
計算機體系結構
下面是網上看到的一些關於記憶體和CPU方面的一些很不錯的文章. 整理如下:
轉: CPU的等待有多久?
原文標題:What Your Computer Does While You Wait
原文地址:http://duartes.org/gustavo/blog/
[注:本人水平有限,只好挑一些國外高手的精彩文章翻譯一下。一來自己複習,二來與大家分享。]
本文以一個現代的、實際的個人電腦為物件,分析其中CPU(Intel Core 2 Duo 3.0GHz)以及各類子系統的執行速度——延遲和資料吞吐量。通過粗略的估算PC各個元件的相對執行速度,希望能給大家留下一個比較直觀的印象。本文中的資料來自實際應用,而非理論最大值。時間的單位是納秒(ns,十億分之一秒),毫秒(ms,千分之一秒),和秒(s)。吞吐量的單位是兆位元組(MB)和千兆位元組(GB)。讓我們先從CPU和記憶體開始,下圖是北橋部分:
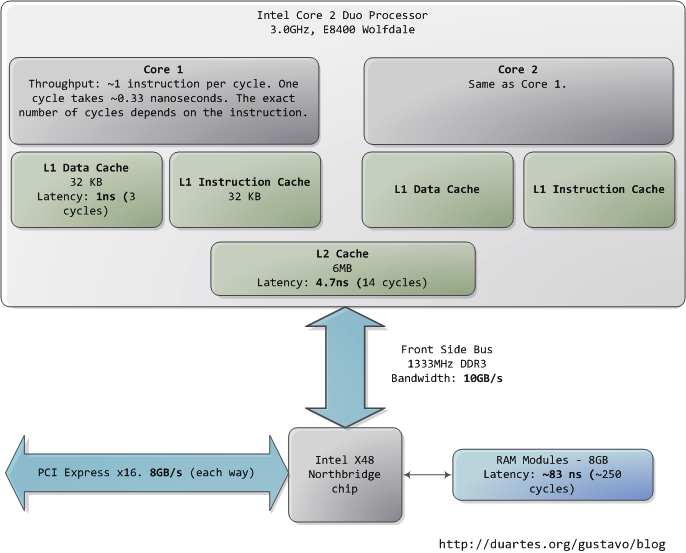
第一個令人驚歎的事實是:CPU快得離譜。在Core 2 3.0GHz上,大部分簡單指令的執行只需要一個時鐘週期,也就是1/3納秒。即使是真空中傳播的光,在這段時間內也只能走10釐米(約4英寸)。把上述事實記在心中是有好處的。當你要對程式做優化的時候就會想到,執行指令的開銷對於當今的CPU而言是多麼的微不足道。
當CPU運轉起來以後,它便會通過L1 cache和L2 cache對系統中的主存進行讀寫訪問。cache使用的是靜態儲存器(SRAM)。相對於系統主存中使用的動態儲存器(DRAM),cache讀寫速度快得多、造價也高昂得多。cache一般被放置在CPU晶片的內部,加之使用昂貴高速的儲存器,使其給CPU帶來的延遲非常低。在指令層次上的優化(instruction-level optimization),其效果是與優化後代碼的大小息息相關。由於使用了快取記憶體技術(caching),那些能夠整體放入L1/L2 cache中的程式碼,和那些在執行時需要不斷調入/調出(marshall into/out of)cache的程式碼,在效能上會產生非常明顯的差異。
正常情況下,當CPU操作一塊記憶體區域時,其中的資訊要麼已經儲存在L1/L2 cache,要麼就需要將之從系統主存中調入cache,然後再處理。如果是後一種情況,我們就碰到了第一個瓶頸,一個大約250個時鐘週期的延遲。在此期間如果CPU沒有其他事情要做,則往往是處在停機狀態的(stall)。為了給大家一個直觀的印象,我們把CPU的一個時鐘週期看作一秒。那麼,從L1 cache讀取資訊就好像是拿起桌上的一張草稿紙(3秒);從L2 cache讀取資訊則是從身邊的書架上取出一本書(14秒);而從主存中讀取資訊則相當於走到辦公樓下去買個零食(4分鐘)。
主存操作的準確延遲是不固定的,與具體的應用以及其他許多因素有關。比如,它依賴於列選通延遲(CAS)以及記憶體條的型號,它還依賴於CPU指令預取的成功率。指令預取可以根據當前執行的程式碼來猜測主存中哪些部分即將被使用,從而提前將這些資訊載入cache。
看看L1/L2 cache的效能,再對比主存,就會發現:配置更大的cache或者編寫能更好的利用cache的應用程式,會使系統的效能得到多麼顯著的提高。如果想進一步瞭解有關記憶體的諸多資訊,讀者可以參閱Ulrich Drepper所寫的一篇經典文章《What Every Programmer Should Know About Memory》。
人們通常把CPU與記憶體之間的瓶頸叫做馮·諾依曼瓶頸(von Neumann bottleneck)。當今系統的前端匯流排頻寬約為10GB/s,看起來很令人滿意。在這個速度下,你可以在1秒內從記憶體中讀取8GB的資訊,或者10納秒內讀取100字 節。遺憾的是,這個吞吐量只是理論最大值(圖中其他資料為實際值),而且是根本不可能達到的,因為主存控制電路會引入延遲。在做記憶體訪問時,會遇到很多零 散的等待週期。比如電平協議要求,在選通一行、選通一列、取到可靠的資料之前,需要有一定的訊號穩定時間。由於主存中使用電容來儲存資訊,為了防止因自然 放電而導致的資訊丟失,就需要週期性的重新整理它所儲存的內容,這也帶來額外的等待時間。某些連續的記憶體訪問方式可能會比較高效,但仍然具有延時。而那些隨機 的記憶體訪問則消耗更多時間。所以延遲是不可避免的。
圖中下方的南橋連線了很多其他匯流排(如:PCI-E, USB)和外圍裝置:
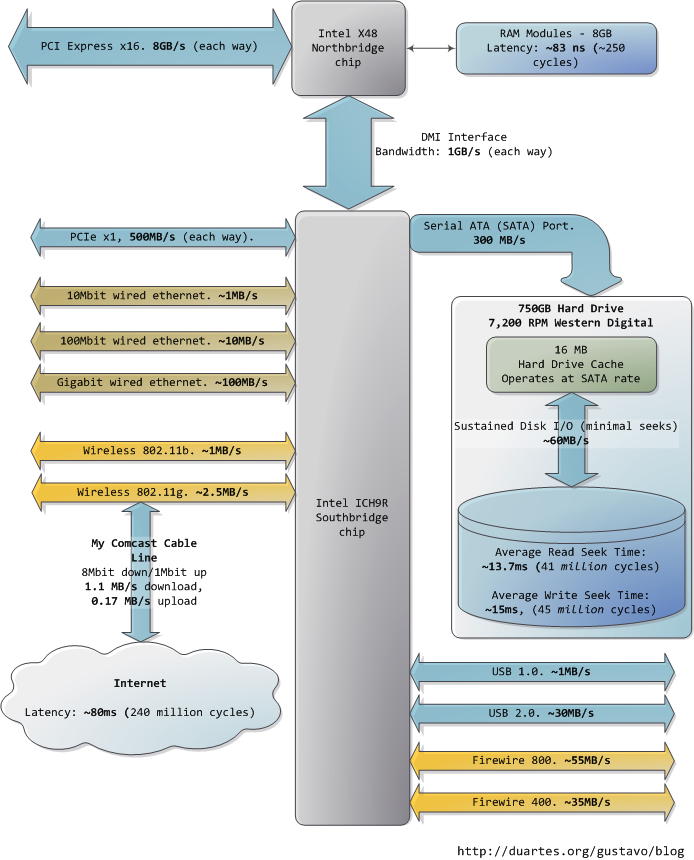
令人沮喪的是,南橋管理了一些反應相當遲鈍的裝置,比如硬碟。就算是緩慢的系統主存,和硬碟相比也可謂速度如飛了。繼續拿辦公室做比喻,等待硬碟尋道的時間相當於離開辦公大樓並開始長達一年零三個月的環球旅行。這就解釋了為何電腦的大部分工作都受制於磁碟I/O,以及為何資料庫的效能在記憶體緩衝區被耗盡後會陡然下降。同時也解釋了為何充足的RAM(用於緩衝)和高速的磁碟驅動器對系統的整體效能如此重要。
雖然磁碟的"連續"存取速度確實可以在實際使用中達到,但這並非故事的全部。真正令人頭疼的瓶頸在於尋道操作,也就是在磁碟表面移動讀寫磁頭到正確的磁軌上,然後再等待磁碟旋轉到正確的位置上,以便讀取指定扇區內的資訊。RPM(每分鐘繞轉次數)用來指示磁碟的旋轉速度:RPM越大,耽誤在尋道上的時間就越少,所以越高的RPM意味著越快的磁碟。這裡有一篇由兩個Stanford的研究生寫的很酷的文章,其中講述了尋道時間對系統性能的影響:《Anatomy of a Large-Scale Hypertextual Web Search Engine》
當 磁碟驅動器讀取一個大的、連續儲存的檔案時會達到更高的持續讀取速度,因為省去了尋道的時間。檔案系統的碎片整理器就是用來把檔案資訊重組在連續的資料塊 中,通過儘可能減少尋道來提高資料吞吐量。然而,說到計算機實際使用時的感受,磁碟的連續存取速度就不那麼重要了,反而應該關注驅動器在單位時間內可以完 成的尋道和隨機I/O操作的次數。對此,固態硬碟可以成為一個很棒的選擇。
硬碟的cache也有助於改進效能。雖然16MB的cache只能覆蓋整個磁碟容量的0.002%,可別看cache只有這麼一點大,其效果十分明顯。它可以把一組零散的寫入操作合成一個,也就是使磁碟能夠控制寫入操作的順序,從而減少尋道的次數。同樣的,為了提高效率,一系列讀取操作也可以被重組,而且作業系統和驅動器韌體(firmware)都會參與到這類優化中來。
最後,圖中還列出了網路和其他匯流排的實際資料吞吐量。火線(fireware)僅供參考,Intel X48晶片組並不直接支援火線。我們可以把Internet看作是計算機之間的匯流排。去訪問那些速度很快的網站(比如google.com),延遲大約45毫秒,與硬碟驅動器帶來的延遲相當。事實上,儘管硬碟比記憶體慢了5個數量級,它的速度與Internet是在同一數量級上的。目前,一般家用網路的頻寬還是要落後於硬碟連續讀取速度的,但"網路就是計算機"這句話可謂名符其實。如果將來Internet比硬碟還快了,那會是個什麼景象呢?
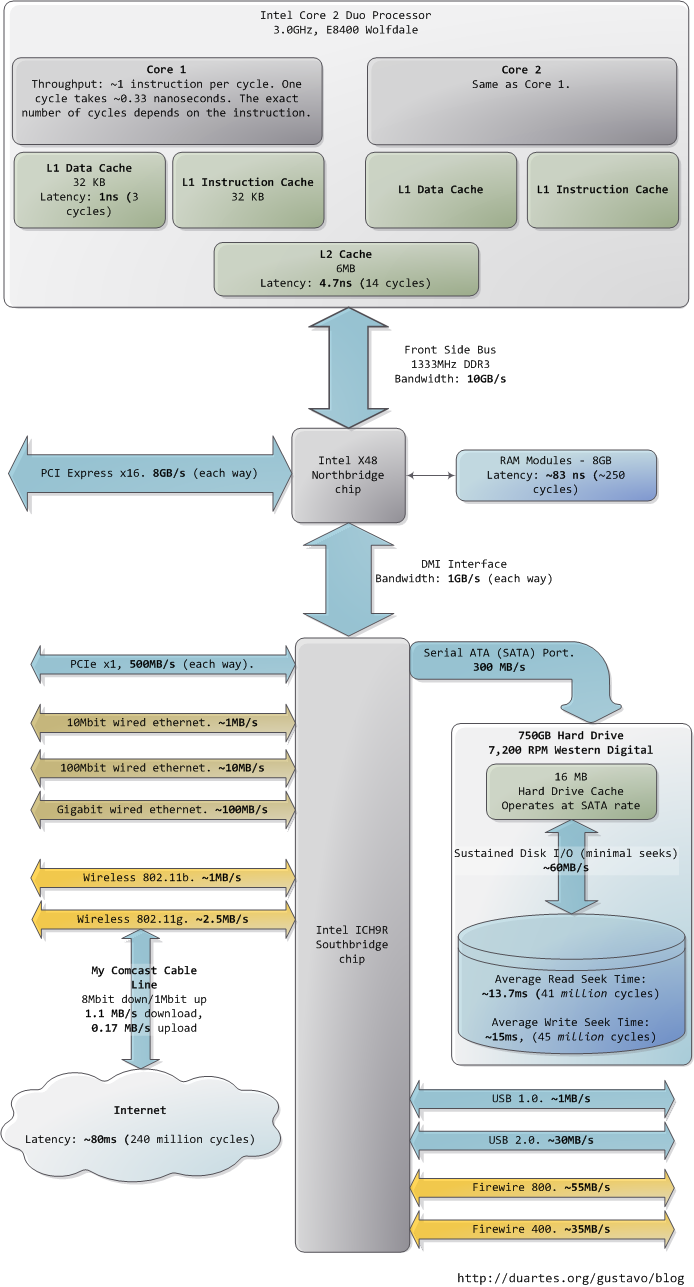
我希望這些圖片能對您有所幫助。當這些數字一起呈現在我面前時,真的很迷人,也讓我看到了計算機技術發展到了哪一步。前文分開的兩個圖片只是為了敘述方便,我把包含南北橋的整張圖片也貼出來,供您參考。
轉: CPU如何操作記憶體
原文標題:Getting Physical With Memory
原文地址:http://duartes.org/gustavo/blog/
[注:本人水平有限,只好挑一些國外高手的精彩文章翻譯一下。一來自己複習,二來與大家分享。]
在你試圖理解一個複雜的系統時,如果能揭去表面的抽象並專注於最低級別的概念,往往會有不小的收穫。在這個精神的指導下,讓我們看看對於記憶體和I/O埠操作來說最簡單、最基礎的概念,即CPU與匯流排之間的介面。其中的細節是很多上層概念的基礎,比如執行緒同步。當然了,既然我是個程式設計師,就暫且忽略那些只有電子工程師才會去關注的東西吧。下圖是我們的老朋友,Core 2:
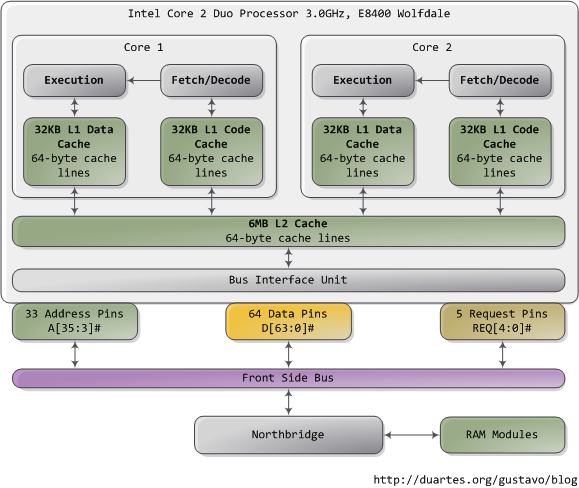
Core 2 處理器有775個管腳,其中約半數僅僅用於供電而不參與資料傳輸。當你把這些管腳按照功能分類後,就會發現這個處理器的物理介面驚人的簡單。本圖展示了參與記憶體和I/O埠操作的重要管腳:地址線,資料線,請求線。這些操作均發生在前端匯流排的事務上下文結構(the context of a transaction)中。前端匯流排事務的執行包含五個階段:仲裁,請求,偵聽,響應,資料操作。在執行事務的過程中,前端總線上的各個部件扮演著不同的角色。這些部件稱之為agent。通常,agent就是全部的處理器外加北橋。
本文只分析請求階段。在此階段中,發出請求的agent往往是一個處理器,它輸出兩個資料包。下圖列出了第一個資料包中最為重要的位,這些資料位通過處理器的地址線和請求線輸出:
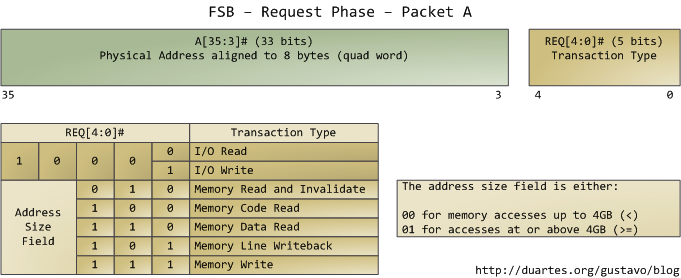
地址線輸出指定了事務發生的實體記憶體起始地址。我們有33條地址線,他們指定了資料包的第35至第3位,第2至第0位為0。因此,實際上這33條地址線構成了一個36位的、以8位元組對齊的地址,正好覆蓋64GB的實體記憶體。這種設定從奔騰Pro就開始了。請求線指定了事務的型別。當事務型別為I/O請求時,地址線指出的是I/O埠地址而不是記憶體地址。當第一個資料包被髮送以後,同樣由這組管腳,在下一個匯流排時鐘週期傳送第二個資料包:
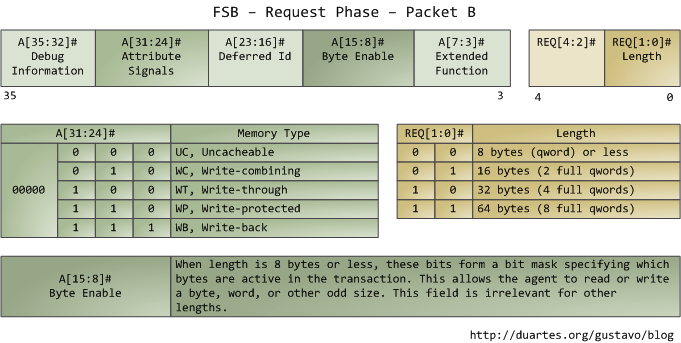
屬性訊號(attribute signal A[31:24])很有趣,它反映了Intel處理器所支援的5種記憶體緩衝功能。把這些資訊釋出到前端匯流排後,發出請求的agent就可以讓其他處理器知道如何根據當前事務處理他們自己的cache,以及讓記憶體控制器(也就是北橋)知道該如何應對。一塊指定記憶體區域的快取型別由處理器通過查詢頁表(page table)來決定,頁表由OS核心維護。
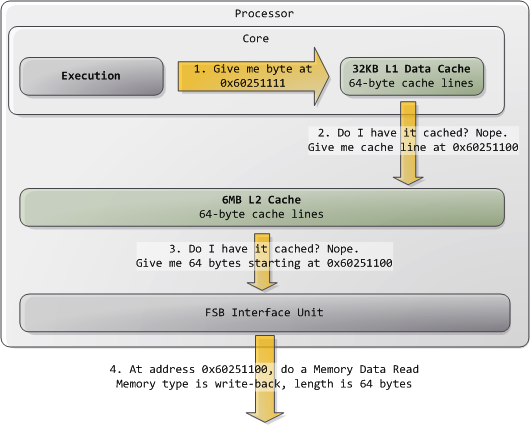
典型的情況是,核心把全部記憶體都視為"回寫"型別(write-back),從而獲得最好的效能。在回寫模式下,記憶體的最小訪問單元為一個快取線(cache line),在Core 2中是64位元組。當程式想讀取記憶體中的一個位元組時,處理器會從L1/L2 cache讀取包含此位元組的整條快取線的內容。當程式做寫入記憶體操作時,處理器只是修改cache中的對應快取線,而不會更新主存中的資訊。之後,當真的需要更新主存時,處理器會把那個被修改了的快取線整體放到總線上,一次性寫入記憶體。所以大部分的請求事務,其資料長度欄位都是11(REQ[1:0]),對應64 位元組。下圖展示了當cache中沒有對應資料時,記憶體讀取訪問的過程:
在Intel計算機上,有些實體記憶體範圍被對映為裝置地址而不是實際的RAM儲存器地址,比如硬碟和網絡卡。這使得驅動程式可以像讀寫記憶體那樣,方便的與裝置通訊。核心會在頁表中標記出這類記憶體對映區域為不可快取的(uncacheable)。對不可快取的記憶體區域的訪問操作會被匯流排原封不動的按順序執行,其操作與應用程式或驅動程式所發出的請求完全一致。因此,這時程式可以精確控制讀寫單個位元組、字、或其它長度的資訊。這都是通過設定第二個資料包中的位元組使能掩碼(byte enable mask A[15:8])來完成的。
前面討論的這些基本知識還包含很多關聯的內容。比如:
1、 如果應用程式想要儘可能高的執行速度,就應該把會被一起訪問的資料儘量組織在同一條快取線中。一旦這條快取線被載入,之後的讀取操作就會加快很多,不再需要額外的記憶體訪問了。
2、 對於回寫式記憶體訪問,作用於一條快取線的任何記憶體操作都一定是原子的(atomic)。這種能力是由處理器的L1 cache提供的,所有資料被同時讀寫,中途不會被其他處理器或執行緒打斷。特別的,32位和64位的記憶體操作,只要不跨越快取線的邊界,就都是原子操作。
3、 前端匯流排是被所有的agent所共享的。這些agent在開啟一個事務之前,必須先進行匯流排使用權的仲裁。而且,每一個agent都需要偵聽總線上所有的事務,以便維持cache的一致性。因此,隨著部署更多的、多核的處理器到Intel計算機,匯流排競爭問題會變得越來越嚴重。為解決這個問題,Core i7將處理器直接連線於記憶體,並以點對點的方式通訊,取代之前的廣播方式,從而減少匯流排競爭。
本 文講述的都是有關實體記憶體請求的重要內容。當涉及到記憶體鎖定、多執行緒、快取一致性的問題時,匯流排這個角色又將浮出水面。當我第一次看到前端匯流排資料包的描 述時,會有種恍然大悟的感覺,所以我希望您也能從本文中獲益。下一篇文章,我們將從底層爬回到上層去,研究一個抽象概念:虛擬記憶體。
[轉]: 主機板晶片組與記憶體對映
原文標題:Motherboard Chipsets and the Memory Map
原文地址:http://duartes.org/gustavo/blog/
[注:本人水平有限,只好挑一些國外高手的精彩文章翻譯一下。一來自己複習,二來與大家分享。]
我打算寫一組講述計算機內幕的文章,旨在揭示現代作業系統核心的工作原理。我希望這些文章能對電腦愛好者和程式設計師有所幫助,特別是對這類話題感興趣但沒有相關知識的人們。討論的焦點是Linux,Windows,和Intel處理器。鑽研系統內幕是我的一個愛好。我曾經編寫過不少核心模式的程式碼,只是最近一段時間不再寫了。這第一篇文章講述了現代Intel主機板的佈局,CPU如何訪問記憶體,以及系統的記憶體對映。
作為開始,讓我們看看當今的Intel計算機是如何連線各個元件的吧。下圖展示了主機板上的主要元件:
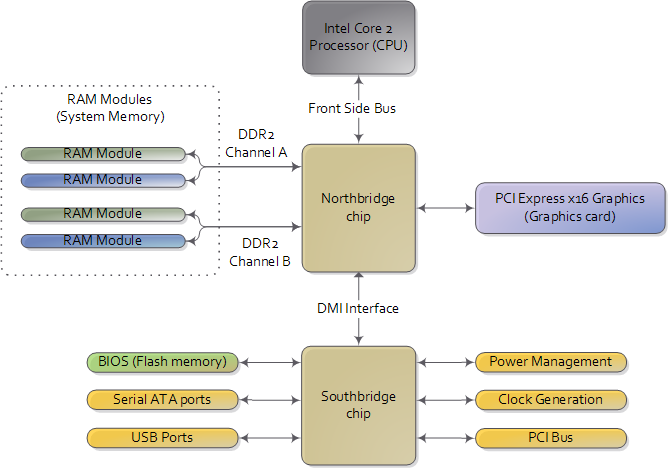
現代主機板的示意圖,北橋和南橋構成了晶片組。
當你看圖時,請牢記一個至關重要的事實:CPU一點也不知道它連線了什麼東西。CPU僅僅通過一組針腳與外界互動,它並不關心外界到底有什麼。可能是一個電腦主機板,但也可能是烤麵包機,網路路由器,植入腦內的裝置,或CPU測試工作臺。CPU主要通過3種方式與外界互動:記憶體地址空間,I/O地址空間,還有中斷。
眼下,我們只關心主機板和記憶體。安裝在主機板上的CPU與外界溝通的門戶是前端匯流排(front-side bus),前端匯流排把CPU與北橋連線起來。每當CPU需要讀寫記憶體時,都會使用這條匯流排。CPU通過一部分管腳來傳輸想要讀寫的實體記憶體地址,同時另一些管腳用於傳送將被寫入或接收被讀出的資料。一個Intel Core 2 QX6600有33個針腳用於傳輸實體記憶體地址(可以表示233個地址位置),64個針腳用於接收/傳送資料(所以資料在64位通道中傳輸,也就是8位元組的資料塊)。這使得CPU可以控制64GB的實體記憶體(233個地址乘以8位元組),儘管大多數的晶片組只能支援8GB的RAM。
現在到了最難理解的部分。我們可能曾經認為記憶體指的就是RAM,被各式各樣的程式讀寫著。的確,大部分CPU發出的記憶體請求都被北橋轉送給了RAM管理器,但並非全部如此。實體記憶體地址還可能被用於主機板上各種裝置間的通訊,這種通訊方式叫做記憶體對映I/O。這類裝置包括顯示卡,大多數的PCI卡(比如掃描器或SCSI卡),以及BIOS中的flash儲存器等。
當北橋接收到一個實體記憶體訪問請求時,它需要決定把這個請求轉發到哪裡:是發給RAM?抑或是顯示卡?具體發給誰是由記憶體地址對映表來決定的。對映表知道每一個實體記憶體地址區域所對應的裝置。絕大部分的地址被對映到了RAM,其餘地址由對映表來通知晶片組該由哪個裝置來響應此地址的訪問請求。這些被對映為裝置的記憶體地址形成了一個經典的空洞,位於PC記憶體的640KB到1MB之間。當記憶體地址被保留用於顯示卡和PCI裝置時,就會形成更大的空洞。這就是為什麼32位的作業系統無法使用全部的4GB RAM。Linux中,/proc/iomem這個檔案簡明的列舉了這些空洞的地址範圍。下圖展示了Intel PC低端4GB實體記憶體地址形成的一個典型的記憶體對映:
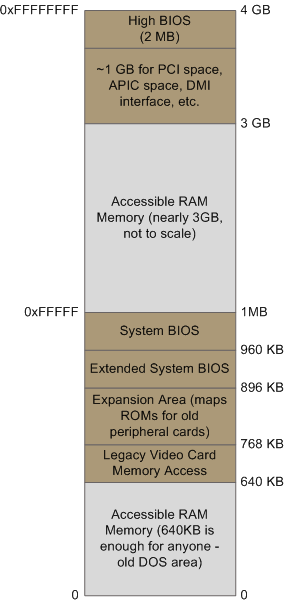
Intel系統中,低端4GB記憶體地址空間的佈局。
實際的地址和範圍依賴於特定的主機板和電腦中接入的裝置,但是對於大多數Core 2系統,情形都跟上圖非常接近。所有棕色的區域都被裝置地址對映走了。記住,這些在主機板總線上使用的都是實體地址。在CPU內部(比如我們正在編寫和執行的程式),使用的是邏輯地址,必須先由CPU翻譯成實體地址以後,才能釋出到總線上去訪問記憶體。
這個把邏輯地址翻譯成實體地址的規則比較複雜,而且還依賴於當時CPU的執行模式(真實模式,32位保護模式,64位保護模式)。不管採用哪種翻譯機制,CPU的執行模式決定了有多少實體記憶體可以被訪問。比如,當CPU工作於32位保護模式時,它只可以定址4GB實體地址空間(當然,也有個例外叫做實體地址擴充套件,但暫且忽略這個技術吧)。由於頂部的大約1GB實體地址被對映到了主機板上的裝置,CPU實際能夠使用的也就只有大約3GB的RAM(有時甚至更少,我曾用過一臺安裝了Vista的電腦,它只有2.4GB可用)。如果CPU工作於真實模式,那麼它將只能定址1MB的實體地址空間(這是早期的Intel處理器所支援的唯一模式)。如果CPU工作於64位保護模式,則可以定址64GB的地址空間(雖然很少有晶片組支援這麼大的RAM)。處於64位保護模式時,CPU就有可能訪問到RAM空間中被主機板上的裝置對映走了的區域了(即訪問空洞下的RAM)。要達到這種效果,就需要使用比系統中所裝載的RAM地址區域更高的地址。這種技術叫做回收(reclaiming),而且還需要晶片組的配合。
這些關於記憶體的知識將為下一篇文章做好鋪墊。下次我們會探討機器的啟動過程:從上電開始,直到boot loader準備跳轉執行作業系統核心為止。如果你想更深入的學習這些東西,我強烈推薦Intel手冊。雖然我列出的都是第一手資料,但Intel手冊寫得很好很準確。這是一些資料:
《Datasheet for Intel G35 Chipset》描述了一個支援Core 2處理器的有代表性的晶片組。這也是本文的主要資訊來源。
《Datasheet for Intel Core 2 Quad-Core Q6000 Sequence》是一個處理器資料手冊。它記載了處理器上每一個管腳的作用(當你把管腳按功能分組後,其實並不算多)。很棒的資料,雖然對有些位的描述比較含糊。
《Intel Software Developer's Manuals》是傑出的文件。它優美的解釋了體系結構的各個部分,一點也不會讓人感到含糊不清。第一卷和第三卷A部很值得一讀(別被"卷"字嚇倒,每卷都不長,而且您可以選擇性的閱讀)。
Pádraig Brady建議我連結到Ulrich Drepper的一篇關於記憶體的優秀文章。確實是個好東西。我本打算把這個連結放到討論儲存器的文章中的,但此處列出的越多越好啦。
轉: 計算機的引導過程
原文標題:How Computers Boot Up
原文地址:http://duartes.org/gustavo/blog/
[注:本人水平有限,只好挑一些國外高手的精彩文章翻譯一下。一來自己複習,二來與大家分享。]
前一篇文章介紹了Intel計算機的主機板與記憶體對映,從而為本文設定了一個系統引導階段的場景。引導(Booting)是一個複雜的,充滿技巧的,涉及多個階段,又十分有趣的過程。下圖列出了此過程的概要:
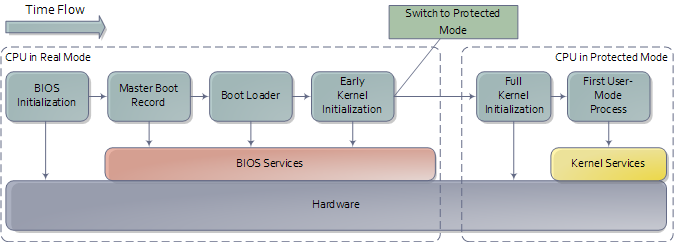
引導過程概要
當 你按下計算機的電源鍵後(現在別按!),機器就開始運轉了。一旦主機板上電,它就會初始化自身的韌體(firmware)——晶片組和其他零零碎碎的東西——並嘗試啟動CPU。如果此時出了什麼問題(比如CPU壞了或根本沒裝),那麼很可能出現的情況是電腦沒有任何動靜,除了風扇在轉。一些主機板會在CPU 故障或缺失時發出鳴音提示,但以我的經驗,此時大多數機器都會處於僵死狀態。一些USB或其他裝置也可能導致機器啟動時僵死。對於那些以前工作正常,突然 出現這種症狀的電腦,一個可能的解決辦法是拔除所有不必要的裝置。你也可以一次只斷開一個裝置,從而發現哪個是罪魁禍首。
如果一切正常,CPU就開始運行了。在一個多處理器或多核處理器的系統中,會有一個CPU被動態的指派為引導處理器(bootstrap processor簡寫BSP),用於執行全部的BIOS和核心初始化程式碼。其餘的處理器,此時被稱為應用處理器(application processor簡寫AP),一直保持停機狀態直到核心明確啟用他們為止。雖然Intel CPU經歷了很多年的發展,但他們一直保持著完全的向後相容性,所以現代的CPU可以表現得跟原先1978年的Intel 8086完全一樣。其實,當CPU上電後,它就是這麼做的。在這個基本的上電過程中,處理器工作於真實模式,分頁功能是無效的。此時的系統環境,就像古老的MS-DOS一樣,只有1MB記憶體可以定址,任何程式碼都可以讀寫任何地址的記憶體,這裡沒有保護或特權級的概念。
CPU上電後,大部分暫存器的都具有定義良好的初始值,包括指令指標暫存器(EIP),它記錄了下一條即將被CPU執行的指令所在的記憶體地址。儘管此時的Intel CPU還只能定址1MB的記憶體,但憑藉一個奇特的技巧,一個隱藏的基地址(其實就是個偏移量)會與EIP相加,其結果指向第一條將被執行的指令所處的地址0xFFFFFFF0(長16位元組,在4GB記憶體空間的尾部,遠高於1MB)。這個特殊的地址叫做復位向量(reset vector),而且是現代Intel CPU的標準。
主機板保證在復位向量處的指令是一個跳轉,而且是跳轉到BIOS執行入口點所在的記憶體對映地址。這個跳轉會順帶清除那個隱藏的、上電時的基地址。感謝晶片組提供的記憶體對映功能,此時的記憶體地址存放著CPU初始化所需的真正內容。這些內容全部是從包含有BIOS的快閃記憶體對映過來的,而此時的RAM模組還只有隨機的垃圾資料。下面的圖例列出了相關的記憶體區域:
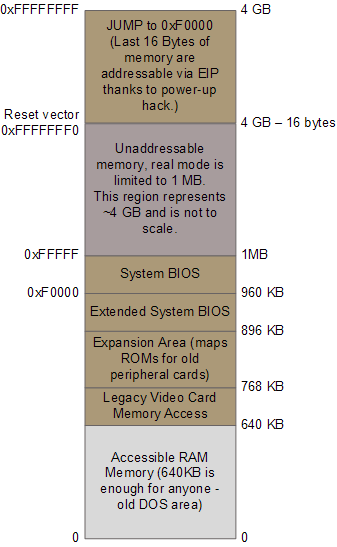
引導時的重要記憶體區域
隨後,CPU開始執行BIOS的程式碼,初始化機器中的一些硬體。之後BIOS開始執行上電自檢過程(POST),檢測計算機中的各種元件。如果找不到一個可用的顯示卡,POST就會失敗,導致BIOS進入停機狀態併發出鳴音提示(因為此時無法在螢幕上輸出提示資訊)。如果顯示卡正常,那麼電腦看起來就真的運轉起來了:顯示一個製造商定製的商標,開始記憶體自檢,天使們大聲的吹響號角。另有一些POST失敗的情況,比如缺少鍵盤,會導致停機,螢幕上顯示出錯資訊。其實POST即是檢測又是初始化,還要枚舉出所有PCI裝置的資源——中斷,記憶體範圍,I/O埠。現代的BIOS會遵循高階配置與電源介面(ACPI)協議,建立一些用於描述裝置的資料表,這些表格將來會被作業系統核心用到。
POST完畢後,BIOS就準備引導作業系統了,它必須存在於某個地方:硬碟,光碟機,軟盤等。BIOS搜尋引導裝置的實際順序是使用者可定製的。如果找不到合適的引導裝置,BIOS會顯示出錯資訊並停機,比如"Non-System Disk or Disk Error"沒有系統盤或驅動器故障。一個壞了的硬碟可能導致此症狀。幸運的是,在這篇文章中,BIOS成功的找到了一個可以正常引導的驅動器。
現在,BIOS會讀取硬碟的第一個扇區(0扇區),內含512個位元組。這些資料叫做主引導記錄(Master Boot Record簡稱MBR)。一般說來,它包含兩個極其重要的部分:一個是位於MBR開頭的作業系統相關的載入程式,另一個是緊跟其後的磁碟分割槽表。BIOS 絲毫不關心這些事情:它只是簡單的載入MBR的內容到記憶體地址0x7C00處,並跳轉到此處開始執行,不管MBR裡的程式碼是什麼。
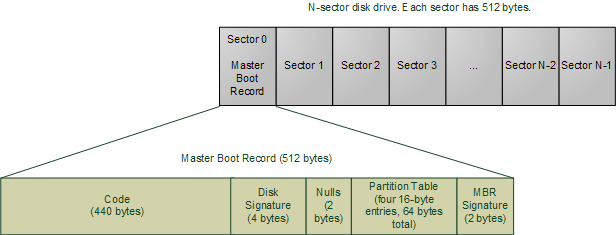
主引導記錄
這段在MBR內的特殊程式碼可能是Windows 引導裝載程式,Linux 引導裝載程式(比如LILO或GRUB),甚至可能是病毒。與此不同,分割槽表則是標準化的:它是一個64位元組的區塊,包含4個16位元組的記錄項,描述磁碟是如何被分割的(所以你可以在一個磁碟上安裝多個作業系統或擁有多個獨立的卷)。傳統上,Microsoft的MBR程式碼會檢視分割槽表,找到一個(唯一的)標記為活動(active)的分割槽,載入那個分割槽的引導扇區(boot sector),並執行其中的程式碼。引導扇區是一個分割槽的第一個扇區,而不是整個磁碟的第一個扇區。如果此時出了什麼問題,你可能會收到如下錯誤資訊:"Invalid Partition Table"無效分割槽表或"Missing Operating System"作業系統缺失。這條資訊不是來自BIOS的,而是由從磁碟載入的MBR程式所給出的。因此這些資訊依賴於MBR的內容。
隨著時間的推移,引導裝載過程已經發展得越來越複雜,越來越靈活。Linux的引導裝載程式Lilo和GRUB可以處理很多種類的作業系統,檔案系統,以及引導配置資訊。他們的MBR程式碼不再需要效仿上述"從活動分割槽來引導"的方法。但是從功能上講,這個過程大致如下:
1、 MBR本身包含有第一階段的引導裝載程式。GRUB稱之為階段一。
2、 由於MBR很小,其中的程式碼僅僅用於從磁碟載入另一個含有額外的引導程式碼的扇區。此扇區可能是某個分割槽的引導扇區,但也可能是一個被硬編碼到MBR中的扇區位置。
3、 MBR配合第2步所載入的程式碼去讀取一個檔案,其中包含了下一階段所需的載入程式。這在GRUB中是"階段二"載入程式,在Windows Server中是C:/NTLDR。如果第2步失敗了,在Windows中你會收到錯誤資訊,比如"NTLDR is missing"NTLDR缺失。階段二的程式碼進一步讀取一個引導配置檔案(比如在GRUB中是grub.conf,在Windows中是boot.ini)。之後要麼給使用者顯示一些引導選項,要麼直接去引導系統。
4、 此時,引導裝載程式需要啟動作業系統核心。它必須擁有足夠的關於檔案系統的資訊,以便從引導分割槽中讀取核心。在Linux中,這意味著讀取一個名字類似"vmlinuz-2.6.22-14-server"的含有核心映象的檔案,將之載入到記憶體並跳轉去執行核心引導程式碼。在Windows Server 2003中,一部份核心啟動程式碼是與核心映象本身分離的,事實上是嵌入到了NTLDR當中。在完成一些初始化工作以後,NTDLR從"c:/Windows/System32/ntoskrnl.exe"檔案載入核心映象,就像GRUB所做的那樣,跳轉到核心的入口點去執行。
這裡還有一個複雜的地方值得一提(這也是我說引導富於技巧性的原因)。當前Linux核心的映象就算被壓縮了,在真實模式下,也沒法塞進640KB的可用RAM裡。我的vanilla Ubuntu核心壓縮後有1.7MB。然而,引導裝載程式必須運行於真實模式,以便呼叫BIOS程式碼去讀取磁碟,所以此時核心肯定是沒法用的。解決之道是使用一種倍受推崇的"虛模式"。它並非一個真正的處理器執行模式(希望Intel的工程師允許我以此作樂),而是一個特殊技巧。程式不斷的在真實模式和保護模式之間切換,以便訪問高於1MB的記憶體同時還能使用BIOS。如果你閱讀了GRUB的原始碼,你就會發現這些切換到處都是(看看stage2/目錄下的程式,對real_to_prot 和 prot_to_real函式的呼叫)。在這個棘手的過程結束時,裝載程式終於千方百計的把整個核心都塞到記憶體裡了,但在這後,處理器仍保持在真實模式執行。
至此,我們來到了從"引導裝載"跳轉到"早期的核心初始化"的時刻,就像第一張圖中所指示的那樣。在系統做完熱身運動後,核心會展開並讓系統開始運轉。下一篇文章將帶大家一步步深入Linux核心的初始化過程,讀者還可以參考Linux Cross reference的資源。我沒辦法對Windows也這麼做,但我會把要點指出來。
參考:
http://blog.csdn.net/drshenlei/article/details/4250306轉: 核心引導過程
原文標題:The Kernel Boot Process
原文地址:http://duartes.org/gustavo/blog/
[注:本人水平有限,只好挑一些國外高手的精彩文章翻譯一下。一來自己複習,二來與大家分享。]
上一篇文章解釋了計算機的引導過程,正好講到引導裝載程式把系統核心映象塞進記憶體,準備跳轉到核心入口點去執行的時刻。作為引導啟動系列文章的最後一篇,就讓我們深入核心,去看看作業系統是怎麼啟動的吧。由於我習慣以事實為依據討論問題,所以文中會出現大量的連結引用Linux 核心2.6.25.6版的原始碼(源自Linux Cross Reference)。如果你熟悉C的 語法,這些程式碼就會非常容易讀懂;即使你忽略一些細節,仍能大致明白程式都幹了些什麼。最主要的障礙在於對一些程式碼的理解需要相關的背景知識,比如機器的 底層特性或什麼時候、為什麼它會執行。我希望能儘量給讀者提供一些背景知識。為了保持簡潔,許多有趣的東西,比如中斷和記憶體,文中只能點到為止了。在本文 的最後列出了Windows的引導過程的要點。
當Intel x86的載入程式執行到此刻時,處理器處於真實模式(可以定址1MB的記憶體),(針對現代的Linux系統)RAM的內容大致如下:
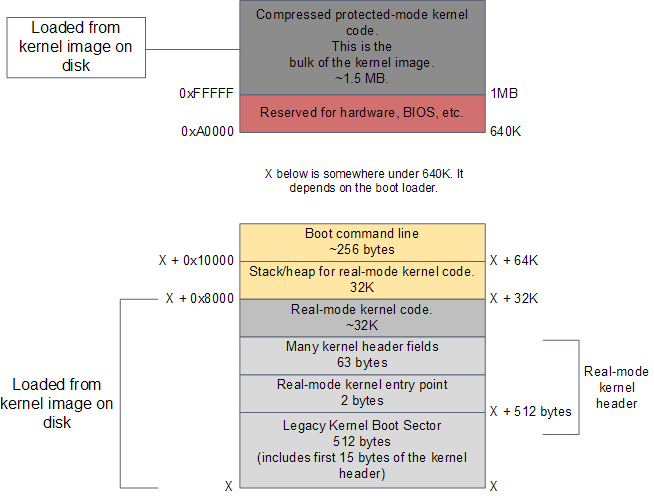
引導裝載完成後的RAM內容
引導裝載程式通過BIOS的磁碟I/O服務,已經把核心映象載入到記憶體當中。這個映象只是硬碟中核心檔案(比如/boot/vmlinuz-2.6.22-14-server)的一份完全相同的拷貝。映象分為兩個部分:一個較小的部分,包含真實模式的核心程式碼,被載入到640KB記憶體邊界以下;另一部分是一大塊核心,執行在保護模式,被載入到低端1MB記憶體地址以上。
如上圖所示,之後的事情發生在真實模式核心的頭部(kernel header)。這段記憶體區域用於實現引導裝載程式與核心之間的Linux引導協議。 此處的一些資料會被引導裝載程式讀取。這些資料包括一些令人愉快的資訊,比如包含核心版本號的可讀字串,也包括一些關鍵資訊,比如真實模式核心程式碼的大 小。引導裝載程式還會向這個區域寫入資料,比如使用者選中的引導選單項對應的命令列引數所在的記憶體地址。之後就到了跳轉到核心入口點的時刻。下圖顯示了核心 初始化程式碼的執行順序,包括原始碼的目錄、檔案和行號:
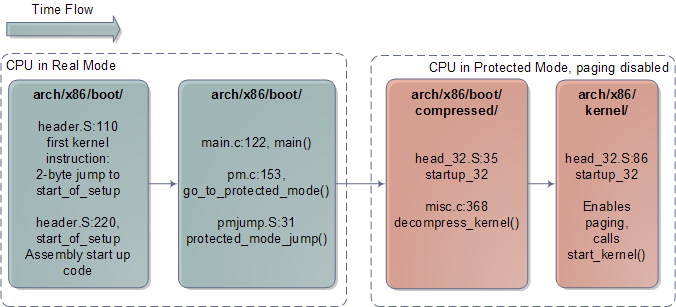
與體系結構相關的Linux核心初始化過程
對於Intel體系結構,核心啟動前期會執行arch/x86/boot/header.S檔案中的程式。它是用匯編語言書寫的。一般說來彙編程式碼在核心中很少出現,但常見於引導程式碼。這個檔案的開頭實際上包含了引導扇區程式碼。早期的Linux不需要引導裝載程式就可以工作,這段程式碼是從那個時候留傳下來的。現今,如果這個引導扇區被執行,它僅僅給使用者輸出一個"bugger_off_msg"之後就會重啟系統。現代的引導裝載程式會忽略這段遺留程式碼。在引導扇區程式碼之後,我們會看到真實模式核心頭部(kernel header)最開始的15位元組;這兩部分合起來是512位元組,正好是Intel硬體平臺上一個典型的磁碟扇區的大小。
在這512位元組之後,偏移量0x200處,我們會發現Linux核心的第一條指令,也就是真實模式核心的入口點。具體的說,它在header.S:110,是一個2位元組的跳轉指令,直接寫成了機器碼的形式0x3AEB。你可以通過對核心映象執行hexdump,並檢視偏移量0x200處的內容來驗證這一點——這僅僅是一個對神志清醒程度的檢查,以確保這一切並不是在做夢。引導裝載程式執行完畢時就會跳轉執行這個位置的指令,進而跳轉到header.S:229執行一個普通的用匯編寫成的子程式,叫做start_of_setup。這個短小的子程式初始化棧空間(stack),把真實模式核心的bss段清零(這個區域包含靜態變數,所以用0來初始化它們),之後跳轉執行一段又老又好的C語言程式:arch/x86/boot/main.c:122。
main()會處理一些登記工作(比如檢測記憶體佈局),設定顯示模式等。然後它會呼叫go_to_protected_mode()。然而,在把CPU置於保護模式之前,還有一些工作必須完成。有兩個主要問題:中斷和記憶體。在真實模式中,處理器的中斷向量表總是從記憶體的0地址開始的,然而在保護模式中,這個中斷向量表的位置是儲存在一個叫IDTR的CPU暫存器當中的。與此同時,從邏輯記憶體地址(在程式中使用)到線性記憶體地址(一個從0連續編號到記憶體頂端的數值)的翻譯方法在真實模式和保護模式中是不同的。保護模式需要一個叫做GDTR的暫存器來存放記憶體全域性描述符表的地址。所以go_to_protected_mode()呼叫了setup_idt() 和 setup_gdt(),用於裝載臨時的中斷描述符表和全域性描述符表。
現在我們可以轉入保護模式啦,這是由另一段彙編子程式protected_mode_jump來完成的。這個子程式通過設定CPU的CR0暫存器的PE位來使能保護模式。此時,分頁功能還處於關閉狀態;分頁是處理器的一個可選的功能,即使運行於保護模式也並非必要。真正重要的是,我們不再受制於640K的記憶體邊界,現在可以定址高達4GB的RAM了。這個子程式進而呼叫壓縮狀態核心的32位核心入口點startup_32。startup32會做一些簡單的暫存器初始化工作,並呼叫一個C語言編寫的函式decompress_kernel(),用於實際的解壓縮工作。
decompress_kernel()會列印一條大家熟悉的資訊"Decompressing Linux…"(正在解壓縮Linux)。解壓縮過程是原地進行的,一旦完成核心映象的解壓縮,第一張圖中所示的壓縮核心映象就會被覆蓋掉。因此解壓後的核心也是從1MB位置開始的。之後,decompress_kernel()會顯示"done"(完成)和令人振奮的"Booting the kernel"(正在引導核心)。這裡"Booting"的意思是跳轉到整個故事的最後一個入口點,也是保護模式核心的入口點,位於RAM的第二個1MB開始處(偏移量0x100000,此值是由芬蘭Halti山巔之上的神靈授意給Linus的)。在這個神聖的位置含有一個子程式呼叫,名叫…呃…startup_32。但你會發現這一位是在另一個目錄中的。
這位startup_32的第二個化身也是一個彙編子程式,但它包含了32位模式的初始化過程:
1、 它清理了保護模式核心的bss段。(這回是真正的核心了,它會一直執行,直到機器重啟或關機。)
2、 為記憶體建立最終的全域性描述符表。
3、 建立頁表以便可以開啟分頁功能。
4、 使能分頁功能。
5、 初始化棧空間。
6、 建立最終的中斷描述符表。
7、 最後,跳轉執行一個體繫結構無關的核心啟動函式:start_kernel()。
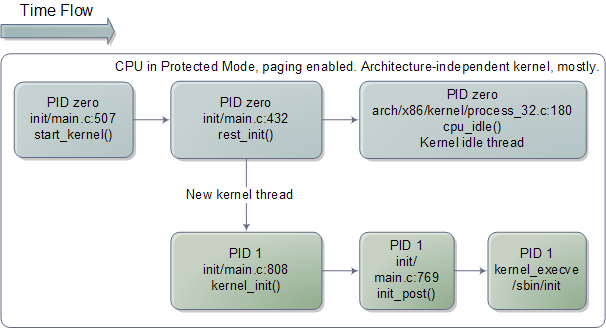
下圖顯示了引導最後一步的程式碼執行流程:
與體系結構無關的Linux核心初始化過程
start_kernel()看起來更像典型的核心程式碼,幾乎全用C語言編寫而且與特定機器無關。這個函式呼叫了一長串的函式,用來初始化各個核心子系統和資料結構,包括排程器(scheduler),記憶體分割槽(memory zones),計時器(time keeping)等等。之後,start_kernel()呼叫rest_init(),此時幾乎所有的東西都可以工作了。rest_init()會建立一個核心執行緒,並以另一個函式kernel_init()作為此執行緒的入口點。之後,rest_init()會呼叫schedule()來啟用任務排程功能,然後呼叫cpu_idle()使自己進入睡眠(sleep)狀態,成為Linux核心中的一個空閒執行緒(idle thread)。cpu_idle()會在0號程序(process zero)中永遠的執行下去。一旦有什麼事情可做,比如有了一個活動就緒的程序(runnable process),0號程序就會啟用CPU去執行這個任務,直到沒有活動就緒的程序後才返回。
但是,還有一個小麻煩需要處理。我們跟隨引導過程一路走下來,這個漫長的執行緒以一個空閒迴圈(idle loop)作為結尾。處理器上電執行第一條跳轉指令以後,一路執行,最終會到達此處。從復位向量(reset vector)->BIOS->MBR->引導裝載程式->真實模式核心->保護模式核心,跳轉跳轉再跳轉,經過所有這些雜七雜八的步驟,最後來到引導處理器(boot processor)中的空閒迴圈cpu_idle()。看起來真的很酷。然而,這並非故事的全部,否則計算機就不會工作。
在這個時候,前面啟動的那個核心執行緒已經準備就緒,可以取代0號程序和它的空閒執行緒了。事實也是如此,就發生在kernel_init()開始執行的時刻(此函式之前被作為執行緒的入口點)。kernel_init()的職責是初始化系統中其餘的CPU,這些CPU從引導過程開始到現在,還一直處於停機狀態。之前我們看過的所有程式碼都是在一個單獨的CPU上執行的,它叫做引導處理器(boot processor)。當其他CPU——稱作應用處理器(application processor)——啟動以後,它們是處於真實模式的,必須通過一些初始化步驟才能進入保護模式。大部分的程式碼過程都是相同的,你可以參考startup_32,但對於應用處理器,還是有些細微的不同。最終,kernel_init()會呼叫init_post(),後者會嘗試啟動一個使用者模式(user-mode)的程序,嘗試的順序為:/sbin/init,/etc/init,/bin/init,/bin/sh。如果都不行,核心就會報錯。幸運的是init經常就在這些地方的,於是1號程序(PID 1)就開始運行了。它會根據對應的配置檔案來決定啟動哪些程序,這可能包括X11 Windows,控制檯登陸程式,網路後臺程式等。從而結束了引導程序,同時另一個Linux程式開始在某處執行。至此,讓我祝福您的電腦可以一直正常執行下去,不出毛病。
在同樣的體系結構下,Windows的啟動過程與Linux有很多相似之處。它也面臨同樣的問題,也必須完成類似的初始化過程。當引導過程開始後,一個最大的不同是,Windows把全部的真實模式核心程式碼以及一部分初始的保護模式程式碼都打包到了引導載入程式(C:/NTLDR)當中。因此,Windows使用的二進位制映象檔案就不一樣了,核心映象中沒有包含兩個部分的程式碼。另外,Linux把引導裝載程式與核心完全分離,在某種程度上自動的形成不同的開源專案。下圖顯示了Windows核心主要的啟動過程:
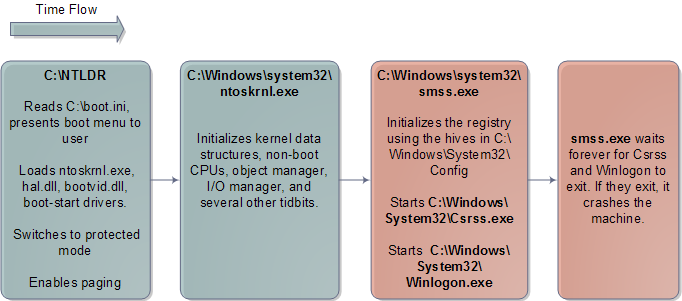
Windows核心初始化過程
自然而然的,Windows使用者模式的啟動就非常不同了。沒有/sbin/init程式,而是執行Csrss.exe和Winlogon.exe。Winlogon會啟動Services.exe(它會啟動所有的Windows服務程式)、Lsass.exe和本地安全認證子系統。經典的Windows登陸對話方塊就是執行在Winlogon的上下文中的。
本文是引導啟動系列話題的最後一篇。感謝每一位讀者,感謝你們的反饋。我很抱歉,有些內容只能點到為止;我打算把它們留在其他文章中深入討論,並儘量保持文章的長度適合blog的風格。下次我打算定期的撰寫關於"Software Illustrated"的文章,就像本系列一樣。最後,給大家一些參考資料:
最好也最重要的資料是實際的核心程式碼,Linux或BSD的都成。
Intel出版的傑出的軟體開發人員手冊,你可以免費下載到。
《理解Linux核心》是本好書,其中討論了大量的Linux核心程式碼。這書也許有點過時有點枯燥,但我還是將它推薦給那些想要與核心心意相通的人們。《Linux裝置驅動程式》讀起來會有趣得多,講的也不錯,但是涉及的內容有些侷限性。最後,網友Patrick Moroney推薦Robert Love所寫的《Linux核心開發》,我曾聽過一些對此書的正面評價,所以還是值得列出來的。
對於Windows,目前最好的參考書是《Windows Internals》,作者是David Solomon和Mark Russinovich,後者是Sysinternals的知名專家。這是本特棒的書,寫的很好而且講解全面。主要的缺點是缺少原始碼的支援。
參考:
http://blog.csdn.net/drshenlei/article/details/4253179轉: 記憶體地址轉換與分段
原文標題:Memory Translation and Segmentation
原文地址:http://duartes.org/gustavo/blog/
[注:本人水平有限,只好挑一些國外高手的精彩文章翻譯一下。一來自己複習,二來與大家分享。]
本文是Intel相容計算機(x86)的記憶體與保護系列文章的第一篇,延續了啟動引導系列文章的主題,進一步分析作業系統核心的工作流程。與以前一樣,我將引用Linux核心的原始碼,但對Windows只給出示例(抱歉,我忽略了BSD,Mac等系統,但大部分的討論對它們一樣適用)。文中如果有錯誤,請不吝賜教。
在支援Intel的主機板晶片組上,CPU對記憶體的訪問是通過連線著CPU和北橋晶片的前端匯流排來完成的。在前端總線上傳輸的記憶體地址都是實體記憶體地址,編號從0開始一直到可用實體記憶體的最高階。這些數字被