
為 Caffe 新增新的 DataLayer
目標
復現 DeepID 用 Caffe 實現人臉識別時,網路的訓練的框架往往是這樣的:
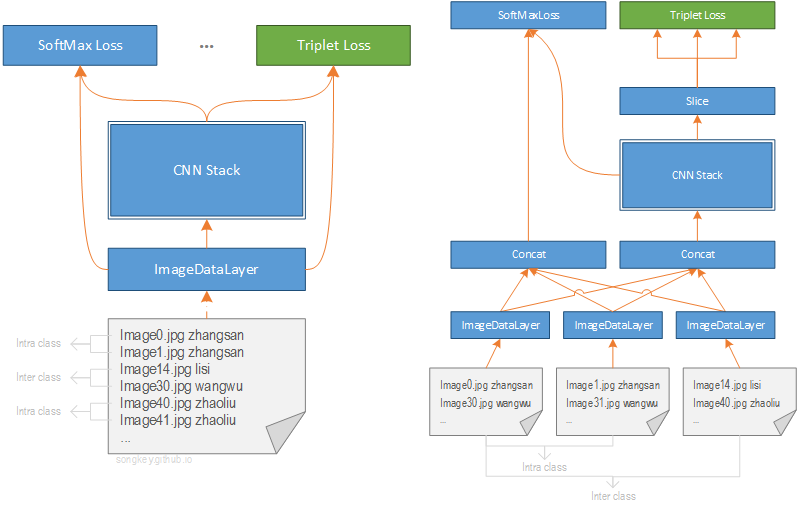
就是說 Image List 中的資料是按對整理好的,類內 (intra class) 類間 (inter class) 資料交替排列。這樣就可以直接利用 ImageDataLayer 獲得一個個均勻的 Batch。現在只要對 Loss Layer 簡單做一下修改,網路已經可以正常訓練了,相當簡單。
但簡單的代價也相當明顯:
- 資料類內與類間的組合已經固定,想用新的組合訓練,就得重新整理一個 ImageList。
- 左圖中類內資料與類間資料交替排列的方式不利於 LossLayer 計算的優化。
新的框架
所以如果能把資料整理這一步整合到 DataLayer 中,將會得到更大程度的簡化。而且可以額外附加一些功能,比如隨機抽取類內類間資料;類內資料抽取區別較大的組合,類間資料則抽取區別較小的組合,如果計算速度允許的話。
於是新的訓練框架應該是下面這樣的,DataLayer 的名字都取好了,叫 TripletDataLayer!
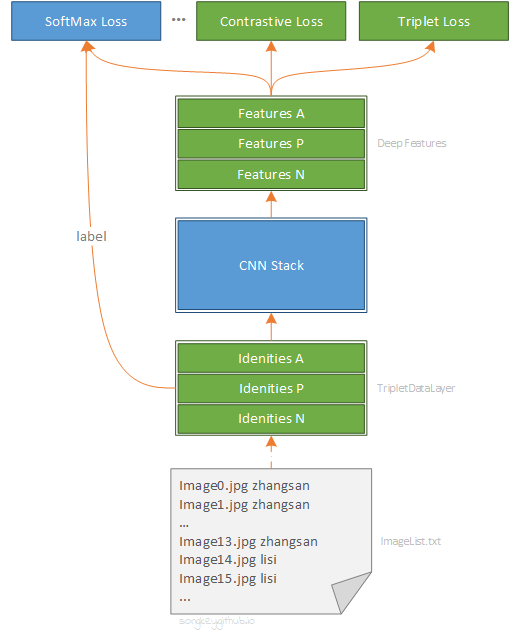
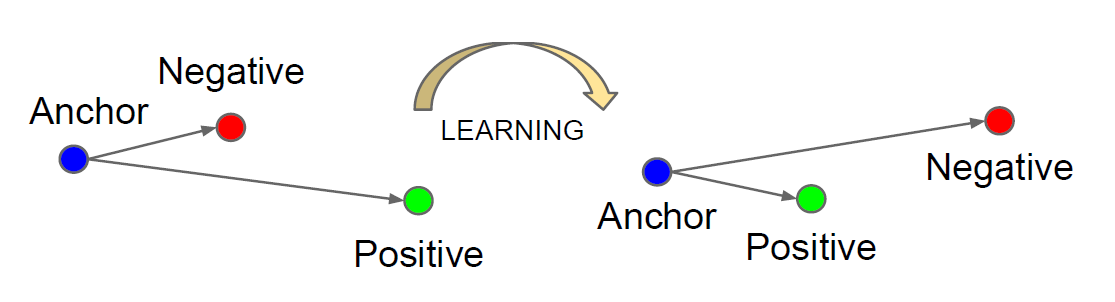
TripletDataLayer 會在每次迭代過程中抽取一個 Batch 的資料,Batch 中的資料等分為 Idenities A, Idenities P, Idenities N 三個部分, 分別代表 FaceNet 1 中提出的 Anchor, Positive, Negative。Anchor 與 Positive 是類內組合,Anchor 與 Negative 是類間組合,後面都用這種方式表示。可以看到由於 Batch 內的資料是有序的,對應的 Loss Layer 就不需要 label 資訊了(SoftMax Loss 除外)。
TripletDataLayer 的實現
為 Caffe 新增新資料層的步驟 ( 以 TripletDataLayer 為例 ) 如下:
- 在 src/caffe/proto/caffe.proto 中定義相關的引數
- 在 src/caffe/layers/ 目錄下新增 triplet_data_layer.cpp
- 在 include/caffe/layers/ 目錄下新增 triplet_data_layer.hpp
- 在 src/caffe/test 目錄下新增 test_triplet_data_layer.cpp (可選)
第 2, 3 步就是實現 TripletDataLayer 類,最為重要。然後把需要定製的引數新增到 caffe.proto 檔案中。準確地完成這兩步的話,新增 DataLayer 層的工作就算完成了。如果不能確定,最好在 src/caffe/test 目錄下寫一個測試用例。
分析 ImageDataLayer
我的實現原則是 對 Caffe 原始碼做最少的修改。縱觀現有的 DataLayer 最佳參考的是 ImageDataLayer 。理所當然地應該分析一下它的實現,下面是我畫的一個非常粗糙的 ImageDataLayer 類圖:
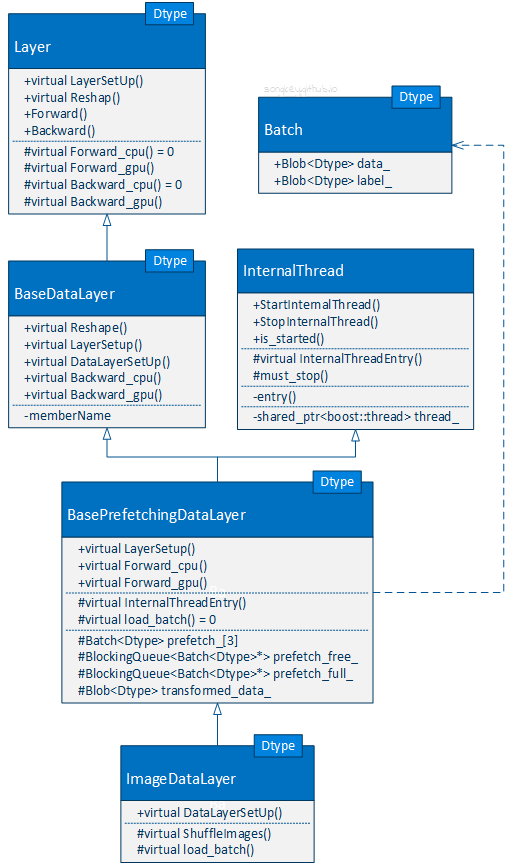
可以看到,ImageDataLayer 與普通的 Layer 不同,它不需要實現 .cu 檔案。因為 GPU 的操作已經在高層的類中實現了,同樣資料預取操作 (經典的生產者消費者問題,每次預取 3 個 Batch) 也已在高層類中實現。所以我們只要重寫 load_batch() 函式即可。
在 caffe.proto 中定義外部引數
為引數定義一個 message 結構
在 ImageDataParameter 的基礎上修改。雖然結構名的選擇是自由的,但最好按 Caffe 的風格來寫,即結構名與類名對應。有關 protobuf 的語法請自行 Google。
message TripletDataParameter
{
// 圖片列表的路徑,可以是檔名或檔案路徑
required string source = 1;
// 是否根據圖片的特徵篩選資料
optional bool use_feature = 15 [default = false];
// 圖片特徵檔案的副檔名,特徵檔案與對應圖片位於同一目錄下
optional string feature_extension = 14 [default = ".feat"];
// 如果每個人的圖片數量不等時,讓每個 Batch 的資料分佈與訓練集相同
optional bool batch_follow_distribution = 16 [default = true];
// 存放圖片的目錄(所有圖片都存放在同一目錄時使用)
optional string root_folder = 12 [default = ""];
// Batch size,Layer 初始化時把它改為 3 的倍數
optional uint32 batch_size = 4 [default = 1];
// 啟動時隨機跳過幾個數據,與 ImageDataLayer 略有不同
optional uint32 rand_skip = 7 [default = 0];
// 下面的引數的意義與 ImageDataLayer 完全相同
optional bool shuffle = 8 [default = false];
optional uint32 new_height = 9 [default = 0];
optional uint32 new_width = 10 [default = 0];
optional bool is_color = 11 [default = true];
optional float scale = 2 [default = 1];
optional string mean_file = 3;
optional uint32 crop_size = 5 [default = 0];
optional bool mirror = 6 [default = false];
}在 LayerParameter 中新增引數的定義
同樣,為了統一性引數名照樣與類名相關。應注意標識號不能與前面的欄位重複。
message LayerParameter {
...
optional TripletDataParameter triplet_data_param = 512;
}然後在 TripletDataLayer 類中就可以讀取這些引數了 ( caffe.pb.cc 與 caffe.pb.h 會在 Caffe 編譯過程中自動編譯出來 )。比如我們想讀取配置檔案中的 batch_size 引數,可以這樣做:
int batch_size_ = this->layer_param_.triplet_data_param().batch_size();