
面向服務的體系架構(SOA)—入門篇
http://blog.csdn.net/aglne/article/details/70210774
1、面向服務的體系架構(SOA)
面向服務的架構(service-oriented architecture)是Gartner於2O世紀9O年代中期提出的面向服務架構的概念。2002年的l2月,Gartner提出“面向服務的架構(SOA)”是“現代應用開發領域最重要的課題”之後。國內外計算機專家、學者掀起了對SOA的積極研究與探索。
在分散式的環境中,將各種功能都以服務的形式提供給終端使用者或者其他服務。如今,企業級應用的開發都採用面向服務的體系架構來滿足靈活多變,可重用性高的需求。
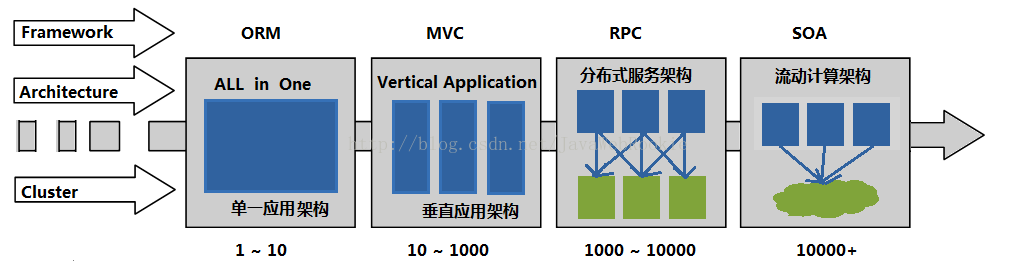
2、架構的演變過程
隨著網際網路技術迅速發展和演變,不斷改變的商業化應用系統越來越複雜,由單一的應用架構到垂直的應用架構,但還是面臨的擴容的問題。流量分散在各個系統中,雖然體積可控,但對開發人員和維護人員帶來極麻煩。此時,將核心的業務單獨提煉出來作為單獨的系統對外提供服務。達成業務之間複用,系統也將演變成分散式系統架構。分散式架構是各元件分佈在網路計算機上、元件之間僅僅通過訊息傳遞來通訊並協調行動。
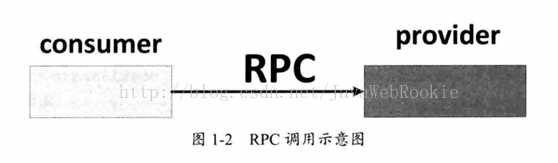
3、RPC簡介
RPC(Remote Procedure Call Protocol)——遠端過程呼叫協議,它是一種通過網路從遠端計算機程式上請求服務,而不需要了解底層網路技術的協議。RPC協議假定某些傳輸協議的存在,如TCP或UDP,為通訊程式之間攜帶資訊資料。在OSI網路通訊模型中,RPC跨越了傳輸層和應用層。RPC使得開發包括網路分散式多程式在內的應用程式更加容易。
4、分佈系統的基礎設施
4.1、分散式快取
Memcache 高效能物件快取系統,在記憶體中維護一個巨大的基於key-value的hashtable。可以用來快取任何資料。(物件通過序列化後,轉換成二進位制快取)當空間不夠用的時候採用LRU演算法淘汰資料。網路連線處理採用libevent,高效低耗。memcache採用的是基於tcp連線的memcache協議,協議可以承載文字行和結構化資料,文字行主要用來傳輸指令,結構化資料主要用來傳輸資料。
另外一種做法是講session快取在一個叢集上面,例如memcache叢集。這樣系統的吞吐量高,而且有利於對session的重新整理(session都是有有效期的,需要定期重新整理),但是缺點也顯而易見: 一旦cache叢集重啟,所有記憶體裡面的session將全部丟失。
Redis是一個高效能的key-value資料庫,也可以做快取,redis豐富的資料結構,其hash,list,set以及豐富的資料結構和超高的效能以及簡單的協議,讓Redis能夠很好的作為資料庫的上游快取層。但是我們會比較擔心Redis的單點問題,單點Redis容量大小總受限於記憶體,在業務對效能要求比較高的情況下,理想情況下我們希望所有的資料都能在記憶體裡面,不要打到資料庫上,所以很自然的就會尋求其他方案。 比如,SSD將記憶體換成了磁碟,以換取更大的容量。
4.2、持久化儲存
Hbase、MySQL、Redis傳統的IOE方案: IBM小型機Oracle資料庫 EMC持久儲存成本很高。傳統的資料庫提供完整地acid功能,並且提供豐富的內連線外連線關聯查詢等功能。但是,對於高併發應用來說,有的時候會犧牲關聯查詢事務資料一致性(降級為最終一致性)。
Hbase有更好地伸縮能力,更適合海量資料儲存。併發寫入十分出色,能夠支援多regionserver同時寫入。但是其本身對於查詢的支援力度有限,比如group by order by join等。
Redis是一個key-value型別的資料庫,能夠支援更高的併發量,而且支援的資料型別也比其他的key-value資料庫的資料型別多。
5、訊息系統
JMS即Java訊息服務(Java Message Service)應用程式介面,是一個Java平臺中關於面向訊息中介軟體(MOM)的API,用於在兩個應用程式之間,或分散式系統中傳送訊息,進行非同步通訊。Java訊息服務是一個與具體平臺無關的API,絕大多數MOM提供商都對JMS提供支援。
比如開源的ActiveMQ 是Apache出品,最流行的,能力強勁的開源訊息匯流排。
6、其他基礎設施
在分散式系統應用中,上面說的系統外,還有搜尋引擎系統、檔案系統、日誌系統、資料倉庫等等。
7、系統架構演化歷程
7.1、系統架構演化歷程-資料庫讀寫分離
資料庫寫入、更新的這些操作的部分資料庫連線的資源競爭非常激烈,導致了系統變慢。讀寫分離,是把對資料庫讀和寫的操作分開對應不同的資料庫伺服器。主資料庫提供寫操作,從資料庫提供讀操作。當主資料庫進行寫操作時,資料要同步到從的資料庫,有效保證資料庫完整性。
Quest SharePlex就是比較牛的同步資料工具,聽說比oracle本身的流複製還好,MySQL也有自己的同步資料技術。
mysql只要是通過二進位制日誌來複制資料。通過日誌在從資料庫重複主資料庫的操作達到複製資料目的。這個複製比較好的就是通過非同步方法,把資料同步到從資料庫,讀的操作怎麼樣分配到從資料庫上?應該根據伺服器的壓力把讀的操作分配到伺服器,而不是簡單的隨機分配。mysql提供了MySQL-Proxy實現讀寫分離操作。不過MySQL-Proxy好像很久不更新了。oracle可以通過F5有效分配讀從資料庫的壓力。
解決方案:mysql有Mysql Proxy、Amoeba、Atlas;
7.2、系統架構演化歷程-反向代理和CDN加速
為了應付複雜的網路環境和不同地區使用者的訪問,通過CDN和反向代理加快使用者訪問的速度,同時減輕後端伺服器的負載壓力。CDN與反向代理的基本原理都是快取。解決方案:Nginx,apache
7.3、系統架構演化歷程-分散式檔案系統和分散式資料庫
發現分庫後查詢仍然會有些慢,於是按照分庫的思想開始做分表的工作資料庫採用分散式資料庫(所有節點的資料加起來才算是整體資料),檔案系統採用分散式檔案系統任何強大的單一伺服器都滿足不了大型系統持續增長的業務需求,資料庫讀寫分離隨著業務的發展最終也將無法滿足需求,需要使用分散式資料庫及分散式檔案系統來支撐。分散式資料庫是系統資料庫拆分的最後方法,只有在單表資料規模非常龐大的時候才使用,更常用的資料庫拆分手段是業務分庫,將不同的業務資料庫部署在不同的物理伺服器上。
解決方案:mysql有mysql cluster 和 Mysql Proxy;mongodb(是一個基於分散式檔案儲存的資料庫);分散式檔案系統方案:CEPH、glusterfs、fastDFS、mogilefs 、moosefs,Hadoop實現了一個分散式檔案系統(Hadoop Distributed File System)
7.4、系統架構演化歷程-使用NoSQL和搜尋引擎
特徵:系統引入NoSQL資料庫及搜尋引擎。
描述:隨著業務越來越複雜,對資料儲存和檢索的需求也越來越複雜,系統需要採用一些非關係型資料庫如NoSQL和分資料庫查詢技術如搜尋引擎。應用伺服器通過統一資料訪問模組訪問各種資料,減輕應用程式管理諸多資料來源的麻煩。
7.5、系統架構演化歷程-業務拆分
特徵:系統上按照業務進行拆分改造,應用伺服器按照業務區分進行分別部署。描述:為了應對日益複雜的業務場景,通常使用分而治之的手段將整個系統業務分成不同的產品線,應用之間通過超連結建立關係,也可以通過訊息佇列進行資料分發,當然更多的還是通過訪問同一個資料儲存系統來構成一個關聯的完整系統。
縱向拆分:
將一個大應用拆分為多個小應用,如果新業務較為獨立,那麼就直接將其設計部署為一個獨立的Web應用系統、縱向拆分相對較為簡單,通過梳理業務,將較少相關的業務剝離即可。橫向拆分:
將複用的業務拆分出來,獨立部署為分散式服務,新增業務只需要呼叫這些分散式服務、橫向拆分需要識別可複用的業務,設計服務介面,規範服務依賴關係。
7.6、系統架構演化歷程-分散式服務
特徵:公共的應用模組被提取出來,部署在分散式伺服器上供應用伺服器呼叫。
描述:隨著業務越拆越小,應用系統整體複雜程度呈指數級上升,由於所有應用要和所有資料庫系統連線,最終導致資料庫連線資源不足,拒絕服務。
8、分散式服務應用會面臨哪些問題?
(1) 當服務越來越多時,服務URL配置管理變得非常困難,F5硬體負載均衡器的單點壓力也越來越大。
(2) 當進一步發展,服務間依賴關係變得錯蹤複雜,甚至分不清哪個應用要在哪個應用之前啟動,架構師都不能完整的描述應用的架構關係。
(3) 接著,服務的呼叫量越來越大,服務的容量問題就暴露出來,這個服務需要多少機器支撐?什麼時候該加機器?
(4) 服務多了,溝通成本也開始上升,調某個服務失敗該找誰?服務的引數都有什麼約定?
(5) 一個服務有多個業務消費者,如何確保服務質量?
(6) 隨著服務的不停升級,總有些意想不到的事發生,比如cache寫錯了導致記憶體溢位,故障不可避免,每次核心服務一掛,影響一大片,人心慌慌,如何控制故障的影響面?服務是否可以功能降級?或者資源劣化?
9、分散式架構下系統間互動的5種通訊模式
request/response模式(同步模式):客戶端發起請求一直阻塞到服務端返回請求為止。
Callback(非同步模式):客戶端傳送一個RPC請求給伺服器,服務端處理後再發送一個訊息給訊息傳送端提供的
callback端點,此類情況非常合適以下場景:A元件傳送RPC請求給B,B處理完成後,需要通知A元件做後續處理。
Future模式:客戶端傳送完請求後,繼續做自己的事情,返回一個包含訊息結果的Future物件。客戶端需要使用返回結果時,使用Future物件的.get(),如果此時沒有結果返回的話,會一直阻塞到有結果返回為止。
Oneway模式:客戶端呼叫完繼續執行,不管接收端是否成功。
Reliable模式:為保證通訊可靠,將藉助於訊息中心來實現訊息的可靠送達,請求將做持久化儲存,在接收方線上時做送達,並由訊息中心保證異常重試。
1、面向服務的體系架構(SOA)
面向服務的架構(service-oriented architecture)是Gartner於2O世紀9O年代中期提出的面向服務架構的概念。2002年的l2月,Gartner提出“面向服務的架構(SOA)”是“現代應用開發領域最重要的課題”之後。國內外計算機專家、學者掀起了對SOA的積極研究與探索。
在分散式的環境中,將各種功能都以服務的形式提供給終端使用者或者其他服務。如今,企業級應用的開發都採用面向服務的體系架構來滿足靈活多變,可重用性高的需求。
2、架構的演變過程
隨著網際網路技術迅速發展和演變,不斷改變的商業化應用系統越來越複雜,由單一的應用架構到垂直的應用架構,但還是面臨的擴容的問題。流量分散在各個系統中,雖然體積可控,但對開發人員和維護人員帶來極麻煩。此時,將核心的業務單獨提煉出來作為單獨的系統對外提供服務。達成業務之間複用,系統也將演變成分散式系統架構。分散式架構是各元件分佈在網路計算機上、元件之間僅僅通過訊息傳遞來通訊並協調行動。
3、RPC簡介
RPC(Remote Procedure Call Protocol)——遠端過程呼叫協議,它是一種通過網路從遠端計算機程式上請求服務,而不需要了解底層網路技術的協議。RPC協議假定某些傳輸協議的存在,如TCP或UDP,為通訊程式之間攜帶資訊資料。在OSI網路通訊模型中,RPC跨越了傳輸層和應用層。RPC使得開發包括網路分散式多程式在內的應用程式更加容易。
4、分佈系統的基礎設施
4.1、分散式快取
Memcache 高效能物件快取系統,在記憶體中維護一個巨大的基於key-value的hashtable。可以用來快取任何資料。(物件通過序列化後,轉換成二進位制快取)當空間不夠用的時候採用LRU演算法淘汰資料。網路連線處理採用libevent,高效低耗。memcache採用的是基於tcp連線的memcache協議,協議可以承載文字行和結構化資料,文字行主要用來傳輸指令,結構化資料主要用來傳輸資料。
另外一種做法是講session快取在一個叢集上面,例如memcache叢集。這樣系統的吞吐量高,而且有利於對session的重新整理(session都是有有效期的,需要定期重新整理),但是缺點也顯而易見: 一旦cache叢集重啟,所有記憶體裡面的session將全部丟失。
Redis是一個高效能的key-value資料庫,也可以做快取,redis豐富的資料結構,其hash,list,set以及豐富的資料結構和超高的效能以及簡單的協議,讓Redis能夠很好的作為資料庫的上游快取層。但是我們會比較擔心Redis的單點問題,單點Redis容量大小總受限於記憶體,在業務對效能要求比較高的情況下,理想情況下我們希望所有的資料都能在記憶體裡面,不要打到資料庫上,所以很自然的就會尋求其他方案。 比如,SSD將記憶體換成了磁碟,以換取更大的容量。
4.2、持久化儲存
Hbase、MySQL、Redis傳統的IOE方案: IBM小型機Oracle資料庫 EMC持久儲存成本很高。傳統的資料庫提供完整地acid功能,並且提供豐富的內連線外連線關聯查詢等功能。但是,對於高併發應用來說,有的時候會犧牲關聯查詢事務資料一致性(降級為最終一致性)。
Hbase有更好地伸縮能力,更適合海量資料儲存。併發寫入十分出色,能夠支援多regionserver同時寫入。但是其本身對於查詢的支援力度有限,比如group by order by join等。
Redis是一個key-value型別的資料庫,能夠支援更高的併發量,而且支援的資料型別也比其他的key-value資料庫的資料型別多。
5、訊息系統
JMS即Java訊息服務(Java Message Service)應用程式介面,是一個Java平臺中關於面向訊息中介軟體(MOM)的API,用於在兩個應用程式之間,或分散式系統中傳送訊息,進行非同步通訊。Java訊息服務是一個與具體平臺無關的API,絕大多數MOM提供商都對JMS提供支援。
比如開源的ActiveMQ 是Apache出品,最流行的,能力強勁的開源訊息匯流排。
6、其他基礎設施
在分散式系統應用中,上面說的系統外,還有搜尋引擎系統、檔案系統、日誌系統、資料倉庫等等。
7、系統架構演化歷程
7.1、系統架構演化歷程-資料庫讀寫分離
資料庫寫入、更新的這些操作的部分資料庫連線的資源競爭非常激烈,導致了系統變慢。讀寫分離,是把對資料庫讀和寫的操作分開對應不同的資料庫伺服器。主資料庫提供寫操作,從資料庫提供讀操作。當主資料庫進行寫操作時,資料要同步到從的資料庫,有效保證資料庫完整性。
Quest SharePlex就是比較牛的同步資料工具,聽說比oracle本身的流複製還好,MySQL也有自己的同步資料技術。
mysql只要是通過二進位制日誌來複制資料。通過日誌在從資料庫重複主資料庫的操作達到複製資料目的。這個複製比較好的就是通過非同步方法,把資料同步到從資料庫,讀的操作怎麼樣分配到從資料庫上?應該根據伺服器的壓力把讀的操作分配到伺服器,而不是簡單的隨機分配。mysql提供了MySQL-Proxy實現讀寫分離操作。不過MySQL-Proxy好像很久不更新了。oracle可以通過F5有效分配讀從資料庫的壓力。
解決方案:mysql有Mysql Proxy、Amoeba、Atlas;
7.2、系統架構演化歷程-反向代理和CDN加速
為了應付複雜的網路環境和不同地區使用者的訪問,通過CDN和反向代理加快使用者訪問的速度,同時減輕後端伺服器的負載壓力。CDN與反向代理的基本原理都是快取。解決方案:Nginx,apache
7.3、系統架構演化歷程-分散式檔案系統和分散式資料庫
發現分庫後查詢仍然會有些慢,於是按照分庫的思想開始做分表的工作資料庫採用分散式資料庫(所有節點的資料加起來才算是整體資料),檔案系統採用分散式檔案系統任何強大的單一伺服器都滿足不了大型系統持續增長的業務需求,資料庫讀寫分離隨著業務的發展最終也將無法滿足需求,需要使用分散式資料庫及分散式檔案系統來支撐。分散式資料庫是系統資料庫拆分的最後方法,只有在單表資料規模非常龐大的時候才使用,更常用的資料庫拆分手段是業務分庫,將不同的業務資料庫部署在不同的物理伺服器上。
解決方案:mysql有mysql cluster 和 Mysql Proxy;mongodb(是一個基於分散式檔案儲存的資料庫);分散式檔案系統方案:CEPH、glusterfs、fastDFS、mogilefs 、moosefs,Hadoop實現了一個分散式檔案系統(Hadoop Distributed File System)
7.4、系統架構演化歷程-使用NoSQL和搜尋引擎
特徵:系統引入NoSQL資料庫及搜尋引擎。
描述:隨著業務越來越複雜,對資料儲存和檢索的需求也越來越複雜,系統需要採用一些非關係型資料庫如NoSQL和分資料庫查詢技術如搜尋引擎。應用伺服器通過統一資料訪問模組訪問各種資料,減輕應用程式管理諸多資料來源的麻煩。
7.5、系統架構演化歷程-業務拆分
特徵:系統上按照業務進行拆分改造,應用伺服器按照業務區分進行分別部署。描述:為了應對日益複雜的業務場景,通常使用分而治之的手段將整個系統業務分成不同的產品線,應用之間通過超連結建立關係,也可以通過訊息佇列進行資料分發,當然更多的還是通過訪問同一個資料儲存系統來構成一個關聯的完整系統。
縱向拆分:
將一個大應用拆分為多個小應用,如果新業務較為獨立,那麼就直接將其設計部署為一個獨立的Web應用系統、縱向拆分相對較為簡單,通過梳理業務,將較少相關的業務剝離即可。橫向拆分:
將複用的業務拆分出來,獨立部署為分散式服務,新增業務只需要呼叫這些分散式服務、橫向拆分需要識別可複用的業務,設計服務介面,規範服務依賴關係。
7.6、系統架構演化歷程-分散式服務
特徵:公共的應用模組被提取出來,部署在分散式伺服器上供應用伺服器呼叫。
描述:隨著業務越拆越小,應用系統整體複雜程度呈指數級上升,由於所有應用要和所有資料庫系統連線,最終導致資料庫連線資源不足,拒絕服務。
8、分散式服務應用會面臨哪些問題?
(1) 當服務越來越多時,服務URL配置管理變得非常困難,F5硬體負載均衡器的單點壓力也越來越大。
(2) 當進一步發展,服務間依賴關係變得錯蹤複雜,甚至分不清哪個應用要在哪個應用之前啟動,架構師都不能完整的描述應用的架構關係。
(3) 接著,服務的呼叫量越來越大,服務的容量問題就暴露出來,這個服務需要多少機器支撐?什麼時候該加機器?
(4) 服務多了,溝通成本也開始上升,調某個服務失敗該找誰?服務的引數都有什麼約定?
(5) 一個服務有多個業務消費者,如何確保服務質量?
(6) 隨著服務的不停升級,總有些意想不到的事發生,比如cache寫錯了導致記憶體溢位,故障不可避免,每次核心服務一掛,影響一大片,人心慌慌,如何控制故障的影響面?服務是否可以功能降級?或者資源劣化?
9、分散式架構下系統間互動的5種通訊模式
request/response模式(同步模式):客戶端發起請求一直阻塞到服務端返回請求為止。
Callback(非同步模式):客戶端傳送一個RPC請求給伺服器,服務端處理後再發送一個訊息給訊息傳送端提供的
callback端點,此類情況非常合適以下場景:A元件傳送RPC請求給B,B處理完成後,需要通知A元件做後續處理。
Future模式:客戶端傳送完請求後,繼續做自己的事情,返回一個包含訊息結果的Future物件。客戶端需要使用返回結果時,使用Future物件的.get(),如果此時沒有結果返回的話,會一直阻塞到有結果返回為止。
Oneway模式:客戶端呼叫完繼續執行,不管接收端是否成功。
Reliable模式:為保證通訊可靠,將藉助於訊息中心來實現訊息的可靠送達,請求將做持久化儲存,在接收方線上時做送達,並由訊息中心保證異常重試。