
Spark執行狀態的監控
阿新 • • 發佈:2019-01-23
強力推薦,相見恨晚的文件,建議先看
關於Spark監控,推薦一個講的非常好的PPT:monitoring-spark-applications,簡練、全面的講解了Spark監控的必要性、方法、缺點及改進方法。
下面是我自己的一些總結
Spark UI監控,有三個維度
對Spark執行時的狀態進行監控可以對執行時間較長的大型任務執行過程心中有數,明白時間花費在什麼地方,看任務在什麼地方發生異常。首先說明Spark的一個application的劃分規則。
- job :job是application的組成單位。 A job is triggered by an action, like count() or saveAsTextFile(). Click on a job to see information about the stages of tasks inside it. 一個 job,就是由一個 rdd 的 action 觸發的動作,可以簡單的理解為,當你需要執行一個 rdd 的 action 的時候,會生成一個 job.
- stage : stage 是 job 的組成單位,就是說,一個 job 會被切分成 1 個或 1 個以上的 stage,然後各個 stage 會按照執行順序依次執行。job 根據Spark的shuffle過程來切分 stage,如某stage有2個shuffle過程,它就被切分成3個stage.
- task : A unit of work within a stage, corresponding to one RDD partition。即 stage 下的一個任務執行單元。“一般來說,一個 rdd 有多少個 partition,就會有多少個 task,因為每一個 task 只是處理一個 partition 上的資料。”
對Spark的監控需求,可以按需劃分為針對job的監控、針對stage的監控和針對task的監控,Spark UI提供了以下三種監控介面:
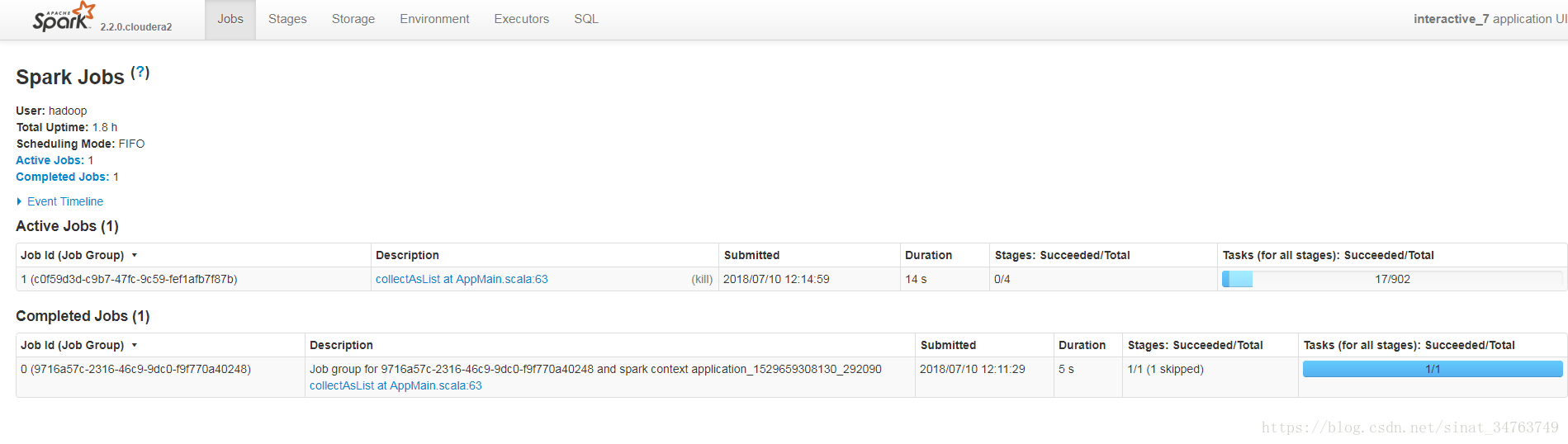
- 針對job的監控:每次查詢都是一個Job,下圖顯示一個已經完成的查詢任務和一個正在進行的查詢任務,每一個任務的具體進度在行末展示
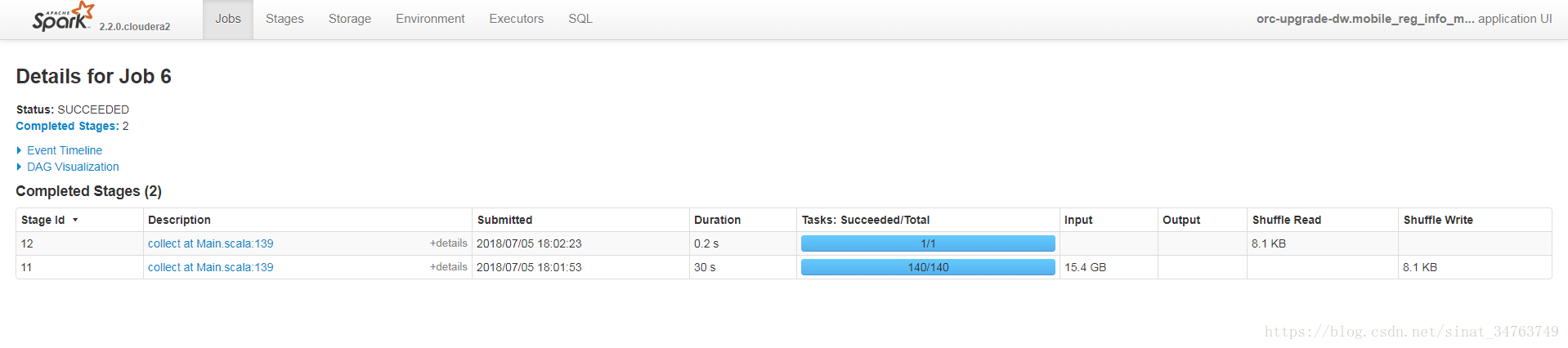
- 針對stage的監控:一個job裡所有的stage列表
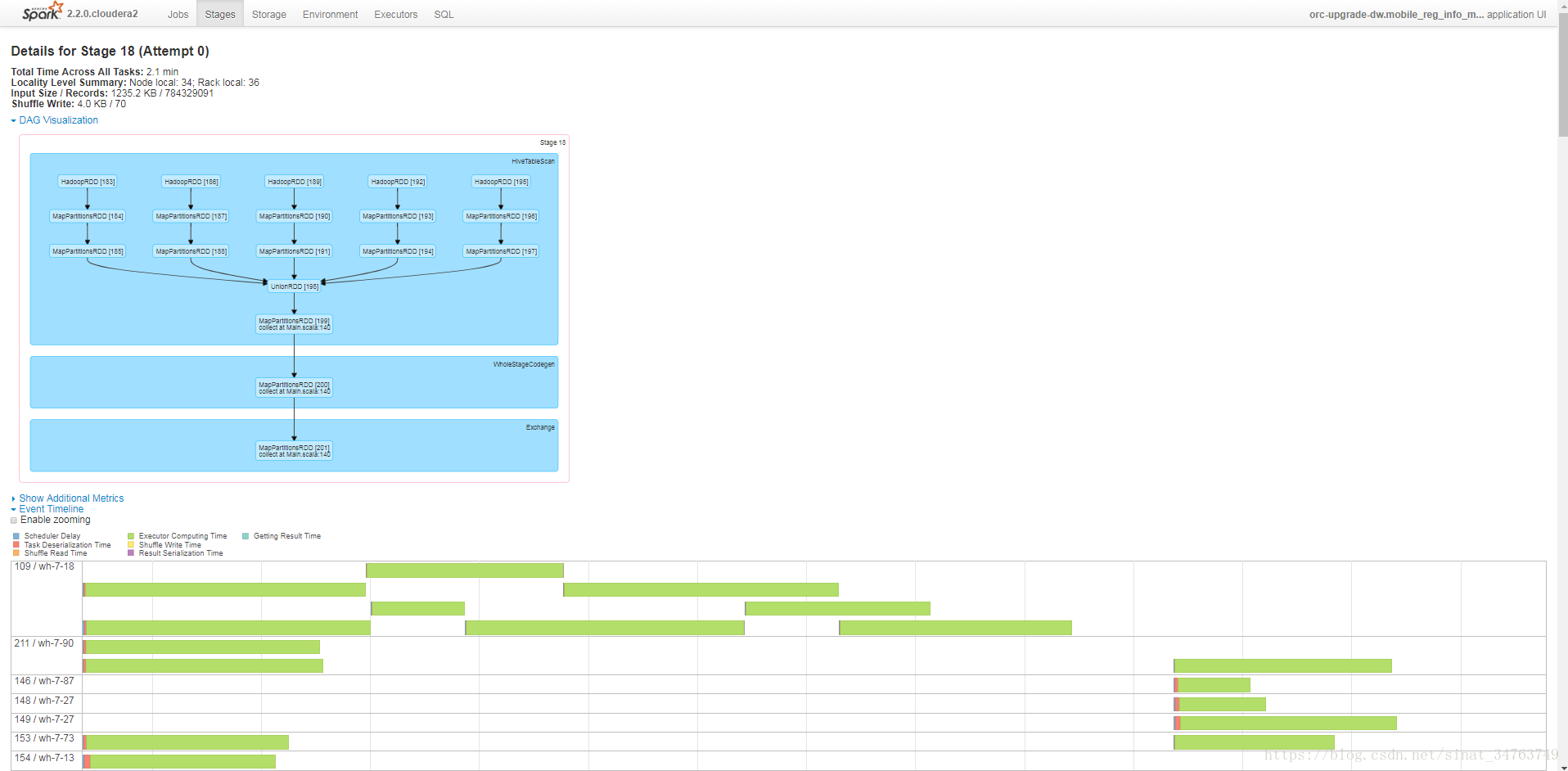
- 針對task的監控:一個stage裡所有的task列表
每一種監控方式都能展示其每一步消耗的時間,可以通過Event Timeline的方式只管的看時間消耗。針對某一消耗時長異常的步驟進行檢查或者調優。
這種監控方式的優點是直觀易懂,而且大部分的表格可以用json的形式提供給其他應用
值得注意的是,Spark UI監控的埠有配置有些小trick,spark預設配置和CDH配置有所不同:
-
For the history server, they would typically be accessible at http://:18080/api/v1, and for a running application, at http://localhost:4040/api/v1.
Spark 日誌監控,詳細但不直觀
此外,Spark日誌也可以列印Spark的執行狀態,節選一個task從啟動到結束的日誌:
18/07/05 18:18:24 INFO executor.CoarseGrainedExecutorBackend: Got assigned task 1242
18/07/05 18:18:24 INFO executor.Executor: Running task 32.0 in stage 18.0 (TID 1242)
18/07/05 18:18:24 INFO rdd.HadoopRDD: Input split: hdfs://sdg/user/hive/warehouse/transfer.db/mobile_reg_info_mid_orc/part_date=2016-10-31/part-00003-bd8e8e72-7946-45c4-b995-badead467bab.c000:268435456+69819839
18/07/05 18:18:24 INFO orc.OrcRawRecordMerger: min key = {originalTxn: 0, bucket: -1, row: 15099999}, max key = null
18/07/05 18:18:24 INFO orc.ReaderImpl: Reading ORC rows from hdfs://sdg/user/hive/warehouse/transfer.db/mobile_reg_info_mid_orc/part_date=2016-10-31/part-00003-bd8e8e72-7946-45c4-b995-badead467bab.c000 with {include: [true, false, false, false, false, false, false, false], offset: 268435456, length: 9223372036854775807}
18/07/05 18:18:25 INFO executor.Executor: Finished task 32.0 in stage 18.0 (TID 1242). 1510 bytes result sent to driver這種方式較優點是易於輸出、易於在其他工具上整合,缺點是不直觀。
對於互動式查詢場景的監控
- 每次查詢都是一個Job,可以展示所有已經完成的查詢任務和正在進行的查詢任務
- 如果只想大概瞭解程式執行的進度(類比MR過程中map和reduce的百分比),建議展示所有stage的執行進度,如上圖“針對job的監控”所示。自己實現該監控可以通過呼叫Spark REST API獲取已完成任務數和總任務數,兩者相除得到。
- 如果想了解執行程式過程中,具體到哪一步卡住了,建議展示“針對stage的監控:一個job裡所有的stage列表”,檢視該內容並排查錯誤需要對Spark的執行機制有一定的瞭解。
- “針對task的監控:一個stage裡所有的task列表”具體到了程式碼行的層面,需要對Spark很瞭解才能理解,需要專業的開發人員解讀。