
SQL2005中的事務與鎖定(一到九整合版)
終於定下心來寫這個事務與鎖定的文章,下筆後才發現真的很難寫,交易中事務與鎖定這個話題過於複雜,甚至有些還摸不著(就是通過DMV或DMF或其它工具你可能很難看到它的蹤影),讓人有點讓人望而止步,但是既然說了要寫,似乎不繼續下去不是我的風格。在接下來的幾篇文章(其實我也不知道要幾篇)裡我就事務與鎖定這個話題寫寫,由SQL2005的併發模型引入事務,在事務的概念裡展開鎖定,本著先概念後例項的原則,和大家一起來學習,有不當之處希望大家指正。
一、併發及併發控制模型
對於這個我在<< SQL2005資料庫引擎結構>>一文有所提及,你可以通過如下連結進行訪問:SQL2005資料庫引擎結構(三)
很顯然對上述的例子我們希望一個程序在修改庫存資料時必須阻止其它程序讀或修改資料,或是正在讀的使用者程序限制其它活動的使用者程序進行讀或修改的操作,這樣一來勢必造成系統的併發效能下降,但是如果不採用這種辦法又無法保證資料正確性和一致性。那怎麼解決這個問題呢,辦法只有通過不同的併發模式來管理這些併發事件。我們下面來理解併發控制的模式、併發下可能發生的非一致資料行為,即併發副作用,並由模式及資料行為引入事務及相關的5個隔離等級等概念,進而來理解不同隔離等級下併發實現的機理,顯然我們自己也就可以回答上面這個問題了。
併發控制模式:一般併發控制模式有兩種:積極併發(又稱樂觀併發)和消極併發(又稱悲觀併發)。積極併發是SQL2005才引入的新模式,在2005以前的版本其實只有唯一的併發模式即:消極併發。那什麼是消極併發呢?消極併發就是SQLSERVER預設行為是程序以獲取鎖的方式來阻止其它程序對正在使用的資料進行修改的能力。對於資料庫來說對資料修改的操作程序肯定很多,這些程序肯定都會去影響其它程序讀取資料的能力,反之,對資料進行讀時加上鎖也一定會影響其它程序修改資料的能力,簡而言之,就是讀取與修改資料之間是衝突的、互相阻塞的。樂觀併發是SQL2005利用一個行版本控制器的新技術來處理上述的衝突。行版本控制器在當前程序讀取資料時生成舊版本的資料,使得其它請求讀的程序能看到當前程序一開始讀取時的資料狀態,並且不受當前程序或其它程序對資料進行修改的影響。簡而言之讀與修改之間是不衝突的,但是修改與修改之間還是衝突的。
對於這兩種併發模式兩個程序同時請求資料修改必然會衝突的,除此以外的差別在於一個是在衝突發生前進行控制,另一個在衝突發生了進行協調處理。這好比生活一樣,兩種方式就是兩種不同的人生,一種消極怠工一種積極向上。
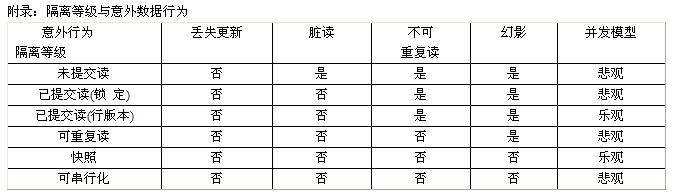
二、併發下可能發生的併發副作用:丟失更新、髒讀、不可重複讀、幻影。
為了把這些可能發生的併發副作用說清楚,我們先“佈置”一個場景:這是一個賣工藝石頭的小商店,平時在前場完成交易,客戶憑單據到後場領取石頭,AMM和BMM是營業員,她們平時掌握庫存數是通過大廳裡的一塊LED顯示牌得之,並且在各自完成一筆交易後修改LED顯示,以保證資料的實時性。在這個場景下我們來觀察可能發生的行為:
1、 丟失更新:
丟失更新估計是所有資料庫使用者都不想發生的情況,什麼是丟失更新呢?丟失更新是當2個或兩個以上的使用者程序同時讀取同樣的資料後又企圖修改原來的資料時就會發生。好在上述場景下,大廳LED顯示牌顯示當前庫存1000,這時同時有兩個客戶上門了,AMM和BMM滿面春風接待,比如AMM賣出1個,BMM呢賣出了10個,AMM處理完業務後趕緊把LED顯示數修改為1000 - 1 = 999個,幾乎同一時間BMM處理完自己的業務後習慣性的把LED顯示數修改為1000 - 10 = 990 個,這時老闆從後場過來,看著LED有點不爽,大吼一聲:現在還有多少存貨呀?,AMM說我賣了1個,BMM說我是10個,不過兩個人都傻眼了,LED顯示怎麼是990呢?原來BMM在更改時把AMM做的更改搞丟了,這就是丟失更新。顯然對老闆和營業員來說都是必須迴避不能發生的事。
2、 髒讀
很顯然,在上面的例子裡因為AMM和BMM事先因為不知道對方已經修改了櫃檯存貨,所以才造成了存貨數目顯示錯誤,出了問題我們要想辦法解決問題,英明的老闆說了,你們隨便哪個在談一筆生意時先把客戶意向購賣石頭數扣掉,如果最後客戶不要你再改回頭,兩個MM對老闆的英明決定表示等贊同,可是問題還是發生了,怎麼回事呢,還是假設櫃臺存貨1000個石頭,AMM有一筆生意正在談著,顧客意向要600塊石頭,AMM趕緊把LED顯示修改為400。這時BMM也很興奮因為她已經談成一筆700塊石頭的生意,所以呢BMM擡頭一看,好嘛,還有400塊可賣,完了BMM的生意做不成了,只好向客戶表達歉意。BMM只能讓老闆進貨,可是老闆一看LED顯示還有1000塊怎麼你的700塊生意做不成了呢?哦,因為最後AMM的600塊生意沒做成。嘿嘿,也就是BMM錯誤的讀取了AMM修改的資料,完成了一次“髒讀”操作。髒讀也就是一個使用者程序讀取了另一個使用者程序修改過但沒有正式提交的資料,這時導致了資料不一樣的情形發生了。因為A使用者程序是無法確認另一個B使用者程序在自己提交資料前是否修改過資料,這是資料庫系統預設情況下必須迴避的。
3、 不可重複讀
不可重複讀又稱不一致分析,不過,個人以為似乎不一致分析更讓人好理解一點,但是大部分地方稱不可重複讀。不可重複讀是指一個使用者程序兩次讀取資料得到不同樣的資料。比如那個英明的老闆吧,他知道要盤點,掌握庫存的變化,忙得満頭大汗,終於計出庫存數來,比如說1000吧,或是當他跑到大廳一看LED顯示牌卻只有了900,顯然這一次的檢查庫存的過程中兩次得到庫存數不一樣,原因就是AMM在老闆從後場走到前場的過程中做了一擔生意,賣出100塊。嘿嘿,老闆氣又不是不氣又不是,這AMM真可愛,做生意挺兩下呀!顯然在一個使用者程序兩次讀取資料間隔內另一個使用者程序修改了資料,這就是不可重複讀。
4、 幻影
幻影,嘿嘿,我們不是經常無視BS自己的人嗎?你無視他並不代表他不BS你吧,這個BS你的人就成了幻影,嘿嘿開個玩笑。這種情況多數在查詢帶謂詞時結果集內部分資料變化的時候發生,如果謂詞限定下在一個交易裡兩次同一查詢的結果集不同,那些不同的行或行集就是幻影。比方說英明的老闆到大廳走走,順便請大家吃飯,數數人數,BMM,。。。。一路數過去,發現有10人,呵呵,正好一桌,,通知好她們後老闆回辦會室拿人民幣,回到前場看見AMM,再一數11人,暈,剛才怎麼看到AMM ?AMM也知道了老闆請客沒數到他,很是生氣,這時AMM就成了幻影。
以上是四種併發副作用只是一個交易事務裡或事務間可能發生的異常的非一致的資料行為(記好併發副作用和不一致的資料行為術語,這在以後會經常提及),其實還是有好多的行為是我們所期望的,那麼我們期望的行為是什麼呢,下面我們在事務裡來介紹。我們可以通過隔離級別來設定一個合適級別以決定上述上種資料行為哪些是允許的。那什麼是交易事務,什麼又是隔離等級呢?
三、事務
事務是資料庫一筆交易的基本單元,存於兩種併發模型中。又分為顯式事務和隱式事務。顯式事務是顯式的開始一個事務並顯式的滾回或提交事務,除了顯式的事務還有隱式的了,隱式事務是資料庫自己根據情況完成的事務處理,如單獨的select、update、delete、select語句。
作為一個事務,它能保證資料庫的資料一致性及重做。提到事務不得不提及事務的ACID屬性:原子性、一致性、隔離性及永續性。不管是顯式還是隱式的,都必須維持這四個屬性。
原子性:一個事務是一個整體,要不全部提交,要不全部中止。意思就是要不全部成功提交到資料,要不全部回滾恢復事務開始前的狀態。比方我們做一個入庫操作,在這個事務裡,稽核入庫單和修改庫存作為一個整體,要不單據變成稽核過同時庫存增加相應的值,要不就是單據未稽核同時庫存不變。
一致性:一致性要求事務保證資料在邏輯上正確,處理的結果不是一個不確定的狀態,什麼是不確定狀態呢,比如說我們完成一個庫存減少的操作,如果沒有一個出貨單據那麼這個庫存的當前修改就是一個不確定狀態,因為你無法知道減少的東東到哪兒去了。
隔離性:這個隔離和鎖定有關,以後在說鎖的過程中會提到這些,你先記住這個就行。
永續性:持久很顯然是要求正確提交的修改必須保證長久存在,不會因為關機或掉電把這筆交易丟掉。進行中的事務發生故障那事務就完全撤銷,像沒有發生一樣,如果事務提交的確認已經反饋給應用程式發生故障,那麼這些日誌利用先寫技術,在啟動恢復階段自動完成相應的動作保證事務的永續性。(這個在前面的引擎元件有過介紹哦。)
四、隔離等級
首先來說說隔離,隔離是一個事務必須與其他事務所進行的資源或資料更改相隔開,顯然隔離等級就是相隔的程度了吧。在說隔離級別不得不提及鎖的概念,但是在本單不提及鎖,在以後聽章節裡再作說明,大家只要有個印象就行。在這兒我們必須明白兩件事:
1,隔離級別不會影響程序獲得資料修改的排它鎖,並且這個鎖會儲存到事務結束。相對於讀程序來說,隔離級別就是對讀操作的一個保護級別,保護讀操作受其它事務影響的程式。
2,較低的隔離級別可以增強許多使用者同時訪問資料的能力,但也增加了使用者可能遇到的併發副作用(例如髒讀或丟失更新)的數量。相反,較高的隔離級別減少了使用者可能遇到的併發副作用,卻需要太多的系統資源及一個事務阻塞其他事務的可能性。
應平衡應用程式的完整性要求與相應隔離級別的系統開銷,在此基礎上選擇相應的隔離級別。最高隔離級別(可序列化)保證事務在每次重複讀取操作時都能準確檢索到相同的資料,但需要通過執行某種級別的鎖定來完成此操作,而鎖定可能會影響其他使用者程序。最低隔離級別(未提交讀)可以檢索其他事務已經修改但未提交的資料。在未提交讀中,所有併發副作用都可能發生,但因為沒有讀鎖定或修改阻塞讀取,所以開銷最少。
不同的隔離級別決定我們有哪些資料副作用可以發生,而併發模型決定不同隔離等級下如何來限制這些資料行為或如何協調這資料行為。好,那我們來關注一下不同隔離等級下如何限制這些行為的發生。
未提交讀(uncommitted Read):字面理解一下,修改了的未提交資料可以讀取。準確點:一個使用者程序可以讀取另一個使用者程序修改卻未提交的資料。SQL SERVER對這個等級下的讀操作不需要獲得任何鎖就可以讀取資料,因為不需要鎖所以不會和其它任何程序互相阻塞,自然而然能讀取其它程序修改了的卻未提交資料。顯然這不是我們理想的一種模式,但是它卻有了高併發性,因為讀操作沒有鎖不會影響其它程序的讀或寫操作。在這種級別下,除了丟失更新(上一講中的資料可能發生的行為)外,其它行為都有可能發生,冒著資料不一致的風險來避免修改的程序阻塞讀取的程序,事務的一致性肯定是得不到保障,顯然這是消極併發模式下的迴避阻塞頻繁的一種解決方案。未提交讀那肯定是不適合於股票、金融系統的,但是在一些趨勢分析的系統裡,要求的只是一種走向,準確性可以不是那麼嚴格時,這個級別因併發效能超強成為首選。
已提交讀(Read Committed):它和未提交讀相反,已提交讀級別保證一個程序不可能讀到另一個程序修改但未提交的資料。這個級別是引擎預設的級別,也是2005樂觀併發模式下支援的級別,也就是說已提交讀可是樂觀的也可以是悲觀的,那究竟當前庫是屬於哪個併發模型下的已提交讀呢,這取決於一個READ_COMMITED_SNAPSHOT資料庫配置項,並且預設是悲觀併發控制的。這個配置項決定已提交讀級別下事務使用鎖定還是行版本控制,並很顯然行版本控制是樂觀併發模式,鎖定是悲觀併發模式。我們來點角本看看:
--設定已提交讀隔離使用行版本控制
ALTER DATABASE testcsdn SET READ_COMMITTED_SNAPSHOT ON
GO
--檢視當前已提交讀隔離併發模型
select name,database_id,is_read_committed_snapshot_on from sys.databases
/*
name database_id is_read_committed_snapshot_on
-------------------- ----------- -----------------------------
master 1 0
tempdb 2 0
model 3 0
msdb 4 0
ReportServer$SQL2005 5 0
ReportServer$SQL2005TempDB 6 0
TestCsdn 7 1 --current
(7 行受影響)
*/
--設定已提交讀隔離使用鎖定
ALTER DATABASE testcsdn SET READ_COMMITTED_SNAPSHOT OFF
GO
--檢視已提交讀隔離併發模型
select name,database_id,is_read_committed_snapshot_on from sys.databases
/*
name database_id is_read_committed_snapshot_on
-------------------- ----------- -----------------------------
master 1 0
tempdb 2 0
model 3 0
msdb 4 0
ReportServer$SQL2005 5 0
ReportServer$SQL2005TempDB 6 0
TestCsdn 7 0 --curret
(7 行受影響)
*/
已提交讀在邏輯上保證了不會讀到不實際存在的資料。悲觀併發下的已提交讀,當程序要修改資料時會在資料行上申請排它鎖,其它程序(無論是讀還是寫)必須等到排它鎖釋放才可以使用這些資料。如果程序僅是讀取資料時會使用共享鎖,其它程序雖然可以讀取資料但是無法更新資料,必須等到共離鎖釋放(共享鎖在資料處理完即釋放,比如行共享鎖在當前資料行資料處理完就自動釋放,不會在整個事務內保留髮。)。樂觀併發的已提交讀,也確保不會讀到未提交的資料,不是通過鎖定的方式來實現,而是通過行版本控制器生成行的提前交的資料版本,被修改的資料雖然仍然鎖定,但是其它程序可以可以讀取更新前版本資料。
可重複讀(Repeatable Read):這也是一個悲觀併發的級別。可重複讀比已提交讀要求更嚴格,在已提交讀的基礎上增加了一個限制:獲取的共享鎖保留到事務結束。在這個限制下,程序在一個事務裡兩交次讀取的資料一致,也就是不會讀取到其它程序修改了資料。在這兒我們提到共享鎖會保留到事務結束,那得申明一下無論哪種級別及併發模型,排它鎖是一定要保留到事務結束的。在可重複讀級別共享鎖同樣也會保留到事務結束。那麼這種對資料安全的保證是通過增加共享保留的開銷為代價的,也就是隻要開始一個事務,其它使用者程序是不可能修改資料的,顯而易見的系統的併發性和效能必然下降。這似乎是我們想像中的一種級別,雖然這個級別暫時無法迴避幻影讀,而且我們也默許併發及效能下降,那只有對程式設計師對事務的控制有嚴格的要求:事務要短並儘量不要人為因素的干擾,減少潛在的鎖競爭。
快照(SnapShot):樂觀併發級別。這是2005新增加的一個隔離級別。快照級別與使用樂觀併發的已提交讀差不多,差別在於行版控制器裡的資料版本有多早,這個在以後講鎖時再說。這個級別保證了一個事務讀取的資料是事務開始時就在資料庫邏輯上確認並符合一致性的資料。讀操作不會要求共享鎖定,如果要求的資料已經排它,就會通過行版本控制器讀取最近的符合一致性的資料。
可序列化:是目前最嚴謹、最健壯的一個級別,屬於悲觀併發。它防止幻影的發生,迴避了以前所有意外行為的發生。可序列化意味著系統按程序進入佇列的順序依次、序列化的執行的結果與事務同時執行得到一致的結果。這個最健壯的級別顯然共享鎖也是隨事務開始隨事務結束,並通過鎖定部分不存在的資料(即索引鍵範圍鎖定)來回避幻影的發生。
在前面的兩篇裡我從純理論上把事務相關的知識作了一個梳理,有人看了一定覺得無味了吧,好這一篇我們加入一點T-SQL語句把前面所說有東東關聯起來,我們人為產生鎖定來理解不同的意外資料行為在不同隔離等級下的表現,順便再重溫一下意外資料行及隔離等級,讓大家對交易事務有一個直觀的認識。
在進行例項前不得不先介紹一點鎖的知識,注意這兒只是簡單的說一下,不作深入討論。我們根據使用者訪問資源的行為先歸納出幾種鎖,這幾種鎖在下面的例項裡會出現,它們為:共享鎖定、排它鎖定、更新鎖定及用意向這個限定詞限定的三種鎖(意向共享、意向排它、意向更新),噹噹然還有其它的模式,我們在下一篇再說。意向鎖的存在是解決死鎖的發生,保證程序在申請鎖定前確定當前資料是否存在不相容性的鎖定。
先對上面提到的鎖作一個簡單的描述,更詳細的下面再說。
共享鎖定發生在查詢記錄時,直觀就是我們select啦,但是並不是只有select才有共享鎖定。一個查詢記錄的語句必須在沒有與共享鎖定互斥鎖定存在或等待互斥鎖定結束後,才能設定共享鎖定並提取資料(互斥不互斥就是鎖的相容性,這在以後再說明)。
排它鎖定發生在對資料增加、刪除、修改時,事務開始以後語句申請並設定排它鎖定(前提是沒有其它互斥鎖定存在),以明確告知其它程序對當前資料不可以查詢或修改,等待事務結束後其它程序才可以查詢或修改。
更新鎖定是一個介於共享與排它之間的中繼鎖定,比如我們帶where條件的update語句,在查詢要更新的記錄時是設定共享鎖定,當要更新資料時這時鎖定必須由共享鎖定升級成更新鎖定繼而升級為排它鎖定,當排它鎖定設定成功才可以進行資料修改操作。顯然也是要要求在鎖升級的過程中沒有互斥鎖定的存在。簡單的理解更新鎖定是一箇中繼閘一樣,把升級成排它鎖定程序“序列化”,以解決死鎖。最後重點說明一下,資料更新階段是要對資料排它鎖定不是更新鎖定,不要被字面意思訓導哦。
最後說一下在上述鎖定模式下的互斥,共享鎖定只與排它鎖定互斥,更新鎖定只與共享鎖定不互斥。
在進行具體例項前我們一定要有一個工具來對我們例項過程進行監控,好,下面我寫了一個過程,在需要時直接呼叫就行,過程如下:
Create Proc sp_us_lockinfo
---------------------------------------------------------------------
-- Author : HappyFlyStone
-- Date : 2009-10-03 15:30:00
-- 申明 :請保留作者資訊,轉載註明出處
---------------------------------------------------------------------
AS
BEGIN
SELECT
DB_NAME(t1.resource_database_id) AS [資料庫名],
t1.resource_type AS [資源型別],
-- t1.request_type AS [請求型別],
t1.request_status AS [請求狀態],
-- t1.resource_description AS [資源說明],
CASE t1.request_owner_type WHEN 'TRANSACTION' THEN '事務所有'
WHEN 'CURSOR' THEN '遊標所有'
WHEN 'SESSION' THEN '使用者會話所有'
WHEN 'SHARED_TRANSACTION_WORKSPACE' THEN '事務工作區的共享所有'
WHEN 'EXCLUSIVE_TRANSACTION_WORKSPACE' THEN '事務工作區的獨佔所有'
ELSE ''
END AS [擁有請求的實體型別],
CASE WHEN T1.resource_type = 'OBJECT'
THEN OBJECT_NAME(T1.resource_ASsociated_entity_id)
ELSE T1.resource_type+':'+ISNULL(LTRIM(T1.resource_ASsociated_entity_id),'')
END AS [鎖定的物件],
t4.[name] AS [索引],
t1.request_mode AS [鎖定型別],
t1.request_session_id AS [當前spid],
t2.blocking_session_id AS [鎖定spid],
-- t3.snapshot_isolation_state AS [快照隔離狀態],
t3.snapshot_isolation_state_desc AS [快照隔離狀態描述],
t3.is_read_committed_snapshot_on AS [已提交讀快照隔離]
FROM
sys.dm_tran_locks AS t1
left join
sys.dm_os_waiting_tasks AS t2
ON
t1.lock_owner_address = t2.resource_address
left join
sys.databases AS t3
ON t1.resource_database_id = t3.database_id
left join
(
SELECT rsc_text,rsc_indid,rsc_objid,b.[name]
FROM
sys.syslockinfo a
JOIN
sys.indexes b
ON a.rsc_indid = b.index_id and b.object_id = a.rsc_objid) t4
ON t1.resource_description = t4.rsc_text
END
GO
/*
呼叫示例:exec sp_us_lockinfo
*/
exec sp_us_lockinfo
/*

*/
drop proc sp_us_lockinfo
最後介紹一個隔離等級設定命令:
SET TRANSACTION ISOLATION LEVEL {READ UNCOMMITTED
| READ COMMITTED
| REPEATABLE READ
| SNAPSHOT
| SERIALIZABLE}[;]
好,下面開始例項“快樂”之旅了。
五、隔離等級例項
測試資料準備:
CREATE DATABASE testcsdn;
GO
CREATE TABLE TA(TCID INT PRIMARY KEY,TCNAME VARCHAR(20))
INSERT TA SELECT 1,'AA'
INSERT TA SELECT 2,'AA'
INSERT TA SELECT 3,'AA'
INSERT TA SELECT 4,'BB'
INSERT TA SELECT 5,'CC'
INSERT TA SELECT 6,'DD'
INSERT TA SELECT 7,'DD'
GO
約定:以下提及的查詢N,都是開啟一個新連線執行查詢
1、 未提交讀(uncommitted Read)
概念回顧:未提交讀是最低等級的隔離,允許其它程序讀取本程序未提交的資料行,也就是讀取資料時不設定共享鎖定直接讀取,忽略已經存在的互斥鎖定。很顯然未提交讀這種隔離級別不會造成丟失更新,但是其它意外行為還是可以發生的。它和select 加鎖定提示NOLOCK效果相當。
測試例項:
查詢一:
SELECT * FROM TA WHERE TCID = 1
BEGIN TRAN
UPDATE TA
SET TCNAME = 'TA'
WHERE TCID = 1
--COMMIT TRAN --Don't commit
SELECT * FROM TA WHERE TCID = 1
SELECT @@SPID
/*
tcid Tcname
----------- --------------------
1 AA
(1 行受影響)
(1 行受影響)
tcid Tcname
----------- --------------------
1 TA
(1 行受影響)
SPID
------
54
(1 行受影響)
*/
查詢二:
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
SELECT * FROM TA WHERE TCID = 1
/*
tcid Tcname
----------- --------------------
1 TA
(1 行受影響)
*/
--顯然未提交讀模式我們讀到SPID=54未提交的資料。
查詢三:
SELECT * FROM TA WHERE TCID = 1
--查詢一直進行中…… 無結果
--因為預設下已提交讀級別,所以修改資料設定了排它鎖定必須等到SPID=54的事務結束
查詢四:
--檢視當前的鎖定資訊
exec sp_us_lockinfo
/*
*/
這個時候如果我們回頭到查詢一里執行commit tran ,你會發現查詢三會得到結果,並且是查詢一修改後的結果,如果你改用rollback ,那麼結果就是原來的值不變,這個你們自己再測試。
1、 已提交讀(Read Committed)
概念回顧:已提交讀是SQL SERVER的預設隔離級別,悲觀模型下是用鎖定,樂觀模型下使用行版本控制器。這個設定可以通過SET READ_CIMMITTED_SNAPSHOT來修改。在悲觀模型下對於讀取來說設定共享鎖定僅阻止排它鎖定,並在資料讀取結束自動釋放,其它程序方可進行修改操作。也就是說讀不會阻止其它程序設定共享及更新鎖定,僅阻止排它鎖定。在悲觀模型下對於修改資料來說設定排鎖定阻止所有鎖定請示,必須等到排它鎖定釋放。這個級別的隔離解決了髒讀的意外行為。
A、 READ_COMMITTED_SNAPSHOT為OFF的情況(預設)
I、讀資料測試
查詢一:
BEGIN TRAN
--用鎖定提示模擬共享鎖定,並強制共享鎖定持續到事務結束
SELECT * FROM TA with(holdlock) WHERE TCID = 1
--COMMIT TRAN --Don't commit
SELECT @@SPID
/*
tcid Tcname
----------- --------------------
1 CA
(1 行受影響)
------
54
(1 行受影響)
*/
查詢二:悲觀模型下已提交讀級別
SET TRANSACTION ISOLATION LEVEL READ COMMITTED
UPDATE TA
SET TCNAME = 'TA'
WHERE TCID = 1
--查詢一直沒有結果,顯然我們驗證了共享鎖定阻止了排它鎖定。
查詢三:
exec sp_us_lockinfo
--結果大家自己執行看結果。
II、修改資料測試
查詢一:
SELECT * FROM TA WHERE TCID = 1
BEGIN TRAN
UPDATE TA
SET TCNAME = 'READ COMMITTED LOCK'
WHERE TCID = 1
--COMMIT TRAN --Don't commit
SELECT @@SPID
/*
tcid Tcname
----------- --------------------
1 TA
(1 行受影響)
------
54
(1 行受影響)
*/
查詢二:
SET TRANSACTION ISOLATION LEVEL READ COMMITTED
SELECT * FROM TA WHERE TCID = 1
/*
--查詢一直進行中……被鎖定無結果
--修改資料設定了排它鎖定必須等到SPID=54的事務結束
*/
查詢三:
exec sp_us_lockinfo
/*
*/
A、 READ_COMMITTED_SNAPSHOT為ON的情況
先修改當前當前庫的READ_COMMITTED_SNAPSHOT為ON
ALTER DATABASE TESTCSDN
SET READ_COMMITTED_SNAPSHOT ON
GO
查詢一:
SELECT * FROM TA WHERE TCID = 1
BEGIN TRAN
UPDATE TA
SET TCNAME = 'READ COMMITTED SNAP'
WHERE TCID = 1
--COMMIT TRAN --Don't commit
SELECT @@SPID
/*
TCID TCNAME
----------- --------------------
1 AA
(1 行受影響)
(1 行受影響)
------
56
(1 行受影響)
*/
查詢二:因為啟用行版本控制器來鎖定資料,保證其它程序讀取到雖然被排它鎖定但在事務開始前已經提交的保證一致性的資料。
SET TRANSACTION ISOLATION LEVEL READ COMMITTED
SELECT * FROM TA WHERE TCID = 1
/*
TCID TCNAME
----------- --------------------
1 AA
(1 行受影響)
*/
查詢三:
exec sp_us_lockinfo
/*

*/
3、可重複讀(Repeatable Read)
概念回顧:可重複讀等級比已提交讀多了一個約定:所有的共享鎖定持續到事務結束,不是在讀取完資料就釋放。資料被設定了共享鎖定後其它程序只能進行查詢與增加不能更改,顯然這個級別的隔離對程式有了更高的要求,因為可能因長時間的共享鎖定影響系統的併發效能,增加死鎖發生的機率。很顯然是解決了不可重複讀的意外行為。
資料測試:
查詢一:
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ
BEGIN TRAN
SELECT * FROM TA WHERE TCID = 1 --可重複查詢,並且讀不到未提交的資料
--COMMIT TRAN --Don't commit
SELECT @@SPID
/*
tcid Tcname
----------- --------------------
1 READ COMMITTED LOCK
(1 行受影響)
------
52
(1 行受影響)
*/
查詢二:
INSERT TA SELECT 9,'FF'
/*
(1 行受影響)
*/
SELECT * FROM TA-- WITH(UPDLOCK)
WHERE TCID = 1
/*
tcid Tcname
----------- --------------------
1 READ COMMITTED LOCK
(1 行受影響)
*/
UPDATE TA
SET TCNAME = 'READ COMMITTED REP'
WHERE TCID = 1
/*
--查詢一直進行中……被鎖定無結果
--修改資料設定了排它鎖定必須等到SPID=52的事務結束
*/
查詢三:

很顯然查詢三中的S,Is(共享及意向共享)鎖定一直沒消失,因為查詢一的事務沒有結束,在查詢二里可以發現插入與讀取(包括在查詢一里再次select)是不影響的,並且讀取的是未修改前的資料。
4、快照(SnapShot)
概念回顧:這是SQL SERVER2005的新功能,啟用快照後所有的讀操作不再受其它鎖定影響,讀取的資料是通過行版本管制器讀取事務開始前邏輯確定並符合一致性的資料行版本。 這個級別隔離與已提交讀的行版管理器的差別僅是行版本管理器裡歷史版本資料多久。
測試資料:
查詢一:
ALTER DATABASE TESTCSDN
SET ALLOW_SNAPSHOT_ISOLATION ON
GO
SELECT * FROM TA WHERE TCID = 1 --OLD資料
BEGIN TRAN
UPDATE TA
SET TCNAME = 'SNAPSHOT'
WHERE TCID = 1
--COMMIT TRAN --Don't commit
SELECT @@SPID
/*
tcid Tcname
----------- --------------------
1 READ COMMITTED REP
(1 行受影響)
(1 行受影響)
------
52
(1 行受影響)
*/
查詢二:
SET TRANSACTION ISOLATION LEVEL SNAPSHOT
SELECT * FROM TA WHERE TCID = 1
/*
tcid Tcname
----------- --------------------
1 READ COMMITTED REP
(1 行受影響)
*/
查詢三:
exec sp_us_lockinfo

5、可序列化:
概念回顧:這是交易裡最健壯最嚴謹最高級別的隔離。通過索引鍵範圍完全隔離其它交易的干擾,此隔離和select與鎖定提示HOLDLOCK效果一樣。這個級別基本解決所有的意外行為,顯而易見的是併發效能下降或系統資源的損耗上升。
測試資料:
查詢一:
DROP TABLE TB
GO
CREATE TABLE TB (ID INT Primary Key, COL VARCHAR(10))
GO
INSERT INTO TB SELECT 1,'A'
GO
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
BEGIN TRAN
SELECT * FROM TB WHERE ID BETWEEN 1 AND 5--OLD資料
--COMMIT TRAN --Don't commit
SELECT @@SPID
/*
ID COL
----------- ----------
1 A
(1 行受影響)
------
52
(1 行受影響)
*/
查詢二:
SELECT * FROM TB WHERE ID = 1
/*
ID COL
----------- ----------
1 A
(1 行受影響)
*/
INSERT TB SELECT 2,'EE'
/*
--查詢一直進行中……被鎖定無結果
--修改資料設定了排它鎖定必須等到SPID=52的事務結束
*/
UPDATE TB
SET COL = 'SERIALIZABLE'
WHERE ID = 1
/*
--查詢一直進行中……被鎖定無結果
--修改資料設定了排它鎖定必須等到SPID=52的事務結束
*/
查詢三:
exec sp_us_lockinfo

可以明顯的發現出現大量的索引鍵範圍(RangeS-S……),確保在當前事務未結束之前另外的使用者程序無法在索引鍵範圍內插入資料,防此幼影意外行為的發生。可序列化後,除了資料能查詢外,不可以修改、增加、刪除索引鍵範圍內的任意資料行,必須等到索引上的鎖定釋放。
結論:通過以的一些測試,我們知道通過隔離等級我們可以控制併發時意外行為,在實際操作的過程中我們可以用啟用事務來控制鎖的粒度、影響範圍,以達到控制併發機制下資料的邏輯正確及資料一致性。最後我們發現通過鎖定提示(LOCK HINTS)也可以改變表級鎖定型別、鎖定週期,達到和設定隔離等級類似的功能。
好,到目前為止我們把事務相關的東西介紹得差不多了,並且在提前介紹了部分的鎖定,在下面的文章裡我們重點對鎖進行介紹。
在生產交易過程中多個使用者同時訪問資料是不可以避免的,通過不同的隔離等級對資源與資料進行各種型別的鎖定保護並在適當時候釋放保證交易的正確執行,使得交易完整並保證資料的一致性。不管是鎖定還是行版本控制器都決定著商業邏輯的流暢、事務的完整、資料的一致。所以我們要根據實際情況進行部署,在併發性效能與資源管理成本之間找到平衡點,怎樣才能找到這個平衡點呢,那我們就得對SQLSERVER如何管理資源與鎖有一個瞭解,SQLSERVER不但管理鎖定,還要管理鎖定模式之間的相容性或升級鎖定及解決死鎖問題。通過SQL SERVER強大的、細緻的鎖定機制,使得併發效能得到最大程度的發揮,但是使用盡可能少的系統資源也是我們最希望的。
SQLSERVER本身有兩種鎖定體系:一種是對共享資料的鎖定,這種鎖定就是我們大部時間討論的鎖定;一種是對內部資料結構及處理索引,這是一種稱為閂鎖的輕量級鎖,比第一種鎖定少耗資源,在sys.dm_tran_locks中是看不到這種鎖的資訊。我們在資料分頁上放置物理記錄或壓縮、折分、轉移分頁資料時,這種鎖就會發生了。我們在前面一直在說資料的邏輯一致性,那這種邏輯上的一致性就是通過鎖定來控制的,而我們新提到的閂是保證物理的一致性(這種閂是系統內部使用所以我們不重點討論了)。
併發訪問資料時,SQL Server 2005使用下列機制確保事務完整並維護資料的一致性:
l 鎖定
每個事務對所依賴的資源(如行、頁或表)請求不同型別的鎖。鎖可以阻止其他事務以某種可能會導致事務請求鎖出錯的方式修改資源。當事務不再依賴鎖定的資源時,它將釋放鎖。
l 行版本控制
當啟用了基於行版本控制的隔離級別時,資料庫引擎 將維護修改的每一行的版本。應用程式可以指定事務使用行版本檢視事務或查詢開始時存在的資料,而不是使用鎖保護所有讀取。通過使用行版本控制,讀取操作阻止其他事務的可能性將大大降低。
鎖定和行版本控制可以防止使用者讀取未提交的資料,還可以防止多個使用者嘗試同時更改同一資料。如果不進行鎖定或行版本控制,對資料執行的查詢可能會返回資料庫中尚未提交的資料,從而產生意外的結果。
最後說一下鎖的粒度與併發效能是矛盾的,但是對管理鎖定的成本卻是有利的,粒度越大併發效能下降,粒度越小管理鎖定成本越大。用圖示例一下:

六、鎖定
1、鎖粒度和可鎖定資源
SQL Server2005 具有多粒度鎖定,允許一個事務鎖定不同型別的資源。為了儘量減少鎖定的開銷,資料庫引擎自動將資源鎖定在適合任務的級別。鎖定在較小的粒度(例如行)可以提高併發度,但開銷較高,因為如果鎖定了許多行,則需要持有更多的鎖。鎖定在較大的粒度(例如表)會降低了併發度,因為鎖定整個表限制了其他事務對錶中任意部分的訪問,但其開銷較低,因為需要維護的鎖較少。
SQL SERVER可以鎖定表、分頁、行級、索引鍵或範圍。在這我提醒大家一下,對於聚集索引的表,因為資料行就是索引的葉級,所以鎖定是鍵鎖完成而不是行鎖。
資料庫引擎通常必須獲取多粒度級別上的鎖才能完整地保護資源。這組多粒度級別上的鎖稱為鎖層次結構。例如,為了完整地保護對索引的讀取,資料庫引擎例項可能必須獲取行上的共享鎖以及頁和表上的意向共享鎖。
下表列出了資料庫引擎可以鎖定的資源:
查詢一:
SELECT *
FROM MASTER..SPT_VALUES WHERE TYPE = 'LR'
/*
name number type low high status
--------------- ----------- ---- ------- --------- -----------
LOCK RESOURCES 0 LR NULL NULL 0
NUL 1 LR NULL NULL 0
DB 2 LR NULL NULL 0
FIL 3 LR NULL NULL 0
TAB 5 LR NULL NULL 0
PAG 6 LR NULL NULL 0
KEY 7 LR NULL NULL 0
EXT 8 LR NULL NULL 0
RID 9 LR NULL NULL 0
APP 10 LR NULL NULL 0
MD 11 LR NULL NULL 0
HBT 12 LR NULL NULL 0
AU 13 LR NULL NULL 0
(13 行受影響)
*/
備註:
RID RID 鎖定堆中行的行識別符號
KEY KEY 序列化事務中的鍵範圍行鎖
PAG PAGE 資料或索引頁面,8K為單位
EXT EXTENT 資料或索引頁面,連續的8*page
HBT HOBT 堆或B樹,保護索引或堆表頁堆的鎖
TAB TABLE 整個表,包括資料及索引
FIL FILE 資料庫檔案
APP APPLICATION 應用程式資源
MD METADATA 元資料
AU ALLOCATION_UNIT 分配單元
DB DATABASE 資料庫
注:SPT_VALUES這個大家不陌生吧,好多人用它生成一個連續的ID號的啦,當時也有人問這個表的用途,現在發現它的作用了吧。下面我們還會使用到。
2、鎖定模式
我們在前提面前到的共享鎖定、更新鎖定、排它鎖定,這是為了配合前面的事務而提及的,那麼SQL SERVER2005一共有多少鎖定模式呢?我們通過一個簡單的查詢來列表:
查詢:
SELECT *
FROM MASTER..SPT_VALUES WHERE [TYPE] = 'L'
/*
NAME NUMBER TYPE LOW HIGH STATUS
---------------- ----------- ---- ----------- ----------- -----------
LOCK TYPES 0 L NULL NULL 0
NULL 1 L NULL NULL 0
SCH-S 2 L NULL NULL 0
SCH-M 3 L NULL NULL 0
S 4 L NULL NULL 0
U 5 L NULL NULL 0
X 6 L NULL NULL 0
IS 7 L NULL NULL 0
IU 8 L NULL NULL 0
IX 9 L NULL NULL 0
SIU 10 L NULL NULL 0
SIX 11 L NULL NULL 0
UIX 12 L NULL NULL 0
BU 13 L NULL NULL 0
RANGES-S 14 L NULL NULL 0
RANGES-U 15 L NULL NULL 0
RANGEIN-NULL 16 L NULL NULL 0
RANGEIN-S 17 L NULL NULL 0
RANGEIN-U 18 L NULL NULL 0
RANGEIN-X 19 L NULL NULL 0
RANGEX-S 20 L NULL NULL 0
RANGEX-U 21 L NULL NULL 0
RANGEX-X 22 L NULL NULL 0
(23 行受影響)
*/
我們可以看到一共有22種鎖定模式 ,我簡單的對上述[NAME]進行簡單的列舉:
l S --- 共享鎖定(Shared)
l U --- 更新鎖定(Update)
l X --- 排它鎖定(Exclusive)
l I --- 意向鎖定(Intent)
l Sch --- 架構鎖定(Schema)
l BU --- 大量更新(Bulk Update)
l RANGE --- 鍵範圍(Key-Range)
l 其它是在上述鎖定的變種組合,比如IS --- 意向共享鎖定
其實對這些鎖定模式沒什麼介紹,大家可以參考聯機幫助:訪問和更改資料庫資料 -> 鎖定和行版本控制 -> 資料庫引擎中的鎖定。其實這些鎖定模式在前一篇基本都有出現,大家可以在看下面的定義再回頭看看前一篇的相關內容。下面我就簡單的說說:
共享鎖(S 鎖)
當我們查詢(select)資料時SQL SERVER2005會嘗試在資料上申請共享鎖定,但是前提是在當前的資料上不存在與共享鎖定互斥的鎖定。資源上存在共享鎖時,任何其他事務都不能修改資料但是可以讀取資料。讀取操作一完成,就立即釋放資源上的共享鎖,除非將事務隔離級別設定為可重複讀或更高級別,或者在事務持續時間內用鎖定提示(HOLDLOCK)保留共享鎖。
更新鎖(U 鎖)
更新新是一種介於共享鎖與排它鎖之間的鎖定,是一種中繼鎖定,像一箇中間閘門,把從共享鎖定轉為排它鎖的請求進行排隊,有效的防止常見的死鎖。在可重複讀或可序列化事務中,一個事務讀取資料 [獲取資源(頁或行)的共享鎖(S 鎖)],然後修改資料 [此操作要求鎖轉換為排他鎖(X 鎖)]。如果兩個事務獲得了資源上的共享模式鎖,然後試圖同時更新資料,則一個事務嘗試將鎖轉換為排他鎖(X 鎖)。共享模式到排他鎖的轉換必須等待一段時間,因為一個事務的排他鎖與其他事務的共享模式鎖不相容;發生鎖等待。第二個事務試圖獲取排他鎖(X 鎖)以進行更新。由於兩個事務都要轉換為排他鎖(X 鎖),並且每個事務都等待另一個事務釋放共享模式鎖,因此發生死鎖。而有了更新鎖則可避免這種潛在的死鎖問題,在查詢到要更新的資料後SQL SERVER首先給資料設定更新鎖定,因為共享鎖定與更新鎖定不互斥,在其它事務設定共享鎖定時依然可以設定更新鎖定,繼而因更新鎖定斥的,如果其它要修改資料的事務必須等待。如果事務修改資源,則更新鎖轉換為排他鎖(X 鎖)。
排他鎖(X 鎖)
排他鎖可以防止併發事務對資源進行訪問。使用排他鎖(X 鎖)時,任何其他事務都無法修改資料;僅在使用 NOLOCK 提示或未提交讀隔離級別時才會進行讀取操作。
資料修改語句(如 INSERT、UPDATE 和 DELETE)合併了修改和讀取操作。語句在執行所需的修改操作之前首先執行讀取操作以獲取資料。因此,資料修改語句通常請求共享鎖和排他鎖。例如,UPDATE 語句可能根據與一個表的聯接修改另一個表中的行。在此情況下,除了請求更新行上的排他鎖之外,UPDATE 語句還將請求在聯接表中讀取的行上的共享鎖。
排他鎖定隨事務結束而釋放。
意向鎖(I鎖)
資料庫引擎使用意向鎖來保護共享鎖(S 鎖)或排他鎖(X 鎖)放置在鎖層次結構的底層資源上。意向鎖之所以命名為意向鎖,是因為在較低級別鎖前可獲取它們,因此會通知意向將鎖放置在較低級別上。
意向鎖有兩種用途:
l 防止其他事務以會使較低級別的鎖無效的方式修改較高級別資源。
l 提高資料庫引擎 在較高的粒度級別檢測鎖衝突的效率。
例如,在該表的頁或行上請求共享鎖(S 鎖)之前,在表級請求共享意向鎖。在表級設定意向鎖可防止另一個事務隨後在包含那一頁的表上獲取排他鎖(X 鎖)。意向鎖可以提高效能,因為資料庫引擎僅在表級檢查意向鎖來確定事務是否可以安全地獲取該表上的鎖。而不需要檢查表中的每行或每頁上的鎖以確定事務是否可以鎖定整個表。
意向鎖包括意向共享 (IS)、意向排他 (IX)、意向排他共享 (SIX)、意向更新 (IU)、共享意向更新 (SIU ,S和 IU 鎖的組合)、更新意向排他 (UIX,U 鎖和 IX 鎖的組合)。
在這兒的SIX,SIU,UIX我們可以理解成一種轉換鎖定,並不是由SQLSERVER直接申請的,是由一種模式向另一種模式轉換時中間狀態。比如說SIX表示一種正持有共享鎖定的程序正在企圖申請意向排它鎖定,或是這樣理解一個持有共享鎖定的資源中有部分分頁或行被另一個程序的排它鎖定鎖定了。其它同理可以理解。
為了更好的說明一點, 大家先看一個圖:
這是我在TA表上加Where條件的一個更新動作,然後通過我以前寫的一個工具:sp_us_lockinfo檢視鎖的資訊,其實我的update只是影響一個行記錄,但是我們發現有三個鎖存在,只要當前事務不結束,其它事物對這個表申請不管是頁面的鎖定還是表級的鎖定一定會與現在的表或頁意向鎖衝突,進而發生阻塞,而且我們在前面的隔離等級的例項中也有例子,你會發現它的請求狀態是WAIT 而不是GRANT。
架構鎖(架構修改鎖 Sch-M 鎖、架構穩定性鎖Sch-S 鎖)
執行表的資料定義語言 (DDL) 操作(例如新增列或刪除表)時使用架構修改鎖。在架構修改鎖起作用的期間,會防止對錶的併發訪問。這意味著在釋放架構修改鎖(Sch-M 鎖)之前,該鎖之外的所有操作都將被阻止。
當編譯查詢時,使用架構穩定性鎖。架構穩定性鎖不阻塞任何事務鎖,包括排他鎖(X 鎖)。因此在編譯查詢時,其他事務 [包括在表上有排他鎖(X 鎖)的事務] 都能繼續執行。但不能在表上執行 DDL 操作。
大容量更新鎖(BU 鎖)
當將資料大容量複製到表,且指定了 TABLOCK 提示或者使用 sp_tableoption 設定了 table lock on bulk 表選項時,將使用大容量更新鎖。大容量更新鎖允許多個執行緒將資料併發地大容量載入到同一表,同時防止其他不進行大容量載入資料的程序訪問該表。
鍵鎖、鍵範圍鎖(Key-range鎖)
在SQL SERVER2005有兩種型別鍵鎖:鍵鎖及鍵範圍鎖。採用哪種型別的鍵鎖取決於隔離級別。對於已提交讀、可重複讀、快照隔離時SQLSERVER鎖定實際的索引鍵(如果是堆表除了實際非聚集索引上的鍵鎖同時有實際行上的行鎖),如果是可序列化隔離時就可以看到鍵範圍鎖。在早期的版本中我們實驗可以看到SQLSERVER是通過分頁鎖定或表鎖來實現的,也許鍵範圍鎖不是最完美的,但是我們應該看到它比分頁或表鎖定所鎖定的範圍要小得多,在保證不出現幻影的前提下鍵範圍鎖比以前版本採用鎖定提供了更高的併發效能。
鍵範圍鎖放置在索引上,指定開始鍵值和結束鍵值。此鎖將阻止任何要插入、更新或刪除任何帶有該範圍內的鍵值的行的嘗試,因為這些操作會首先獲取索引上的鎖。鍵範圍鎖包括按範圍-行格式指定的範圍元件和行元件,是一種組合鎖模式(Range範圍-索引項的鎖模式)。比如:RangeI-N ,RangeI 表示插入範圍,N(NULL) 表示空資源,它表示在索引中插入新鍵之前測試範圍。
在SELECT * FROM MASTER..SPT_VALUES WHERE [TYPE] = 'L'查詢結果的最後9條個就是鍵範圍鎖。這種鎖定因持續時間比較短一般在sys.dm_tran_locks中很難見到。比如RangeI_N這個鎖定,是在鍵範圍內插入記錄時獲得的,在鍵範圍內找到位置立即升級為X鎖定,這個過程很短,我們在sys.dm_tran_locks中很難找到它的蹤影,不過我們是可以模擬出來的,下面我們來模擬一下:
查詢一:
DROP TABLE TB
GO
CREATE TABLE TB (ID INT primary key, COL VARCHAR(16))
GO
INSERT INTO TB SELECT 1,'A'
GO
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
BEGIN TRAN
SELECT * FROM TB WHERE id BETWEEN 1 AND 5 --OLD資料
--COMMIT TRAN --Don't commit
SELECT @@SPID
/*
(1 行受影響)
ID COL
----------- ----------------
1 A
(1 行受影響)
------
52
(1 行受影響)
*/
查詢二:
INSERT TB SELECT 2,'E'
查詢三:
exec sp_us_lockinfo

在使用可序列化事務隔離級別時,對於 Transact-SQL 語句讀取的記錄集,鍵範圍鎖在索引獲上取鎖定阻止一切嘗試在包含索引鍵值落入範圍內增刪改的資料行,可以隱式保護該記錄集中包含的行範圍。鍵範圍鎖可防止幻讀。通過保護行之間鍵的範圍,它還防止對事務訪問的記錄集進行幻像插入或刪除。
例如我們在上面有例子的可序列化隔離級別下,選擇索引鍵值在’1-5’的資料時,SQL SERVER 對落在1-5之間鍵值設定鍵範圍鎖定,避免包含在這個範圍內的鍵值的插入及這個範圍內鍵值的刪除及更新。
最後強調一下鍵範圍鍵產生的條件:
1、 務隔離級別必須設定為 SERIALIZABLE。
2、詢處理器必須使用索引來實現範圍篩選謂詞。例如,SELEC中的 WHERE 子句。
3、鎖相容性矩陣
鎖相容性控制多個事務能否同時獲取同一資源上的鎖。如果資源已被另一事務鎖定,則僅當請求鎖的模式與現有鎖的模式相相容時,才會授予新的鎖請求。如果請求鎖的模式與現有鎖的模式不相容,則請求新鎖的事務將等待釋放現有鎖或等待鎖超時間隔過期。

4、深入可鎖定資源及特殊鎖定
可資源資源有哪些呢,我在前面已經用
SELECT * FROM MASTER..SPT_VALUES WHERE TYPE = 'LR'
進行了列表,一共有12種之多,其實我們從本篇的開始到現在一直在接觸的行鎖(RID),鍵鎖(KEY),分頁(PAG)、表(TAB)及物件(OBJECT)都是我們可鎖定的資源,這幾類我們已經接觸到很多了,下面我就不常關注的幾個進行一下說明。
EXT 這是資料或索引頁面擴充套件。這一塊如果以後有時間整理表的資料儲存或索引分頁的結構時可以細細說說擴充套件,現在我們可以簡單的理解為:擴充套件是一個64K的分配