取並組成離散訊號的取樣個數,單位 赫茲(Hz)。通俗的講取樣頻率是指計算機每秒鐘採集多少個聲音樣本,是描述聲音檔案的音質、音調,衡量音效卡、聲音檔案的質量標準。好吧,感覺這樣還是不太理解,那我們來看看下面的解釋:
如圖,
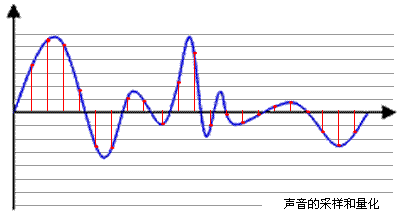
取樣就是把模擬訊號數字化的過程,不僅僅是音訊需要取樣,所有的模擬訊號都需要通過取樣轉換為可以用 0101 來表示的數字訊號,上圖藍色代表模擬音訊訊號,而紅色的點代表取樣得到的量化數值。紅色點之間的間隔越小,表示取樣頻率越高,同時音訊質量也就越高。
通道數:一般表示聲音錄製時的音源數量或回放時相應的揚聲器數量。單聲道(Mono)和雙聲道(Stereo)比較常見。
量化精度(位寬):上圖中的每一個紅色點,都有一個數值來表示其大小,這個數值的資料型別有:4bit、8bit、16bit、32bit等,位數越多,表示得就越精細,聲音質量也就越好。
音訊幀(frame):音訊資料是流式的,本身並沒有明確的一幀幀的概念,在實際的應用中,為了音訊演算法處理/傳輸的方便,一般約定俗成取 2.5 ms ~ 60 ms為單位的資料量為一幀音訊。 這個時間被稱之為“取樣時間”,其長度沒有特別的標準。我們可以計算一下一幀音訊幀的大小:
假設某通道的音訊訊號是取樣率為 8 kHz,位寬為16 bit,20 ms 一幀,雙通道,則一幀音訊資料的大小為:
int size = 8000 x 16bit x 0.02s x 2 = 5120 bit = 640 byte
音訊編碼:模擬的音訊訊號轉換為數字訊號需要經過取樣和量化,量化的過程被稱之為編碼。根據不同的量化策略,產生了許多不同的編碼方式。
2、音訊採集
在 Android 開發中,官方 SDK 提供了兩套音訊錄製的 API,一個是 MediaRecorder ,另一個是 AudioRecord。前者會對錄入的音訊資料進行編碼壓縮(如 AMR,3GP等), 而後者是更加偏向底層的 API,錄入的是一幀幀 的 PCM 音訊資料,是無損沒有經過壓縮的。如果你對音訊格式沒有特殊的要求,只是簡單的想做一個錄音功能,那推薦你使用 MediaRecorder 。MediaRecorder 支援的輸出方式有:amr_nb,amr_wb, default, mpeg_4, raw_amr, three_gpp。如果需要對音訊資料進行額外的演算法處理,則建議使用更加靈活的 AudioRecord API。比如,我想要錄製一個 MP3 格式的音訊檔案, Android SDK 本身是不支援直接錄製 MP3 格式的檔案,我們就可以通過 AudioRecord 來採集音訊資料,並通過第三方庫來進行編碼。下面我將會介紹怎麼在 Android 上使用 AudioRecord 錄製 MP3 和 WAV 格式的音訊檔案。
2.1 MP3 音訊錄製
LAME 是目前最出色的 MP3 編碼引擎。我們要在 Android 平臺上使用它,需要下載 lame 原始碼並將其編譯成 so 庫,然後通過 jni 來呼叫。這裡有一個開源專案 AndroidMP3Recorder 幫我們省去了這一步驟,而且這個庫封裝了底層的 MP3 編碼,我們直接拿過來使用就可以了。作者具體的實現思路,可以參考這裡 實現思路講解。
我簡要說下怎麼引入這個庫和使用,以及本人踩過的坑。
在 Android studio 上整合這個庫:
dependencies {
compile 'com.czt.mp3recorder:library:1.0.2'
}
另外,因為上面的整合會自動引入多種 so 庫,如果只需要其中的幾種,可以在gradle中新增下面的配置(比如):
productFlavors {
arm {
ndk {
abiFilters "armeabi-v7a", "armeabi"
}
}
x86 {
ndk {
abiFilter "x86"
}
}
}
這樣在編譯時就只會在 arm 中接入 armeabi-v7a armeabi 包,在 x86 上接入 x86 的包,而不會接入其他的包。最後還需要在 gradle.properties 中新增:
android.useDeprecatedNdk = true
這樣就可以正常使用了。如果不過濾不需要的 so 庫,在編譯時就會報這個錯
java.lang.UnsatisfiedLinkError
舉個例子,使用無線保鏢 SDK 時,我們會接入 armeabi-v7a 和 x86 這兩個包的 so 檔案,但由於我們使用了 AndroidMP3Recorder 這個庫,它會產生額外的諸如 armeabi、armeabi-v8a、mips等多個資料夾,這些資料夾裡面都有 liblame.so 檔案,但沒有無線保鏢的 so 檔案,這樣就會引發java.lang.UnsatisfiedLinkError 錯誤,導致編譯不通過。
OK,剩下的就是開始使用這個庫了。
// 建立 MP3Recorder 例項, 傳入錄音檔案的儲存路徑和檔名
MP3Recorder mRecorder = new MP3Recorder(new File(Environment.getExternalStorageDirectory(), "demo.mp3"));
// 開始錄音
mRecorder.start();
// 停止錄音
mRecorder.stop();
是不是很簡單,轉碼的事情通通不用操心,全幫你做了。
踩到的坑:
後面我發現在小米4、錘子 T2 等手機上開啟接入了這個庫的 app 直接閃退了。經過分析發現,在小米 4、錘子 T2 等手機上執行我們的 app ,系統會先去找 arm64-v8a 這個目錄下的 so 檔案,如果不存在還好,偏偏我的 app 存在 arm64-v8a 目錄,此時因為找不到目錄下無線保鏢的 so 檔案(前面說過,接入了無線保鏢只會引入 armeabi-v7a 和 x86 這兩個包的 so 檔案),就直接報 java.lang.UnsatisfiedLinkError:couldn't find "libsecuritysdk.so" 的錯了。
這時候我就納悶了,前面配置時我的確只保留了 armeabi-v7a 和 x86 這兩個目錄下的 so 檔案,去掉了不需要的 so ,但為什麼還會出現其他的 so 目錄呢?後面發現,在打包 apk 時,這些 so 庫還是會一併被打包進 apk !而在測試時,剛好使用的 MX3 手機載入 so 檔案正常,所以沒發現這個問題。這時候你也許會問,為什麼小米4、錘子 T2 等手機會先去找 arm64-v8a 這個目錄呢?因為它們是 64 位裝置呀,而 armeabi-v7a 和 x86 針對的都是 32 位的檔案。綜上所述,問題可以描述為怎麼在 64 位的裝置上執行 32 位的二進位制檔案,這裡指 so 檔案。
在 stackoverflow 上找到了解決的答案:
When you install an APK on Android, the system will look for native libraries directories (armeabi, armeabi-v7a, arm64-v8a, x86, x86_64, mips64, mips) inside the lib folder of the APK, in the order determined by Build.SUPPORTED_ABIS.
If your app happen to have an arm64-v8a directory with missing libs, the missing libs will not be installed from another directory, the libs aren't mixed. That means you have to provide the full set of your libraries for each architecture.
So, to solve your issue, you can remove your 64-bit libs from your build, or set abiFilters to package only 32-bit architectures:
android {
....
defaultConfig {
....
ndk {
abiFilters "x86", "armeabi-v7a"
}
}
}
如果照上面的配置,那打包時就只會把 "x86", "armeabi-v7a" 這兩個目錄及其下的 so 檔案打包進 apk 。我們的問題也解決了,因為系統也只能找這兩個目錄下的 so 檔案了。
2.2 WAV 音訊錄製
因為 wav 是無損格式的音訊檔案,所以我們使用的還是 AudioRecord 這個 API。但在此之前,我們需要先了解一下怎麼儲存 wav 格式的檔案。
wav 是微軟公司開發的一種聲音檔案格式,整個檔案分兩部分,第一部分是"檔案頭",包括:取樣率、通道數、位寬等引數資訊,第二部分是"資料塊":指一幀一幀的二進位制音訊資料。
見下圖 wav 格式的檔案頭:

它主要分為三個部分:
第一部分,The "RIFF" chunk descriptor,通過 “ChunkID” 來表示這是一個 “RIFF” 格式的檔案,通過 “Format” 填入 “WAVE” 來標識這是一個 wav 檔案。而 “ChunkSize” 則記錄了整個 wav 檔案的位元組數。
第二部分,The "fmt" sub-chunk,從圖中可以看出記錄了 wav 音訊檔案的詳細音訊引數資訊,例如:通道數、取樣率、位寬、編碼方式、資料塊對齊資訊等等。
第三部分,The "data" sub-chunk,這部分是真正儲存 wav 資料的地方,由“Subchunk2Size”這個欄位來記錄後面儲存的二進位制原始音訊資料的長度。
OK,我們來看下 Java 程式碼是怎麼實現往一個檔案寫入 wav "檔案頭"的。結合上圖,你理解起來就不會很困難了。
...
RandomAccessFile randomAccessWriter = null;
...
randomAccessWriter = new RandomAccessFile(filePath, "rw");
randomAccessWriter.setLength(0); // Set file length to 0, to prevent unexpected behavior in case the file already existed
randomAccessWriter.writeBytes("RIFF");
randomAccessWriter.writeInt(0); // Final file size not known yet, write 0
randomAccessWriter.writeBytes("WAVE");
randomAccessWriter.writeBytes("fmt ");
randomAccessWriter.writeInt(Integer.reverseBytes(16)); // Sub-chunk size, 16 for PCM
randomAccessWriter.writeShort(Short.reverseBytes((short) 1)); // AudioFormat, 1 for PCM
randomAccessWriter.writeShort(Short.reverseBytes(nChannels));// Number of channels, 1 for mono, 2 for stereo
randomAccessWriter.writeInt(Integer.reverseBytes(sRate)); // Sample rate
randomAccessWriter.writeInt(Integer.reverseBytes(sRate*bSamples*nChannels/8)); // Byte rate, SampleRate*NumberOfChannels*BitsPerSample/8
randomAccessWriter.writeShort(Short.reverseBytes((short)(nChannels*bSamples/8))); // Block align, NumberOfChannels*BitsPerSample/8
randomAccessWriter.writeShort(Short.reverseBytes(bSamples)); // Bits per sample
randomAccessWriter.writeBytes("data");
randomAccessWriter.writeInt(0); // Data chunk size not known yet, write 0
filePath 是音訊檔案絕對路徑,注意此時的錄音還未開始,這裡的思路是在準備階段,先建立一個帶有 wave 頭部資訊的檔案,然後在錄音進行時再不斷從緩衝區取出音訊資料寫入到這個檔案中,所以這裡的 ChunkSize 一開始就設定為 0。
另外,再給一個 samsung 的實現思路,它是讀取錄製完後的音訊檔案再往檔案頭寫入 wave 的頭部資訊,本質上是一樣的,但相對好理解些。
private void rawToWave(final File rawFile, final File waveFile) throws IOException {
byte[] rawData = new byte[(int) rawFile.length()];
DataInputStream input = null;
try {
input = new DataInputStream(new FileInputStream(rawFile));
input.read(rawData);
} finally {
if (input != null) {
input.close();
}
}
DataOutputStream output = null;
try {
output = new DataOutputStream(new FileOutputStream(waveFile));
// WAVE header
// see http://ccrma.stanford.edu/courses/422/projects/WaveFormat/
writeString(output, "RIFF"); // chunk id
writeInt(output, 36 + rawData.length); // chunk size
writeString(output, "WAVE"); // format
writeString(output, "fmt "); // subchunk 1 id
writeInt(output, 16); // subchunk 1 size
writeShort(output, (short) 1); // audio format (1 = PCM)
writeShort(output, (short) 1); // number of channels
writeInt(output, SAMPLE_RATE); // sample rate
writeInt(output, SAMPLE_RATE * 2); // byte rate
writeShort(output, (short) 2); // block align
writeShort(output, (short) 16); // bits per sample
writeString(output, "data"); // subchunk 2 id
writeInt(output, rawData.length); // subchunk 2 size
// Audio data (conversion big endian -> little endian)
short[] shorts = new short[rawData.length / 2];
ByteBuffer.wrap(rawData).order(ByteOrder.LITTLE_ENDIAN).asShortBuffer().get(shorts);
ByteBuffer bytes = ByteBuffer.allocate(shorts.length * 2);
for (short s : shorts) {
bytes.putShort(s);
}
output.write(bytes.array());
} finally {
if (output != null) {
output.close();
}
}
}
3.麥克風音量獲取
3.1 基礎知識
度量聲音強度的單位,大家最熟悉的就是分貝。計算公式如下:

分子是測量值的聲壓,分母是參考值的聲壓(20微帕,人類所能聽到的最小聲壓)。
在 Android 裝置上感測器可以提供的物理量是場的幅值(amplitude),常用下列公式計算分貝值:
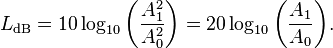
從SDK中讀取了某段音訊資料的振幅後,取最大振幅或平均振幅(可以用平方和平均,或絕對值的和平均),代入上述公式的A1。這裡的 A0 取值似情況而定,這裡不做討論。
MediaRecorder 有一個無參方法 getMaxAmplitude 即可獲得一小段時間內音源資料中的最大振幅。而 AudioRecord 沒有提供類似的方法,但是我們可以獲得具體的音源資料值來進行換算。呼叫 AudioRecord 的 read(byte[] audioData, int offsetInBytes, int sizeInBytes) 方法從緩衝區讀取到我們傳入的位元組陣列buffer 後,便可以對其進行操作,如求平方和或絕對值的平均值。這樣可以避免個別極端值的影響,使計算的結果更加穩定。求得平均值之後,如果是平方和則代入常數係數為 10 的公式中,如果是絕對值的則代入常數係數為 20 的公式中,算出分貝值。
我們先來獲取振幅,關鍵程式碼如下:
AudioRecord audioRecorder;
byte[] buffer;
int bufferSize;
// 振幅
int mAmplitude= 0;
// Number of frames written to file on each output(only in uncompressed mode)
private int framePeriod;
...
// 初始化,sampleRate 是取樣率,這裡我設定的是 44100 Hz,Google Android 文件明確表明只有以下3個引數是可以在所有裝置上保證支援的,44100 Hz,AudioFormat.CHANNEL_IN_MONO(單聲道),AudioFormat.ENCODING_PCM_16BIT(位寬)
bufferSize = AudioRecord.getMinBufferSize(sampleRate, AudioFormat.CHANNEL_IN_MONO, AudioFormat.ENCODING_PCM_16BIT);
// MediaRecorder.AudioSource.MIC,音訊採集的輸入源
audioRecorder = new AudioRecord(MediaRecorder.AudioSource.MIC, sampleRate, AudioFormat.CHANNEL_IN_MONO, AudioFormat.ENCODING_PCM_16BIT, bufferSize);
...
buffer = new byte[framePeriod*bSamples/8*nChannels];
...
// 開始錄音
audioRecorder.start();
// 讀取緩衝區音訊資料
audioRecorder.read(buffer, 0, buffer.length); // Fill buffer
try
{
randomAccessWriter.write(buffer); // Write buffer to file
payloadSize += buffer.length;
for (int i=0; i<buffer.length/2; i++)
{ // 16bit sample size
short curSample = getShort(buffer[i*2], buffer[i*2+1]);
if (curSample > mAmplitude)
{ // Check amplitude
mAmplitude = curSample;
}
}
}
catch (IOException e)
{
}
上面的 mAmplitude 就是振幅了。現在我們需要換算成分貝,直接代入公式,只需簡單的這麼一句程式碼就行了。
int mVolume = (int)(10 * Math.log10(amplitude));
上面的 mAmplitude 時刻都在變化的,除非錄音結束。所以,我們可以通過 mAmplitude 來實現諸如繪製聲音訊率圖、聲波圖等效果。