
(一)由淺入深java集合--HashMap原理
轉自:
HashMap所在Java集合的位置如下圖所示
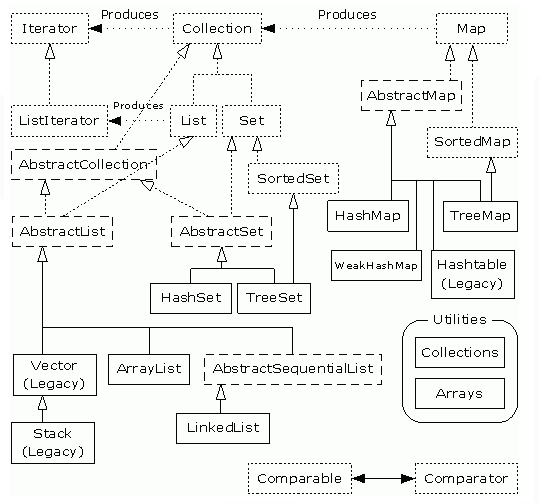
1 、大致介紹一下java的集合體繫結構
List Set Map是這個集合體系中最主要的三個介面。
List、Set繼承自Collection介面。
Set不允許元素重複。HashSet和TreeSet是兩個主要的實現類。
List有序且允許元素重複。ArrayList、LinkedList和Vector是三個主要的實現類。
Map也屬於集合系統,但和Collection介面不同,AbstractMap實現了Map介面,HashMap繼承AbstractMap。SortedMap繼承Map介面,TreeMap繼承SortedMap。從圖中我們可知。
Map是key對value的對映集合,其中key是一個集合,key不能重複,但是value可以重複。HashMap、TreeMap和HashTable是三個主要實現類。
大概介紹了一下java的集合類,接下來主要介紹的是HashMap,HashMap在java集合類中的位置在圖中能看到。
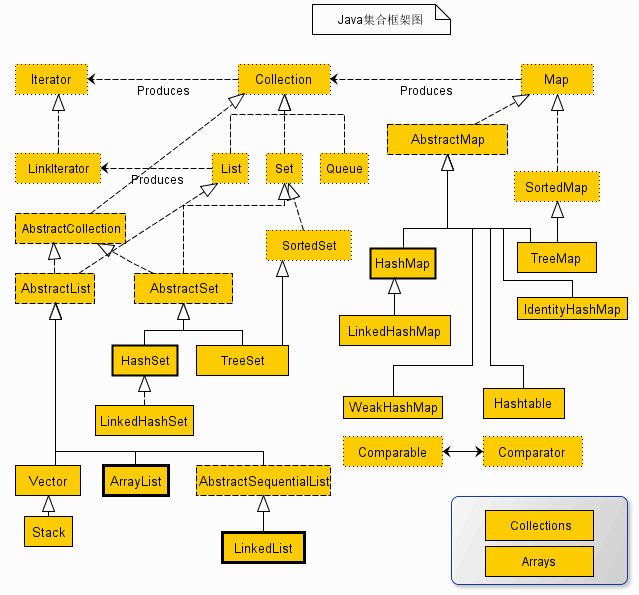
2、HashMap位置
HashMap 繼承了AbstractMap,AbstractMap實現了Map介面,LinkedHashMap繼承了HashMap。
3、 什麼時候使用HashMap?
當你需要通過一個名字來獲取資料的時候就可以用Map,並且這個名字(也就是key)是不重複的,且在新增和刪除等情況下不需要執行緒安全,這時候我們就可以用HashMap。
比如當把使用者的資訊存入list的時候,當你根據使用者id查詢某某學生名字時,可能需要遍歷,這時候用Map,直接通過key來找到value就可以了。
總之,需要鍵值對的時候,用map就可以了。
4 、HashMap使用code
5、 HashMap概述
HashMap 是基於雜湊表的Map介面的非同步實現。此實現提供所有可選的對映操作,並允許使用null值和null鍵。此類不保證對映的順序,特別不保證該順序恆久不變。(我們可以執行demo中的方法,插入順序和輸出順序並不是一個順序。)
6、 HashMap資料結構
在java程式語言中,最基本的結構就是兩種,一個是陣列,另外一個是模擬指標(引用)。HashMap實際上是一個“連結串列雜湊”的
一維陣列

連結串列
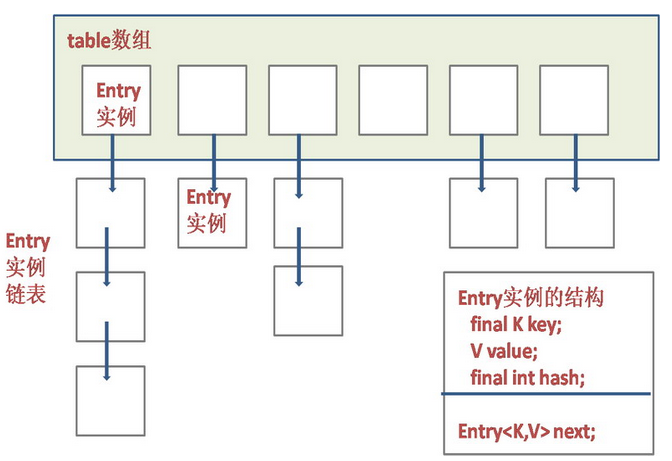
所以HashMap結構如下圖
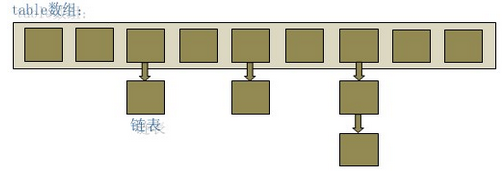
所以HashMap底層就是一個數組結構,陣列中的每一項又是存放的連結串列的頭結點。當新建一個HashMap的時候,就會初始化一個數組。
當new一個HashMap,內部程式碼如下所示:
對於任何一個數組,在初始化建立的時候,都會涉及到建立陣列的大小,陣列長度是否夠用?能否自動擴充陣列容量呢?這些問題。
下面是初始化陣列時的一下引數定義code
[java] view plain copy print?- /**
- * The defaultinitial capacity - MUST be a power of two.
- */
- static final int DEFAULT_INITIAL_CAPACITY = 16;// 預設初始容量為16,必須為2的冪
- /**
- * The maximumcapacity, used if a higher value is implicitly specified
- * by either of the constructors with arguments.
- * MUST be apower of two <= 1<<30.
- */
- static final int MAXIMUM_CAPACITY = 1 << 30;// 最大容量為2的30次方
- /**
- * The loadfactor used when none specified in constructor.
- */
- static final floatDEFAULT_LOAD_FACTOR = 0.75f;// 預設載入因子0.75
- /**
- * The table,resized as necessary. Length MUST Always be a power oftwo.
- */
- transientEntry<K,V>[] table;// Entry陣列,雜湊表,長度必須為2的冪
- /**
- * The number ofkey-value mappings contained in this map.
- */
- transient int size;// 已存元素的個數
- /**
- * The next sizevalue at which to resize (capacity * load factor).
- * @serial
- */
- int threshold;// 下次擴容的臨界值,size>=threshold就會擴容
- /**
- * The loadfactor for the hash table.
- *
- * @serial
- */
- final float loadFactor;// 載入因子
在newHashMap的時候,構造方法如下:
|
構造方法摘要 |
|
|
HashMap() 構造一個具有預設初始容量 (16) 和預設載入因子 (0.75) 的空 HashMap。 |
|
|
HashMap(int initialCapacity) 構造一個帶指定初始容量和預設載入因子 (0.75)的空 HashMap。 |
|
|
HashMap(int initialCapacity, float loadFactor) 構造一個帶指定初始容量和載入因子的空 HashMap。 |
|
|
HashMap(Map<?extendsK,? extendsV> m) 構造一個對映關係與指定 Map 相同的 HashMap。 |
|
我們常用的沒有引數的構造方法,程式碼如下。
//構造一個具有預設初始容量 (16)和預設載入因子 (0.75) 的空 HashMap。
[java] view plain copy print?- public HashMap() {
- this.loadFactor = DEFAULT_LOAD_FACTOR;
- threshold = (int)(DEFAULT_INITIAL_CAPACITY* DEFAULT_LOAD_FACTOR);
- table = new Entry[DEFAULT_INITIAL_CAPACITY];
- init();
- }
table為Entry陣列,怎麼理解這個Entry?map為地圖,Entry可以理解為地圖中的各個節點,登記處。在new一個HashMap的時候,預設會初始化16個Entry,載入因子是,當陣列中的個數超出了載入因子與當前容量的乘積時,就會通過呼叫rehash方法將容量翻倍。例如預設的擴容因子為0.75, 則擴充的臨界值為16* 0.75 = 12, 也就是map中存放超過12個key value對映時,就會自動擴容。
7 、HashMap初始化之後
new完一個HashMap後,進行put值,put的程式碼如下:
//在此對映中關聯指定值與指定鍵。如果該對映以前包含了一個該鍵的對映關係,則舊值被替換,並返回舊值。
[java] view plain copy print?- public V put(K key, V value) {
- // 如果key為null使用putForNullKey來獲取
- if (key == null)
- return putForNullKey(value);
- // 使用hash函式預處理hashCode
- int hash = hash(key.hashCode());
- // 獲取對應的索引
- int i = indexFor(hash, table.length);
- // 得到對應的hash值的桶,如果這個桶不是,就通過next獲取下一個桶
- for (Entry<K,V> e = table[i]; e != null;e = e.next) {
- Object k;
- // 如果hash相同並且key相同
- if (e.hash== hash && ((k = e.key) == key || key.equals(k))) {
- // 獲取當前的value
- V oldValue = e.value;
- // 將要儲存的value存進去
- e.value = value;
- e.recordAccess(this);
- // 返回舊的value
- return oldValue;
- }
- }
- modCount++;
- addEntry(hash, key, value, i);
- return null;
- }
// key為null怎麼放value
[java] view plain copy print?- private V putForNullKey(V value) {
- // 遍歷table[0]的所有桶
- for (Entry<K,V> e = table[0]; e != null;e = e.next) {
- // 如果key是null
- if (e.key== null) {
- // 取出oldValue,並存入value
- V oldValue = e.value;
- e.value = value;
- e.recordAccess(this);
- // 返回oldValue
- return oldValue;
- }
- }
- modCount++;
- addEntry(0, null, value, 0);
- return null;
- }
//預處理hash值,避免較差的離散hash序列,導致桶沒有充分利用
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>>4);
}
//返回對應hash值得索引 ,h為key的hashCode處理後的值,length為table中Entry陣列大小。
[java] view plain copy print?- static int indexFor(int h, int length) {
- /*****************
- * 由於length是2的n次冪,所以h &(length-1)相當於h % length。
- * 對於length,其2進製表示為1000...0,那麼length-1為0111...1。
- * 那麼對於任何小於length的數h,該式結果都是其本身h。
- * 對於h = length,該式結果等於0。
- * 對於大於length的數h,則和0111...1位與運算後,
- * 比0111...1高或者長度相同的位都變成0,
- * 相當於減去j個length,該式結果是h-j*length,
- * 所以相當於h % length。
- * 其中一個很常用的特例就是h & 1相當於h % 2。
- * 這也是為什麼length只能是2的n次冪的原因,為了優化。
- */
- return h & (length-1);
- }
8、瞭解HashMap其他建構函式的原始碼
我們可以看到,我們在put的時候,先根據key的hashCode重新計算hash值,根據hash值得到這個元素在陣列中的位置(方法 indexFor),如果陣列中的位置上已經有其他元素了,那麼這個元素將以連結串列的形式存放,在連結串列頭中加入新的,最先put的key的value 放在鏈尾。如果該陣列位置上沒有元素,則直接將該元素放到改位置上。
9、 一些其他疑問
9.1、對於,put key為null的值呢?
如果key為null的時候,方法putForNullKey告訴我們答案。
key為null的時候,value也可以不為null。不過在 addEntry(0, null, value, 0);的時候,存放的hash值,以及陣列的下標值為0,key值為null。
如下圖所示,每一行連結串列中,Entry的key是一個。Entry中有key和value ,以及連結串列連線指向。
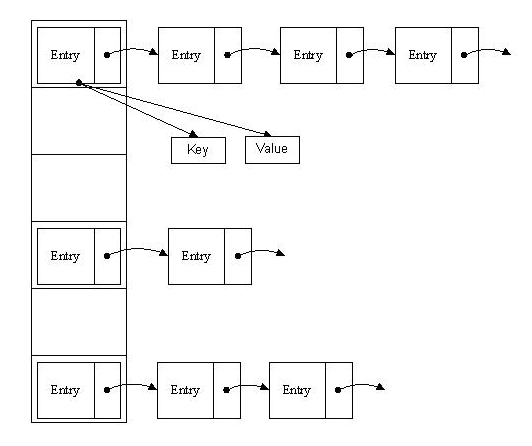
9.2、 有人會問到底啥事hashCode?
其實就是經過一系列的數學運算,移位運算得到一個數,就成為了hashCode。不解釋,看原始碼哦.
9.3、 Entry的陣列的大小,也就是table的大小,為什麼必須是2的冪次方?
HashMap的結構是陣列+單鏈表結構,我們希望元素是均勻分配的,最理想的效果是,Entry中的每個位置都只有應元素,也就是連結串列的頭結點,就是連結串列的尾節點,這樣查詢效率最高,不需要遍歷連結串列,有而不需要進行equals比較key,而且利用率最大 ,%取模運算 雜湊值%table容量=陣列下標,而程式碼中這樣實現的h & (length-1),當length總是2的n次方時,h &(length-1)運算等價於對length取模,也就是h%length,但是&比%的效率要高。
9.4、 HashMap執行緒不安全,那多執行緒下使用如何做呢?
1包裝一下
2 Map m =Collections.synchronizedMap(newHashMap(...));
3使用java.util.HashTable,效率最低
4使用java.util.concurrent.ConcurrentHashMap,相對安全,效率較高
接下來一一說明Map介面的其他實現 。
總結
從如何使用上,key value對映時,HashMap的原理上,一維陣列+單鏈表結構,大概瞭解了他,總之,追本溯源,很好的瞭解他,才能很好的控制他。