
centos7系統單機安裝部署hadoop2.6.5
今天單機安裝部署Hadoop,就順便記錄一下安裝過程
1 首先需要下載jdk和hadoop的安裝包
我安裝的版本是Hadoop-2.6.5.tar.gz(注意不要下載成hadoop-2.6.5-src.tar.gz)和jdk-8u162-linux-x64.tar.gz
2 安裝jdk
檢查並解除安裝OpenJDK
第一步檢查系統是否自帶了OpenJDK以及相關安裝包,如果有的話則應先將其解除安裝。
檢查命令:
- java -version(檢視版本,使用這個命令就可以)
- 或
- rpm -qa | grep java(檢視所有安裝的軟體包中帶有Java的)
如果發現有安裝好的OpenJDK以及安裝包的話那麼首先依次執行解除安裝。
解除安裝命令:
- yum -y remove ...(省略號為java安裝包名稱)
- 或
- rpm -e -–nodeps tzdata-java-2012c-1.el6.noarch
- rpm -e -–nodeps java-1.6.0-openjdk-1.6.0.0-1.45.1.11.1.el6.x86_64(務必注意–nodeps前的兩個橫槓)
現在便可以進行安裝
1)將jdk-8u162-linux-x64.tar.gz移動到了home資料夾下解壓,並將其重新命名為Java
2)配置環境變數
使配置檔案生效:source /etc/profile#set java environment export JAVA_HOME=/usr/java/jdk1.8.0_162 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH
輸入java -version看是否安裝成功

如上圖所示正常顯示了jdk版本,到此為止就已經安裝成功了。
3 安裝hadoop
1)將Hadoop-2.6.5.tar.gz移到home資料夾下解壓,並重命名為hadoop
2)配置hadoop
a.修改/usr/hadoop/etc/hadoop/hadoop-env.sh 檔案的java環境,將java安裝路徑加進去
export JAVA_HOME=/usr/java/jdk1.8.0_162b.配置hadoop環境變數
export HADOOP_HOME=/usr/hadoop/export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
使用source /etc/profile使更改後的配置檔案生效
c.修改/usr/hadoop/etc/hadoop/core-site.xml 檔案
<configuration>
<!-- 指定HDFS老大(namenode)的通訊地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!-- 指定hadoop執行時產生檔案的儲存路徑 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
</property>
</configuration>d.修改/usr/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/usr/hadoop/hdfs/name</value>
<description>namenode上儲存hdfs名字空間元資料 </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/hadoop/hdfs/data</value>
<description>datanode上資料塊的物理儲存位置</description>
</property>
<!-- 設定hdfs副本數量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration> e.ssh免密登入
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys f.hdfs啟動與停止
第一次啟動hdfs需要格式化
在hadoop資料夾下執行 ./bin/hdfs namenode -format命令進行格式化
hdfs啟動:start-dfs.sh hdfs停止命令:stop-dfs.sh
若在啟動hdfs時出現Unable to load native-hadoop library for your platform...提示hadoop不能載入本地庫。
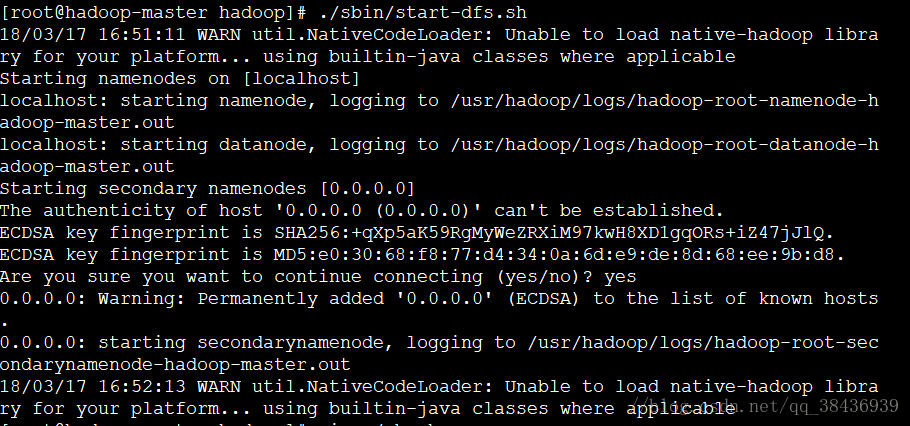
若程式和作業系統都是64位的,那也許就是少了些配置,試試下面的方法:
首先在bashrc中加入如下配置:
vim ~/.bashrc
配置如下
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_HOME=/home/hadoop/
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"使上面配置生效:source ~/.bashrc
再去執行啟動dfs/yarn,成功解決了我的問題
g.瀏覽器輸入:http://192.168.136.140:50070 (IP為自己系統的地址)

h.接下來配置yarn檔案
配置/usr/hadoop/etc/hadoop/mapred-site.xml 。這裡注意一下,hadoop裡面預設是mapred-site.xml.template 檔案,如果配置yarn,把mapred-site.xml.template 重新命名為mapred-site.xml 。
mv mapred-site.xml.template mapred-site.xml 配置mapred-site.xml檔案
<configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>配置/usr/hadoop//etc/hadoop/yarn-site.xml檔案
<configuration>
<!-- reducer取資料的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration> 啟動yarn :start-yarn.sh 停止yarn:stop-yarn.sh

i.驗證Hadoop安裝
瀏覽器輸入http://192.168.136.140:8088 (8088是預設埠)
可以用jps命令檢視啟動了什麼程序:
