
Python 中文分詞 NLPIR 快速搭建
前述
本篇文章寫完需要半個小時,閱讀需要十分鐘,讀完後,你將學會在Python中使用NLPIR,以及關於使用它的一些有用的基礎知識
NLPIR 是中科院的漢語分詞系統,在Python中使用也比較廣泛,而且曾多次奪得漢語分詞比賽的冠軍,並且其可以在多個語言上都實現了介面甚至在Hadoop中也可以使用,博主比較推薦NLPIR
NLPIR在Python中的兩種實現方式的比較
NLPIR在Python中有兩種實現方式
1. pip install pynlpir(即下載,python封裝的nlpir類庫)
2. 直接在專案中引入NLPIR,使用官方的py檔案,直接呼叫dll檔案介面
第一種方式的好處在於便於使用?只需要pip install 即可,但是博主不推薦這種方式,因為pynlpir功能太少,根本無法滿足我們的使用要求,而且與其安裝pynlpir還不如直接安裝jieba,其原始碼中實現的介面如下:
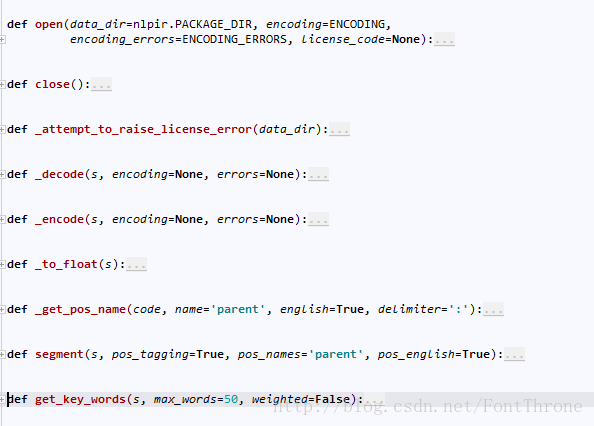
在下載了pynlpir之後,我就開始上手使用,然而…它似乎沒有實現使用者新增詞典的功能,除非去包裡面直接把詞典換了,這樣一來,假如我們又遇到了”路明非”的問題,就是錯分新詞”路明非”為兩個詞”路明”,”明非”,原文例子請點選http://blog.csdn.net/fontthrone/article/details/72782499,在NLPIR沒有識別其為新詞的情況下,那麼我們根本無法通過pynlpir本身解決,雖然可以利用from pynlpir import nlpir
而相對之下,原版的NLPIR雖然配置略顯麻煩,但是無論更全面,因此在需要更強大的功能時,博主推薦使用NLPIR,而他們的功能我將會在下面的部分說明.
Python 類庫 pynlpir
1.安裝
無論py2/3,只需pip install pynlpir即可
2. demo code
# - * - coding: utf - 8 -*-
#
# 作者:田豐(FontTian) 
(1)即使是在python2中設定了檔案的預設格式為utf-8但是因為在windows中控制檯的中文預設編碼格式為gbk,所以控制檯的視窗依然會顯示亂碼,但是請放心,通過
import sys
reload(sys)
sys.setdefaultencoding('utf8')
其實str的預設編碼格式已經成了utf-8.
(2)為了在控制檯檢視demo中的分詞,可以使用迭代器迴圈輸出,同時也因為編碼格式確實是utf-8,所以這是即使不再使用encode(‘utf-8’),但是控制檯仍然不會亂碼.
下面是wordslist2中的分詞

效果良好
在Python中使用NLPIR的介面
在博主在Python中使用NLPIR的時候參考了這篇文章:Python呼叫中科院NLPIR(ICTCLAS2015)詳解,但是隻是部分借鑑,博主使用的是2016,其實使用NLPIR非常簡單,只要自己看看官方的文件就可以很好的使用,不過官方文件是真的亂.而且是分散的.
1.根據博主之前參考的部落格,似乎想要使用NLPIR,首先要在電腦上搭建swig
下面是一段引用,github下載地址swig官網下載地址
友情提示:如果是swig問題,自己處理。首先下載swig,swig可以幫助我們將C或者C++編寫的DLL或者SO檔案繫結到包括Python在內的多種語言。Windows下將安裝包下載到一定目錄下將該目錄加入環境變數的path中即可使用swig(當然也可以輸入完整的路徑來使用swig)。可以開啟命令列視窗,在裡面輸入swig,如果出現“Must specify an input file. Use -help for available options.”則表示一切順利。
3.
(1)在下載檔案之後,解壓檔案,然後新建資料夾”組合包”,其它名稱亦可
(2)組合包內成員包括:
1. 漢語分詞20140928\sample\pythonsample下所有檔案
2. Data資料夾,直接複製拖入即可
3. 新建資料夾”bin”下為”importuserdict”中的zip檔案解壓後文件,注意此處為NLPIR的自帶詞典,如果你想新增自己的詞典,你可以閱讀此檔案下的REAME.txt,來新增自己的詞庫
4. 根據機器的位數(64/32)修改配置檔案
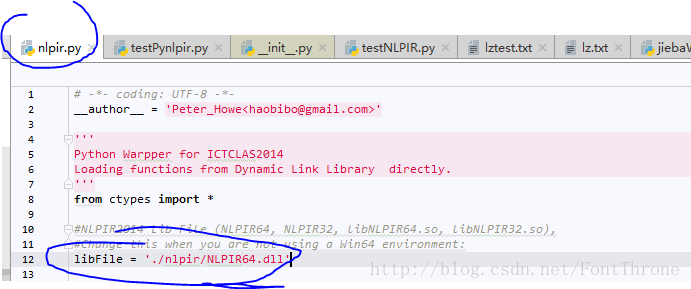
5. 證書問題:當你一次在Python中呼叫NLPIR時會報:Initialization failed!
放心第一次執行出現這個錯誤這一般是正常的你只要去現在最新的授權證書就可以了.
具體請參考我之前的文章:http://blog.csdn.net/fontthrone/article/details/72692691
6. 注意預設的nlpir的預設Python介面為Python2.如果你想在python3中使用nlpir你可以參考官方文件,同時這篇文章中也對python介面的其他問題進行了說明:
https://github.com/haobibo/ICTCLAS_Python_Wrapper
7.在Python2.7中使用NLPIR2016
(1)直接將剛才做好的資料夾中的所有檔案拖入你的專案即可使用:
(2)然後按照普通的引用Python檔案來使用nlpir即可:
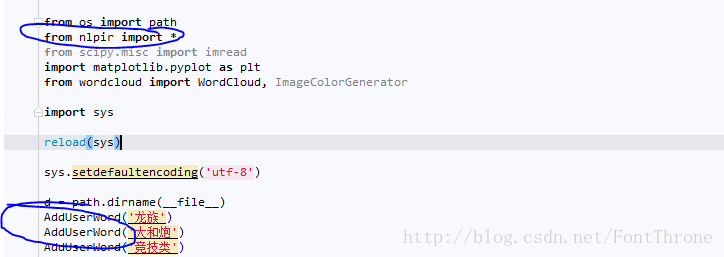
(3)具體可引用的方法直接查詢官方給的nlpir檔案即可
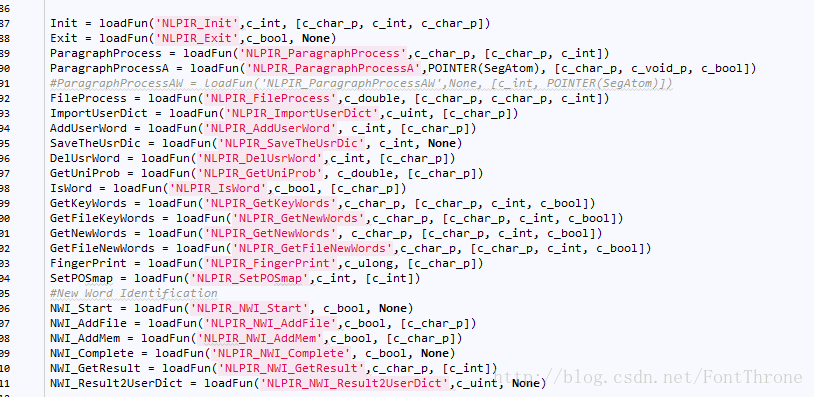
在測試之後,確實直接引用官方介面,功能確實強了很多
最後附上一個簡單的測試程式碼,我將會在下一篇文章詳細介紹nlpir2016Python介面使用(最近有點忙,可能在這個週週末才能更新,故而附上小生qq:2404846224,有興趣一起學習的小夥伴,請備註來自csdn部落格)
# - * - coding: utf - 8 -*-
#
# 作者:田豐(FontTian)
# 建立時間:'2017/5/31'
# 郵箱:[email protected]
# CSDN:http://blog.csdn.net/fontthrone
from os import path
from nlpir import *
from scipy.misc import imread
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
d = path.dirname(__file__)
AddUserWord('龍族')
AddUserWord('大和炮')
AddUserWord('競技類')
# Init()
# SaveTheUsrDic('路明非')
text_path = 'txt/lztest.txt' #設定要分析的文字路徑
stopwords_path = 'stopwords\stopwords1893.txt' # 停用詞詞表
text = open(path.join(d, text_path)).read()
txt = seg(text)
seg_list =[]
for t in txt:
seg_list.append(t[0].encode('utf-8'))
seg_list += ' '
# 使用NLPIR進行中文分詞
print seg_list
# 去除停用詞
def jiebaclearText(text):
mywordlist = []
liststr = "/ ".join(seg_list)
f_stop = open(stopwords_path)
try:
f_stop_text = f_stop.read()
f_stop_text = unicode(f_stop_text, 'utf-8')
finally:
f_stop.close()
f_stop_seg_list = f_stop_text.split('\n')
for myword in liststr.split('/'):
if not (myword.strip() in f_stop_seg_list) and len(myword.strip()) > 1:
mywordlist.append(myword)
return ''.join(mywordlist)
# 去除完停用詞的文字
s = jiebaclearText(seg_list)
print s相關推薦
Python 中文分詞 NLPIR 快速搭建
前述 本篇文章寫完需要半個小時,閱讀需要十分鐘,讀完後,你將學會在Python中使用NLPIR,以及關於使用它的一些有用的基礎知識 NLPIR 是中科院的漢語分詞系統,在Python中使用也比較廣泛,而且曾多次奪得漢語分詞比賽的冠軍,並且其可以在多個語言上都
PyNLPIR python中文分詞工具
命名 hub 兩個 工具 ict mage ret wid tty 官網:https://pynlpir.readthedocs.io/en/latest/ github:https://github.com/tsroten/pynlpir NLPIR分詞系
python中文分詞,使用結巴分詞對python進行分詞
php 分詞 在采集美女站時,需要對關鍵詞進行分詞,最終采用的是python的結巴分詞方法.中文分詞是中文文本處理的一個基礎性工作,結巴分詞利用進行中文分詞。其基本實現原理有三點:基於Trie樹結構實現高效的詞圖掃描,生成句子中漢字所有可能成詞情況所構成的有向無環圖(DAG)采用了動態規劃查找最大概率
python基礎===jieba模塊,Python 中文分詞組件
word cut 用法 地址 api mas 精確 == com api參考地址:https://github.com/fxsjy/jieba/blob/master/README.md 安裝自行百度 基本用法: import jieba #全模式 word = jie
Python中文分詞 jieba
問題 turn Coding windows 停用 分享圖片 詞典 ces text1 三種分詞模式與一個參數 以下代碼主要來自於jieba的github,你可以在github下載該源碼 import jieba seg_list = jieba.cut("我來到北京清
python中文分詞器(jieba類庫)
先上效果圖: 資料來源: 分詞後的txt檔案: 分詞後的excel檔案: 原始碼: #!/usr/bin/python # -*- coding: UTF-8 -*- # *************************************
Python中文分詞_使用介紹(wordcloud+jieba)
詞雲又叫文字雲,是對文字資料中出現頻率較高的“關鍵詞”在視覺上的突出呈現,形成關鍵詞的渲染形成類似雲一樣的彩色圖片,從而一眼就可以領略文字資料的主要表達意思。 安裝需要的libs 接下來的程式碼裡會用到如下四個主要的libs,我本地是64位win10,安
對Python中文分詞模組結巴分詞演算法過程的理解和分析
結巴分詞是國內程式設計師用python開發的一箇中文分詞模組, 原始碼已託管在github, 地址在: https://github.com/fxsjy/jieba 作者的文件寫的不是很全, 只寫了怎麼用, 有一些細節的文件沒有寫. 以下是作者說明檔案中提到的結巴分
Python 中文分詞 jieba(小白進)
0、安裝 法1:Anaconda Prompt下輸入conda install jieba 法2:Terminal下輸入pip3 install jieba 1、分詞 1.1、CUT函式簡介 cut(sentence, cut_all=False, HMM=
python中文分詞工具:結巴分詞jieba
結巴分詞jieba特點 支援三種分詞模式: 精確模式,試圖將句子最精確地切開,適合文字分析; 全模式,把句子中所有的可以成詞的詞語都掃描出來, 速度非常快,但是不能解決歧義; 搜尋引擎模式,在精確模式的基礎上,對長詞再次切分,提
python中文分詞jieba的高階應用
最近在使用python的中文分詞功能,感覺jieba挺不錯的,就轉載了這篇文章,希望對各位CSDN網友有所幫助。 jieba "結巴"中文分詞:做最好的Python中文分片語件 "Jieba" Feature 支援三種分詞模式: 精確模式,試圖將句子最精確地
Python中文分詞 jieba 十五分鐘入門與進階
整體介紹 下篇博文將介紹將任意中文文字生成中文詞雲 同時如果你希望使用其它分詞工具,那麼你可以留意我之後的部落格,我會在接下來的日子裡釋出其他有關內容. 三種分詞模式與一個引數## 以下程式碼主要來自於jieba的github,你可以在github下載該原始碼
Python中文分詞--jieba的基本使用
中文分詞的原理 1、中文分詞(Chinese Word Segmentation) 指的是將一個漢字序列切分成一個一個單獨的詞。 分詞就是將連續的字序列按照一定的規範重新組合成詞序列的過程 2、現有的分詞演算法可分為三大類:基於字串匹配的分詞方法、基於理解的分詞方法
jieba(結巴)—— Python 中文分詞
學術界著名的分詞器: 中科院的 ICTCLAS,程式碼並不十分好讀 哈工大的 ltp, 東北大學的 NIU Parser, 另外,中文 NLP 和英文 NLP 不太一致的地方還在於,中文首先需要分詞,針對中文的分詞問題,有兩種基本的解決思路: 啟發式(He
solr服務快速搭建、配置中文分詞、資料匯入即solrj增刪改查
一.準備工作 1. 環境準備: 1.1 centos 6.5/mac os 10.12.6 2. 假定一個需求:現在需要索引商品資訊,以支撐前臺商品展示頁面的搜尋。 資料庫中的表有商品分類表和商品詳情表 -- 商品表: D
python 讀寫txt文件並用jieba庫進行中文分詞
mage 亂碼 技術分享 流行 ictclas 函數 結果 class 配置 python用來批量處理一些數據的第一步吧。 對於我這樣的的萌新。這是第一步。 #encoding=utf-8 file=‘test.txt‘ fn=open(file,"r") print f
搭建ELASTICSEARCH實現中文分詞搜索功能
area 普通 ron too alt 下載 bootstrap arch osi 安裝ELASTICSERARCH yum install bzip2 automake libtool gcc-c++ java-1.8.0-openjdk -y mkdir -p /h
python安裝Jieba中文分詞組件並測試
圖片 class pypi setup.py bubuko for 中文 users mage python安裝Jieba中文分詞組件 1、下載http://pypi.python.org/pypi/jieba/ 2、解壓到解壓到python目錄下: 3、
Python第三方庫jieba(結巴-中文分詞)入門與進階(官方文檔)
修改 demo 特點 pypi nlp CA 動態修改 tag 官方文檔 jieba “結巴”中文分詞:做最好的 Python 中文分詞組件。下載地址:https://github.com/fxsjy/jieba 特點 支持三種分詞模式: 精確模式,試圖將句子最精確地
中文分詞--最大正向匹配算法python實現
命中 col odin app () 切分 -- \n 多個 最大匹配法:最大匹配是指以詞典為依據,取詞典中最長單詞為第一個次取字數量的掃描串,在詞典中進行掃描(為提升掃描效率,還可以跟據字數多少設計多個字典,然後根據字數分別從不同字典中進行掃描)。例如:詞典中最長詞為“中