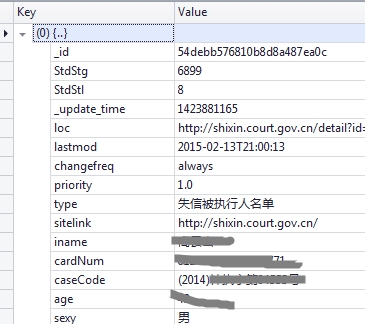
抓取網路json資料並存入mongodb(1)
阿新 • • 發佈:2019-01-23
我們在百度中搜索http://shixin.court.gov.cn/ ,會有一個內嵌的查詢頁面:
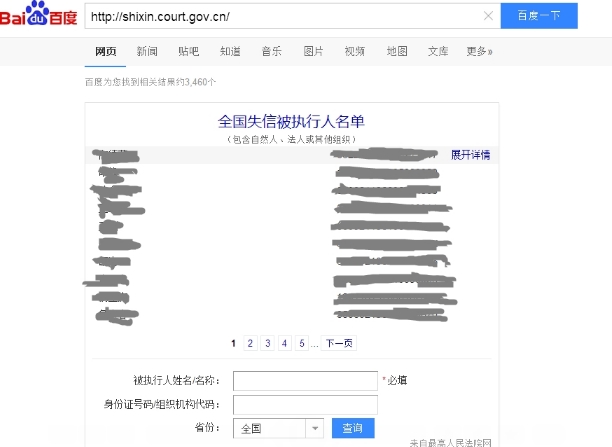
這個是通過ajax技術載入的,因為是js渲染,所以頁面原始碼中並不包含這些資訊。
通過Firefox的Firebug監視網路請求,發現是向百度opendata請求的,結果返回一個包含100條資料的json
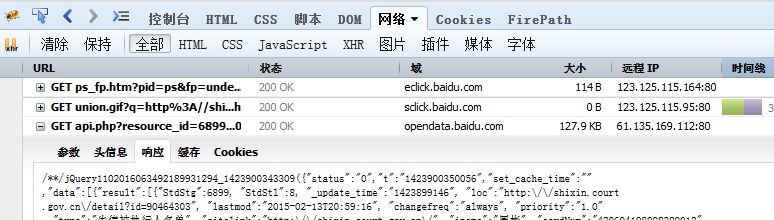
這樣,通過分析請求字串的引數,自定義請求,可以通過爬蟲直接爬取的資料。
有了資料之後需要解析,每次請求會返回100條資料,現在需要把這100條資料全部解除出來並存入Mongodb資料庫中。
爬蟲使用webmagic:https://github.com/code4craft/webmagic
資料庫Mongodb驅動使用 https://github.com/mongodb/mongo-java-driver
maven座標:
<dependencies> <dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-extension</artifactId> <version>0.5.2</version> </dependency> <dependency> <groupId>org.mongodb</groupId> <artifactId>mongo-java-driver</artifactId> <version>2.7.3</version> </dependency> </dependencies>
webmagic爬蟲框架使用參考:http://webmagic.io/docs/zh/
我在爬取時候自定義了PageProcessor,在這裡將資料解析並存入Mongodb,並且使用了爬蟲框架自帶的FilePipeline將資料持久化到磁碟檔案。
每次請求返回的是100條資料,需要通過分析,將這100條分離成一個個獨立的json字串,然後一條條插入。
插入資料的時候,還要判斷資料是否重複。
json格式字串可以直接存入資料庫。
json字串存入mongodb資料庫:Mongo mongo = new Mongo(); DB db = mongo.getDB("shixinTest"); DBCollection q=db.getCollection("shixinTest1"); // new BasicDBObject(); // 通過JSON.parse構造DBObject DBObject query = (BasicDBObject) JSON.parse(JsonString) q.save(query);