
Log4J,在踩坑中升級版本
基本概念
Commons-logging
apache最早提供的日誌的門面介面。避免和具體的日誌方案(log4j、logback等)直接耦合。類似於JDBC的api介面,具體的的JDBC driver實現由各資料庫提供商實現。JCL的思想也是想通過統一介面解耦,將日誌方案的實現與日誌介面分離。
但是Apache Commons Logging的動態繫結並不是總能成功。解決方法之一就是在程式部署時靜態繫結指定的日誌工具,這就是slf4j產生的原因。
slf4j
slf4j跟JCL一樣,slf4j也是隻提供log介面,具體的實現是在打包應用程式時所放入的繫結器(名字為 slf4j-XXX-version.jar)來決定,XXX 可以是log4j12, jdk14, jcl, nop等,他們實現了跟具體日誌工具(比如 log4j)的繫結及代理工作。舉個例子:如果一個程式希望用log4j日誌工具,那麼程式只需針對slf4j-api介面程式設計,然後在打包時再放入log4j-slf4j-impl.jar等相關包就可以了。
比如我們的系統,使用了slf4j+log4j,需要使用到下面幾個包
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.7</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId Log4j、Logback
Log4j
Apache的一個開放原始碼專案,通過使用Log4j,我們可以控制日誌資訊輸送的目的地是控制檯、檔案、GUI元件、甚至是套介面伺服器、NT的事件記錄器、UNIX Syslog守護程序等;使用者也可以控制每一條日誌的輸出格式;通過定義每一條日誌資訊的級別,使用者能夠更加細緻地控制日誌的生成過程。這些可以通過一個 配置檔案來靈活地進行配置,而不需要修改程式程式碼。
LogBack
Logback是由log4j創始人設計的又一個開源日記元件。logback當前分成三個模組:logback-core,logback- classic和logback-access。logback-core是其它兩個模組的基礎模組。logback-classic是log4j的一個改良版本。此外logback-classic完整實現slf4j API使你可以很方便地更換成其它日記系統如log4j或JDK14 Logging。logback-access訪問模組與Servlet容器整合提供通過Http來訪問日記的功能。
Log4j與LogBack比較
LogBack作為一個通用可靠、快速靈活的日誌框架,將作為Log4j的替代和SLF4J組成新的日誌系統的完整實現。LOGBack聲稱具有極佳的效能,“ 某些關鍵操作,比如判定是否記錄一條日誌語句的操作,其效能得到了顯著的提高。這個操作在LogBack中需要3納秒,而在Log4J中則需要30納秒。 LogBack建立記錄器(logger)的速度也更快:13微秒,而在Log4J中需要23微秒。更重要的是,它獲取已存在的記錄器只需94納秒,而 Log4J需要2234納秒,時間減少到了1/23。跟JUL相比的效能提高也是顯著的”。 另外,LOGBack的所有文件是全面免費提供的,不象Log4J那樣只提供部分免費文件而需要使用者去購買付費文件。
Log4j版本升級
對於Log4j的使用場景,肯定是多執行緒併發的情況。一個new FileOutputStream物件表示一個開啟檔案物件。那麼當多個執行緒使用同一個FileOutputStream物件寫檔案時,就需要進行同步操作。
可以把一個FileAppender物件理解成維護了一個開啟檔案物件,當Logger在多執行緒情況下把日誌寫入檔案時,需要對Appender進行同步,也就是說對Logger加鎖,保證使用同一個Logger物件時,一次只有一個執行緒使用這個FileAppender來寫檔案,避免了多執行緒情況下寫檔案錯誤。
log4j 1.x版本的鎖
Hierarchy.java,多個執行緒使用同一個Logger時,加鎖。
public void callAppenders(LoggingEvent event) {
int writes = 0;
for(Category c = this; c != null; c=c.parent) {
// Protected against simultaneous call to addAppender, removeAppender,...
synchronized(c) {
if(c.aai != null) {
writes += c.aai.appendLoopOnAppenders(event);
}
if(!c.additive) {
break;
}
}
}
if(writes == 0) {
repository.emitNoAppenderWarning(this);
}
}AppenderSkeleton.java,多個執行緒使用同一個Appender時,對Appender加鎖
public synchronized void doAppend(LoggingEvent event) {
if(closed) {
LogLog.error("Attempted to append to closed appender named ["+name+"].");
return;
}
if(!isAsSevereAsThreshold(event.getLevel())) {
return;
}
Filter f = this.headFilter;
FILTER_LOOP:
while(f != null) {
switch(f.decide(event)) {
case Filter.DENY: return;
case Filter.ACCEPT: break FILTER_LOOP;
case Filter.NEUTRAL: f = f.getNext();
}
}
this.append(event);
}
這幾個鎖在高併發的情況下對系統的效能影響很大,會阻塞掉業務程序,特別是在for迴圈里加鎖的方式很不可取。而日誌收集工作應該是作為一個輔助功能,不能影響主業務功能。
log4j 2.3的執行緒切換
Log4j 2使用了新一代的基於LMAX Disruptor的無鎖非同步日誌系統。在多執行緒的程式中,非同步日誌系統吞吐量比Log4j 1.x和logback高10倍,而時間延遲更低。
聽起來很美,是不是?
發現這個問題的原因是我們線上出了一次故障,當一次網路異常,導致上游不斷重試併發請求量特別高時,cpu利用率跑到了4000%,服務完全恢復不過來了,一開始以為是GC的原因導致服務出問題了。後來線上下進行復現,檢視GC發現沒啥異常,但是發現瞭如下的資料
dstat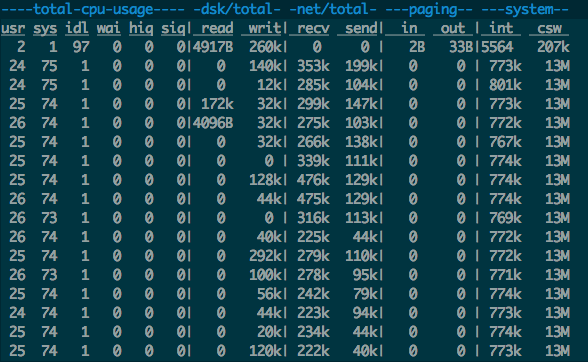
usr 佔用不高,sys 佔用超高,同時csw(context switch) 達到1200w,一次csw 大約耗費1000ns,已經逼近cpu的極限。
jstack -l 43911> 43911.log
grep tid 43911.log | wc -l
12312
grep RUNNABLE 43911.log | wc -l
53
匯流排程12312,處於runnable的只有53個,看看這些執行緒在幹什麼
"pool-6-thread-14380" prio=10 tid=0x00007f7087594000 nid=0x53e1 runnable [0x00007f6b67bfc000]
java.lang.Thread.State: TIMED_WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:349)
at com.lmax.disruptor.MultiProducerSequencer.next(MultiProducerSequencer.java:136)
at com.lmax.disruptor.MultiProducerSequencer.next(MultiProducerSequencer.java:105)
at com.lmax.disruptor.RingBuffer.publishEvent(RingBuffer.java:502)
at org.apache.logging.log4j.core.async.AsyncLoggerConfigHelper.callAppendersFromAnotherThread(AsyncLoggerConfigHelper.java:342)
at org.apache.logging.log4j.core.async.AsyncLoggerConfig.callAppenders(AsyncLoggerConfig.java:114)
......
grep "LockSupport.java:349" 43911.log | wc -l
11536
執行緒都跑在LockSupport.java:349,
unsafe.park(false, 1);
1 nano = 10^-9s, 推測大量執行緒頻繁的短時間sleep造成了大量的執行緒切換,做個實驗:
public static void contextSwitchTest(int threadCount) throws Exception {
ExecutorService executorService = Executors.newFixedThreadPool(threadCount);
for (int i = 0; i < threadCount; i++) {
executorService.execute(new Runnable() {
@Override
public void run() {
while (true) {
LockSupport.parkNanos(1);
}
}
});
}
executorService.awaitTermination(Long.MAX_VALUE, TimeUnit.SECONDS);
}在一臺搭載了兩個E5-2670 v3 @ 2.30GHz的機器上測試這段程式碼,在threadCount達到600後,測試跑起來後立即發現上下文切換到百萬級別,推測被印證。
原因找到了,接下來看看出問題是log生產速度怎麼樣:通過不斷地ls -al error.log/business.log,發現Log的生成速度才幾MB/s,遠沒有達到磁碟的極限200M/s,再做個測試:
private static void loggerSpeedTest(int threadCount) throws Exception {
ExecutorService executorService = Executors.newFixedThreadPool(threadCount);
for (int i = 0; i < threadCount; i++) {
executorService.execute(new Runnable() {
@Override
public void run() {
while (true) {
LOGGER.error("test log4j2 logging speed", new UnsupportedOperationException());
}
}
});
}
executorService.awaitTermination(Long.MAX_VALUE, TimeUnit.SECONDS);
}執行緒少的時候速度還行,執行緒一多很慢,問題找到了,但什麼造成的這個問題呢,順著stacktrace挖一挖:
AsyncLoggerConfig.callAppenders()
@Override
protected void callAppenders(final LogEvent event) {
// populate lazily initialized fields
event.getSource();
event.getThreadName();
// pass on the event to a separate thread
if (!helper.callAppendersFromAnotherThread(event)) {
super.callAppenders(event);
}
}AsyncLoggerConfigHelper.callAppendersFromAnotherThread()
public boolean callAppendersFromAnotherThread(final LogEvent event) {
// TODO refactor to reduce size to <= 35 bytecodes to allow JVM to inline it
final Disruptor<Log4jEventWrapper> temp = disruptor;
if (temp == null) { // LOG4J2-639
LOGGER.fatal("Ignoring log event after log4j was shut down");
return true;
}
// LOG4J2-471: prevent deadlock when RingBuffer is full and object
// being logged calls Logger.log() from its toString() method
if (isAppenderThread.get() == Boolean.TRUE //
&& temp.getRingBuffer().remainingCapacity() == 0) {
// bypass RingBuffer and invoke Appender directly
return false;
}
// LOG4J2-639: catch NPE if disruptor field was set to null after our check above
try {
LogEvent logEvent = event;
if (event instanceof RingBufferLogEvent) {
logEvent = ((RingBufferLogEvent) event).createMemento();
}
logEvent.getMessage().getFormattedMessage(); // LOG4J2-763: ask message to freeze parameters
// Note: do NOT use the temp variable above!
// That could result in adding a log event to the disruptor after it was shut down,
// which could cause the publishEvent method to hang and never return.
disruptor.getRingBuffer().publishEvent(translator, logEvent, asyncLoggerConfig);
} catch (final NullPointerException npe) {
LOGGER.fatal("Ignoring log event after log4j was shut down.");
}
return true;
}RingBuffer.publishEvent()
@Override
public <A, B> void publishEvent(EventTranslatorTwoArg<E, A, B> translator, A arg0, B arg1){
final long sequence = sequencer.next();
translateAndPublish(translator, sequence, arg0, arg1);
}MultiProducerSequencer.next()
@Override
public long next(int n){
if (n < 1){
throw new IllegalArgumentException("n must be > 0");
}
long current;
long next;
do{
current = cursor.get();
next = current + n;
long wrapPoint = next - bufferSize;
long cachedGatingSequence = gatingSequenceCache.get();
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > current){
long gatingSequence = Util.getMinimumSequence(gatingSequences, current);
if (wrapPoint > gatingSequence){
LockSupport.parkNanos(1); // TODO, should we spin based on the wait strategy?
continue;
}
gatingSequenceCache.set(gatingSequence);
}else if (cursor.compareAndSet(current, next)){
break;
}
}while (true);
return next;
}整個流程下來就是說在消費速度跟不上生產速度的時候,生產執行緒做了無限重試,重試間隔為1 nano,這個1 nano 會導致執行緒被頻繁休眠/喚醒,造成kernal cpu 利用率高,context switch已經達到了cpu的極限,進而導致寫log的執行緒的執行緒獲取cpu時間少,吞吐量下降。
if this fails because the queue is full, then fall back to asking AsyncEventRouter what to do with the event,
把log4j2版本切到2.7, 跑一下上面的測試,發現效能上來了, context swtich也有了數量級的下降,看看怎麼辦到的:
AsyncLoggerConfig.callAppenders()
@Override
protected void callAppenders(final LogEvent event) {
populateLazilyInitializedFields(event);
if (!delegate.tryEnqueue(event, this)) {
final EventRoute eventRoute = delegate.getEventRoute(event.getLevel());
eventRoute.logMessage(this, event);
}
}AsyncLoggerConfigDisruptor.getEventRoute()
@Override
public EventRoute getEventRoute(final Level logLevel) {
final int remainingCapacity = remainingDisruptorCapacity();
if (remainingCapacity < 0) {
return EventRoute.DISCARD;
}
return asyncQueueFullPolicy.getRoute(backgroundThreadId, logLevel);
}DefaultAsyncQueueFullPolicy.getRoute()
@Override
public EventRoute getRoute(final long backgroundThreadId, final Level level) {
// LOG4J2-1518: prevent deadlock when RingBuffer is full and object being logged calls
// Logger.log in application thread
// See also LOG4J2-471: prevent deadlock when RingBuffer is full and object
// being logged calls Logger.log() from its toString() method in background thread
return EventRoute.SYNCHRONOUS;
}沒有了park,被block的執行緒沒有一直被排程,context switch減少了,kernel cpu下降了,真正獲取到lock的執行緒獲得了更多的cpu用來幹活了。
log4j的效能
一想到效能,有哪些是對java程式影響大的呢? 我們直觀地會認為反射、編解碼,這些東西對效能影響比較大。
使用JProfiler進行分析後,一些結果卻讓人吃驚不小,最耗CPU的居然是以下函式
InetSocketAddress.getHostName()
Log.info
String.format
String.replace
Gson.fromJson
把log關閉後,InetSocketAddress.getHostName()的居然佔到了驚人的27%!
當然,以我司的文化來說,一個簡單業務邏輯的PHP服務,從最初的幾百臺機器優化到60多臺能吹上天。而java的服務只用最基本的4臺(這樣一上線在不考慮重試的情況下,對業務影響率最多為25%),卻因為cpu idle常年保持在97以上被認為是浪費機器,看來這些也許不是那麼關鍵的,說不定到時候還得靠多調這些函式來滿足idle掉到70以下,以避免機器被回收。
參考文件
java日誌,需要知道的幾件事
本文中關於log4j 2.3的主要內容其實是我mentor寫的,我主要是重新走了一下流程,補全了圖片與測試資料,並對內容做了少部分處理。