
用Python處理HTML轉義字元的5種方式
阿新 • • 發佈:2019-01-23
寫爬蟲是一個傳送請求,提取資料,清洗資料,儲存資料的過程。在這個過程中,不同的資料來源返回的資料格式各不相同,有 JSON 格式,有 XML 文件,不過大部分還是 HTML 文件,HTML 經常會混雜有轉移字元,這些字元我們需要把它轉義成真正的字元。
什麼是轉義字元
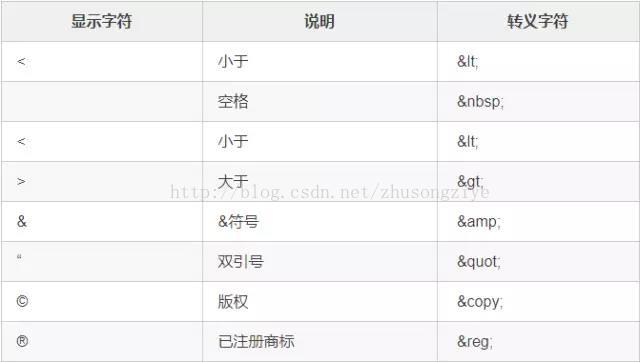
在 HTML 中 <、>、& 等字元有特殊含義(<,>
用於標籤中,& 用於轉義),他們不能在 HTML 程式碼中直接使用,如果要在網頁中顯示這些符號,就需要使用 HTML 的轉義字串(Escape Sequence),例如 < 的轉義字元是 <,瀏覽器渲染
HTML 頁面時,會自動把轉移字串換成真實字元。
轉義字元(Escape Sequence)由三部分組成:第一部分是一個 & 符號,第二部分是實體(Entity)名字,第三部分是一個分號。 比如,要顯示小於號(<),就可以寫< 。
Python 反轉義字串
用 Python 來處理轉義字串有多種方式,而且 py2 和 py3 中處理方式不一樣,在 python2 中,反轉義串的模組是 HTMLParser。
# python2
import HTMLParser
>>> HTMLParser().unescape('a=1&b=2')
'a=1&b=2'
Python3 把 HTMLParser 模組遷移到 html.parser
# python3
>>> from html.parser import HTMLParser
>>> HTMLParser().unescape('a=1&b=2')
'a=1&b=2'到 python3.4 之後的版本,在 html 模組新增了 unescape 方法。
# python3.4
>>> import html
>>> html.unescape('a=1&b=2')
'a=1&b=2'推薦最後一種寫法,因為 HTMLParser.unescape 方法在 Python3.4 就已經被廢棄掉不推薦使用,意味著之後的版本有可能會被徹底移除。
另外,sax 模組也有支援反轉義的函式
>>> from xml.sax.saxutils import unescape
>>> unescape('a=1&b=2')
'a=1&b=2'當然,你完全可以實現自己的反轉義功能,不復雜,當然,我們崇尚不重複造輪子。