
Node.js And C++__9.Addons替代解決方案
注:本附錄主要取自作者網站blog.scottfrees.com上的一系列部落格文章,其中涵蓋了將現有的C/C++程式*整合到一個Node.js 的各種方法。這個系列是獨立於本書的,因此,您可能會發現其中的一些內容是多餘的,但是它展示了一個真實的例子,它集成了legacy(老版本)的c++程式碼,而不是書中狹義的例子。該部分還有一個不同的github儲存庫,可以從本書的其他例子中下載程式碼。強烈建議您獲取程式碼,因為其中有很多沒有在文字中顯示!
這本書的重點是 Node.js C++ addons作為整合Node.js和c++的方法。在許多情況下,addons確實是進行這種整合的最佳選擇,但是還有其他選擇——如果不討論這些選項,這本書就不完整了。在這樣做之前,讓我們後退一步,在第1章中重新詢問這個問題:為什麼要整合 Node.js 和 C++?為了加強討論,讓我們從現有的c++ /C程式的角度來看這個問題,您希望能夠訪問web
我就不能寫一個c++網站嗎?
嗯…是的,你可以!在很長一段時間內,人們一直在用c++使用CGI編寫web應用程式的部分內容。CGI並不是當今網路上最受歡迎的東西,它缺乏大量的生產力增強,使得web開發今天變得如此的偉大。更重要的是,它引入了一些重要的效能和可伸縮性問題。另一方面,c++在過去的幾年裡在表達方面取得了長足的進步,c++ 14標準使一些非常酷的專案專注於在純c++中編寫現代的MVC-styled的web應用程式。如果這是你的事情,那就去看看Silicon。
大多數web開發人員不是c++程式設計師,坦率地說,除非您的web層的超高效能是至關重要的,否則您最好使用提供更高級別抽象的語言。網路上後臺的通常執行的是Ruby, Go, Node.js, Python, PHP等等。
Node.js有很多優點。首先,它以幾種不同的方式與c++很好地整合在一起——當然,我們在本書中看到了這一點!一般來說, Node.js也有很多好處,它與你最初使用c++的原因是一樣的——它是高度可移植性的,它促進了規模的效能,並且有一個繁榮的ecosystem。
啊…每個開發人員的第一個本能——“讓我們重寫這個用語言X編寫的舊程式碼,因為語言Y要比|好得多,|更快|更容易!”首先,如果您有一些簡單、小且不需要高效能的 legacy(老版本)c++程式碼,這可能是最好的答案。然而,如果你屬於那個類別,你可能沒有讀到這篇文章——你很可能已經重寫了c++程式碼。
首先:不重寫程式碼有一些實際的原因。首先,您可能沒有程式碼!信不信由你,如果你為一家使用傳統工具來支援業務的公司工作,那麼這些工具的原始碼常常會丟失。這是當您的遺留程式碼使用第三方依賴時,不能重寫或修改的時候。
**第二:**C/C++可能是複雜的,如果它是舊的,可能很難破譯。您是一個web開發人員,也是c++的專家嗎?你能完全重現這個程式的精確輸入/輸出嗎?如果這是一個關鍵的業務工具,你就會給你的盤子帶來很多風險。
第三:不重寫c++的原因是它可能真的想要使用c++ !當Node.js 的效能很好,根本不是 C/C++。如果您的應用程式有極端的效能標準,那麼您將不會超過c++。
C++ 整合到 Node.js 的方案
有三種通用的方法將c++程式碼與Node.js應用程式整合在一起。——儘管每個類別中有很多不同的變體。
- Automation :在子程序中,將c++作為一個獨立的應用程式。
- Shared library :在共享庫(dll)中打包您的c++例程,並從Node.js 直接呼叫這些事例。
Node.js Addon :編譯你的c++程式碼作為一個本地Node.js 模組/addon(我們現在都知道了,對吧?)
每個選項都有各自的優點和缺點,它們主要在您需要修改c++的程度上有所不同,在呼叫c++時,您願意接受的效能打擊,以及您在處理 Node.js和V8 API 時的熟練度/安全性。
選擇依據
最明顯的問題是,您是否可以訪問c++原始碼,或者僅僅是二進位制檔案?如果沒有原始碼,您需要希望c++程式可以是命令列程式,也可以是dll/lib共享庫。如果你看的是一個只有圖形使用者介面的程式,那麼你就處在痛苦的世界裡。您可能需要重寫您的應用程式,以便使其在web上工作。
Automation
如果您的c++執行作為一個獨立的命令列,您不需要原始碼來利用選項1 -automation 選項。您可以使用Node的子程序API 執行您的c++程式。這個選項適用於將任何東西帶到web上——如果你只是執行它的話,你的命令列程式寫在什麼語言上並沒有什麼區別。如果您正在閱讀這篇文章,希望獲得C程式碼、Fortran程式碼或其他一些語言,那麼這個選項值得一讀。
自動化選項不僅僅針對那些沒有c++程式碼的人。如果您有c++程式碼,或者可以很容易地轉換成命令列程式,那麼這個選項是合理的,如果您可以使用效能,並且您並不想陷入語言整合的麻煩中。
Shared Library / DLL
如果您處理的是c++ dll/lib,或者您有c++原始碼,並且可以進行適當的修改,以建立動態庫,那麼 shared library 方法可能對您很有效。在本章中,我們將詳細介紹如何使用外部函式介面模組進行此操作。這個選項可以讓您更精確地控制如何將c++整合到節點中,因為對c++例程的呼叫通常可以直接寫到Node.js程式碼中。雖然這種方法可以使您更接近完整的整合,但是您仍然需要處理型別轉換和在呼叫c++時阻塞。如果您想要更好的整合,這是一個很好的選擇,而無需花費大量時間來處理V8。
Node.js Addon
如果您有c++原始碼,那麼第三個選項是建立一個本機 Node.js模組呼叫你的c++。雖然這是一個更具挑戰性的方法,但是您獲得了大量的靈活性和效能。您還可以選擇非同步呼叫您的c++,這樣您就不會阻塞web應用程式的事件迴圈,而c++正在處理數字。當我們在本節中介紹這部分內容時,它將主要作為對書中主要章節中已經介紹的材料的回顧。
例子 - 質數分解
在本節中,我將向您展示如何實現上述每個選項的示例。我想在每個例子中都使用相同的基本例子。素數對於很多東西(比如密碼學)來說是極其重要的,而它們的生成往往是非常耗時的。線上快速搜尋將會引導你轉向C和c++的實現,而真正高效的實現是複雜的。看看他們的來源,你會馬上意識到你可能不想重寫他們——除非你只是在尋找一個挑戰——這很好)。
Node.js Express Web app
在這一節中,我將使用完全相同的 Node.js的web應用程式。它是非常簡單的,有一個HTML頁面,有一些JavaScript (AngularJS),它要求web伺服器在使用者指定的值下提供質數。web伺服器使用一個JSON物件來響應,其中包含了primes,它使用了我將實現的幾種技術之一。
我假設讀者對一個 Node.js web應用程式 有一些基本的理解,我在後臺用Express和AngularJS建立了這個應用程式,但是我避開了任何複雜性和eye/candy,以免分散這些教程的目的。它也是一個很好的API到你的c++程式碼的設定-只是拋棄UI!
$ git clone https://github.com/freezer333/cppwebify-tutorial.git
$ git checkout start
你可以自己瀏覽網頁應用——但相關的部分是前端——在/web/views 和後端找到的,在/index.js和 /routes中找到。
讓我們快速瀏覽一下/index.js。前十行左右只是樣板程式碼:
var express = require('express');
var app = express();
var bodyParser = require('body-parser');
app.use(express.static('public'));
app.set('view engine', 'jade');
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({ extended: true }));
下一行是構建一個 “types” 陣列——它最終將為post系列中的每個示例保留條目。現在,我們只有一個Node.js primesieve實現。
var types = [
{
title: "pure_node",
description: "Execute a really primitive " +
"implementation of prime sieve in Node.js"
}];
型別中的每個條目將對應於/route目錄中找到的路由。這些是從 index.js動態載入,web伺服器是由最後的一行程式碼開始的。
types.forEach(function (type) {
app.use('/'+type.title, require('./routes/' + type.title));
});
app.get('/', function (req, res) {
res.render('index', { routes: types});
});
var server = app.listen(3000, function () {
console.log('Web server listing at http://localhost:%s',
server.address().port);
});
要啟動web伺服器,請導航到終端的 /web 目錄並鍵入以下內容:
$ npm install
... dependencies will be installed
$ node index
現在將瀏覽器指向http://localhost:3000。您將獲得索引頁,其中列出了實現選項。現在,您只需要一個選項——“pure_node”。單擊它,您將看到一個帶有單個數字框的頁面。輸入100並提交-和節點。primesieve的js實現將執行並返回100以下的所有質數。
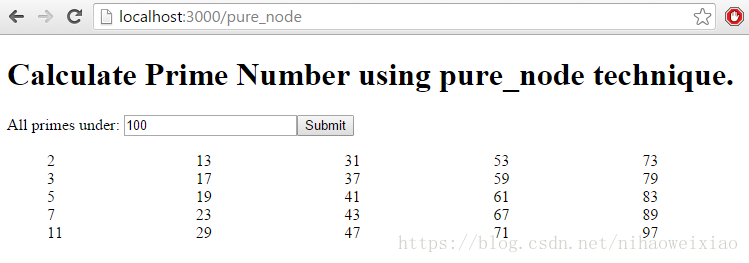
在 Node.js上的primesieve實現是在 routes/pure_node.js中。與我們將在本系列的其餘部分中使用的C實現相比,它非常簡單——但是它完成了任務!處理實際響應的程式碼是路由器的post方法:
router.post('/', function(req, res) {
var under = parseInt(req.body.under); // from the user
var primes = find_primes(under);
res.setHeader('Content-Type', 'application/json');
res.end(JSON.stringify({
results: primes
}));
});
Automating + Node.js Web app
如果您的c++獨立於命令列執行——或者可以這樣做——您可以使用Node的child process API執行它。這個選項適用於將任何東西帶到web上——如果你只是執行它的話,你的命令列程式寫在什麼語言上並沒有什麼區別。
自動化的兩個特點使它具有吸引力。首先,由於在另一個程序中執行c++應用程式,所以實際上是非同步地執行c++處理——這在web上是一個很大的勝利,因為您可以處理其他傳入的HTTP流量,而c++應用程式正在工作。其次,你真的不需要做大量的語言整合或者使用複雜的V8 API——實際上這很簡單!
對於這個特定的部分,從git儲存庫簽出 automation 標記。
$ git checkout automation
質數 C/C++分解器
如上所述,我們正在構建 Sieve of Eratosthenes 素數計算策略篩選器的C實現的所有示例。這是一個很好的例子,因為速度對於質數來說很重要,而我所使用的C程式碼並不是你想要重寫的型別。我所使用的示例——http://wwwhomes.uni-bielefeld.de/achim/prime_sieve.html——實際上是非常簡單的,相比之下,更復雜的技術可以利用CPU快取。到primesieve.org 去了解一下。對於Sieve的實現,程式的使用者必須輸入一個最大值,該演算法將輸出所有質數“在”這個值下。在本章的大部分內容中,我們將把這個輸入值稱為“under”。
primesieve.c
當面對整合遺留(legacy )程式時,您可能沒有訪問程式碼的特權。為了本章的目的,我將模擬一些常見的整合場景——我將編輯一些原始的 primesieve.c。
- 場景1:一個應用程式只從命令列引數中獲取輸入,並輸出到標準輸出。
- 場景2:一個應用程式從使用者(stdin)中獲取輸入,並輸出到標準輸出。
場景3:從檔案中獲取輸入並輸出到另一個檔案的應用程式。
為了模擬每個場景,我們希望能夠將FILE傳遞到主程式primesieve.c中,所以程式並不總是列印到控制檯。讓我們將 `main` 重新命名為 `generate_args` ,併為其新增第三個引數FILE。我們將在場景3中具體使用它。
// in cppwebify-tutorial/cpp/prime4standalone/prime_sieve.c,
// I've renamed int main(int argc, char *argv[])
// to:
int generate_args(int argc, char * argv[], FILE * out) {
... complicated prime number stuff ...
我將在另一個檔案(main.cpp)中寫入入口點,因此我也將 generate_args的宣告新增到一個名為 prime_sieve.h的標頭檔案中。
我正在建立第二個函式- generate ,它提供一個簡化的介面——它只接受“under”引數,而不是命令列引數。這個定義在 prime_sieve.c的底部。將引數轉換為字元引數並呼叫 generate_args.。這只是為了讓我不太編輯原始程式碼,並使場景2更簡潔。顯然,富有想象力的讀者可以想出更好的方法來完成這一切:)
// at the bottom of cppwebify-tutorial/cpp/prime4standalone/prime_sieve.c,
// an adapter function for use when we aren't using command-line arguments
int generate(int under, FILE *out) {
char * name = "primes";
char param [50];
sprintf(param, "%d", under);
char * values[] = { name, param};
generate_args(2, values, out);
}
所以,我們剩下的是 prime_sieve.h -使用 extern C 來確保我們的C函式可以正確地與c++主檔案整合,我將在示例中使用。
extern "C" {
// the old main, renamed - with a third parameter"
// to direct output to a file as needed
int generate_args(int argc, char * argv[], FILE * out);
// an adapter function when the caller hasn't
// received under through command line arguments
int generate(int under, FILE * out);
}
The Node.js Child Process API
Node.js包含一個 child_process 模組,它公開了建立和控制程序的健壯的API。有三個基本的呼叫來建立新的子程序——每個程序都有自己的用例。
第一個是 execFile,它接受(至少是)一個可執行程式的檔案路徑。您可以傳遞一個由程式呼叫的引數陣列。函式的最後一個引數是當程式終止時要執行的回撥。這個回撥會有一個錯誤,一個stdout緩衝區,以及一個給定的 stderr緩衝區,它可以用來查詢程式的輸出。需要注意的是,這個回撥只是在程式執行之後才呼叫。 execFile還返回一個表示子程序的物件,您可以將其寫入stdin流。
// standard node module
var execFile = require('child_process').execFile
// this launches the executable and returns immediately
var child = execFile("path to executable", ["arg1", "arg2"],
function (error, stdout, stderr) {
// This callback is invoked once the child terminates
// You'd want to check err/stderr as well!
console.log("Here is the complete output of the program: ");
console.log(stdout)
});
// if the program needs input on stdin, you can write to it immediately
child.stdin.setEncoding('utf-8');
child.stdin.write("Hello my child!\n");
我發現,當您必須自動化一個具有定義良好的輸入並以某種 “single phase”操作的應用程式時, execFile 函式是最好的,這意味著一旦您給它一些輸入,它就會中斷一段時間,然後轉儲所有的輸出。這正是主程式的型別,因此我們將在本章中使用execFile。
child_process 模組有兩個其他的函式來建立程序—— spawn 和 exec。 spawn 很像 execFile,它接受一個可執行檔案並啟動它。不同之處在於, spawn 將給您提供一個可用於stdout和stderr的可流介面。這對於更復雜的I/O場景非常有效,因為在您的node 程式碼和c++ app。 exec 非常類似於execFile, exec 通常用於shell程式(ls、pipes等)。
Synchronous選項
在 Node.js v0.12引入了一套新的API ,它允許您同步執行子應用程式——當您啟動子程序並在子程序終止之前,您的程式將會阻塞。如果您正在建立shell指令碼,那麼這是非常棒的,但它顯然不是用於web應用程式的。對於我們的質數演示,當然,當我們得到一個用於質數的HTTP請求時,我們需要等待完整的輸出,然後才能將結果頁面提供給瀏覽器——但是我們應該能夠在此期間繼續為其他瀏覽器提供其他HTTP請求!除非您有一個非常具體的原因,否則您將希望在編寫web伺服器時遠離spawnSync、 execSync和 execFileSync。
場景 1: C++ 帶參啟動
最簡單的 automate程式型別是一個程式,它將接受所有的輸入作為命令列引數,並將其輸出到stdout——因此我們將從這個場景開始。
那麼,讓我們“想象一下”主程式是這樣工作的(實際上,它已經基本做到了!)要使用該應用程式,我們可以鍵入:
$ primesieve 10
2
3
5
7
# {1 <= primes <= 10} = 4
0.000000000000 -3.464368964356
我們會把所有的質數都印到螢幕上(每行一個),再加上一些我們不需要的程式打印出來的額外資訊。
我將使輸出易於在我的所有示例中解析——很明顯,如果您的程式以一種嚴格的解析方式輸出資料,那麼您將有更多的工作要做。
用 node-gyp 編譯 C++ 主程式
我們的第一步是實際獲得一個可執行的c++應用程式 cpp/prime4standalone獨立的c++程式碼沒有一個入口點——它只是質數生成程式碼,它將在我們所覆蓋的所有3個場景中共享。在 cpp/standalone_stdio 中,我建立了一個入口點:
#include <iostream>
#include <stdio.h>
#include "prime_sieve.h"
using namespace std;
int main(int argc, char ** argvs) {
generate_args(argc, argvs, stdout);
}
下一步是構建c++可執行檔案——將所有三個檔案一起編譯。
cpp/standalone_stdio/main.cppcpp/prime4standalone/prime_sieve.hcpp/prime4standalone/prime_sieve.c如果您熟悉構建c++,那麼無論您喜歡的編譯器平臺是什麼,您都不會有問題。我們最終需要使用
node-gyp——因為我已經用這種方式設定了所有c++的例子。
$ node-gyp configure build
在 /cpp/standalone_stdio 你會找到一個 binding.gyp。這包含了用nodegyp構建這個特定示例所需的所有資訊——將其視為Makefile。
{
"targets": [
{
"target_name": "standalone",
"type": "executable",
"sources": [ "../prime4standalone/prime_sieve.c",
"main.cpp"],
"cflags": ["-Wall", "-std=c++11"],
"include_dirs" : ['../prime4standalone'],
"conditions": [
[ 'OS=="mac"', {
"xcode_settings": {
'OTHER_CPLUSPLUSFLAGS' : ['-std=c++11',
'-stdlib=libc++'],
'OTHER_LDFLAGS': ['-stdlib=libc++'],
'MACOSX_DEPLOYMENT_TARGET': '10.7' }
}
]
]
}
]
}
讓我們來介紹一些基礎知識。我們只定義了一個目標((“standalone”),因此它已經成為預設值。這裡的type 非常關鍵,因為Node -gyp還可以編譯動態庫、靜態庫庫、Node.js外掛。將 type 設定為 executable ,告訴nodegyp建立一個標準的可執行的可執行檔案。源陣列包含我們的源(不需要header,但是可以新增)。由於在本節後面的許多c++程式碼都將使用c++ 11,所以我還在cflags 屬性中傳遞了一些編譯器標誌。我還通過了OS X特定的東西,讓c++ 11在Mac上使用XCode。這些特殊選項包含在 conditions 屬性中,在Linux和Windows下被忽略。最後,我已經確保編譯器可以通過在 include_dirs 屬性下新增路徑找到包含檔案。
我們的構建命令node-gyp configure build 操作的應該在cpp/standalone_stdio/build/Release 中建立一個 standalone可執行檔案。您應該能夠直接從命令列執行它。現在讓我們從Node.js執行它。
Automating from Node.js
前面我們設定了一個非常簡單的Node.js web應用程式有一個單一的路由,可以使用純JavaScript主程式實現計算質數。現在我們將建立第二個使用c++實現的 route 。
首先在 cppwebify-tutorial/web/index.js 中,我們將在我們的型別陣列中為新的c++路徑新增一個新條目:
var types = [
{
title: "pure_node",
description: "Execute a really primitive " +
"implementation of prime sieve in Node.js"
},
{
title: "standalone_args",
description: "Execute C++ executable as a " +
"child process, using command " +
"line args and stdout. " +
"Based on /cpp/standalone_stdio"
}];
該型別陣列用於建立路由,查詢與 web/routes/目錄中的每個 title 屬性相同的檔案:
types.forEach(function (type) {
app.use('/'+type.title, require('./routes/' + type.title));
});
現在,讓我們在 /web/routes/standalone_args中新增我們的路由。如果您看一看,第1-9行基本上與 pure_nodeexample -第11行相同,在這裡,我們將通過執行c++應用程式來響應實際使用者對素數的請求:
router.post('/', function(req, res) {
var execFile = require('child_process').execFile
// we build this with node-gyp above...
var program = "../cpp/standalone_stdio/build/Release/standalone";
// from the browser
var under = parseInt(req.body.under);
var child = execFile(program, [under],
function (error, stdout, stderr) {
// The output of the prime_sieve function has
// one prime number per line.
// The last 3 lines are additional information,
// which we aren't using here - so I'm slicing
// the stdout array and mapping each line to an int.
// You'll want to be more careful parsing your
// program's output!
var primes = stdout.split("\n").slice(0, -3)
.map(function (line) {
return parseInt(line);
});
res.setHeader('Content-Type', 'application/json');
res.end(JSON.stringify({
results: primes
}));
console.log("Primes generated from " + type);
});
});
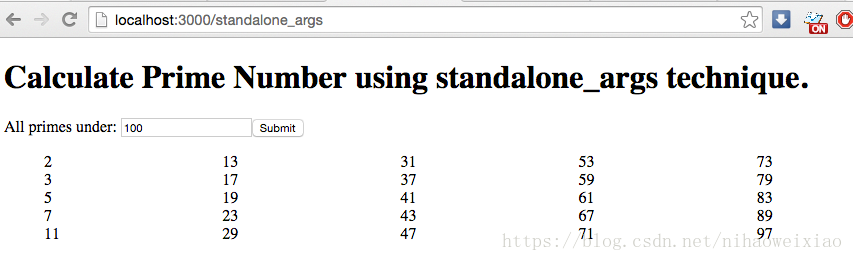
在處理程式輸出(以及處理來自瀏覽器的輸入)時,您可能需要更健壯一些,因為您可以看到,呼叫子程序並返回對瀏覽器的響應非常簡單。通過 node index.js 執行web應用程式。在 cppwebify-tutorial/web 下的終端中,將瀏覽器指向http://localhost:3000/。選擇 “standalone_args”策略,您可以輸入100以獲得100以下的所有質數——這一次使用一個更快的基於c的實現!
場景 2: C++程式從標準輸入獲取資料
很多程式會詢問實際使用者的輸入。如果您能夠訪問您的程式的程式碼,那麼可能很容易更改它,因此它接受這些輸入作為命令列args——這意味著您可以只使用場景1中的策略。有時候這是行不通的——如果你連原始碼都沒有!當自動執行一個與使用者對話的程式時,它也不起作用,你需要通過node來模擬。不過,不必擔心——寫入stdin非常簡單,特別是如果您不需要等待來自子程序的任何輸出(如果您這樣做的話,請檢查spawn 而不是 execFile )。
C++
在 cpp/standalone_usr 中,我已經為一個c++程式建立了一個新的入口點,它簡單地要求使用者根據主程式的演算法輸入所需的引數。
#include <iostream>
#include <stdio.h>
#include "prime_sieve.h"
using namespace std;
int main(int argc, char ** argvs) {
int max;
cout << "Please enter the maximum number: ";
cin >> max;
generate_primes(max, stdout);
}
它包含了同樣的 prime_sieve.h 檔案作為場景1中的程式碼,並且具有非常相似的 binding.gyp 檔案。在終端/獨立終端上通過 node-gyp configure build 配置構建cpp/standalone_usr。
通過Node.js標準輸入
現在我們有了一個新的可執行的構建,它要求來自實時使用者的輸入。我們現在可以在我們的web應用程式中加入另一條路線來實現這一功能的自動化。在 web/index.js 中我們將建立另一個型別條目:
var types = [
{
title: "pure_node",
description: "Execute a really primitive " +
"implementation of prime sieve in Node.js"
},
{
title: "standalone_args",
description: "Execute C++ executable as a " +
" child process, using command line "+
" args and stdout. " +
" Based on /cpp/standalone_stdio"
},
{
title: "standalone_usr",
description: "Execute C++ executable as a " +
" child process, using direct user input. "+
" Based on /cpp/standalone_usr"
}];
我們將在 web/routes/standalone_usr.js中建立一條新路由。在這個檔案中,我們的程式碼將不再作為命令列引數傳遞,相反,我們將寫入stdin:
router.post('/', function(req, res) {
var execFile = require('child_process').execFile
// notice we're pointing this to the new executable
var program =
"../cpp/standalone_usr/build/Release/standalone_usr";
var under = parseInt(req.body.under);
// execFile will return immediately.
var child = execFile(program, [],
function (error, stdout, stderr) {
// This function is executed once the program ends
var primes = stdout.split("\n").slice(0, -3)
.map(function (line) {
return parseInt(line);
});
res.setHeader('Content-Type', 'application/json');
res.end(JSON.stringify({
results: primes
}));
console.log("Primes generated from " + type);
});
// now we write "under" to stdin so the C++ program
// can proceed (it's blocking for user input)
child.stdin.setEncoding('utf-8');
child.stdin.write(under + "\n");
// Once the stdin is written, the C++ completes
// and the callback above is invoked.
});
現在你可能已經有了這個想法。再次啟動web應用程式,現在您將在開始頁面上有第三個條目——繼續進行測試。
場景三 3: 從檔案中輸入 C++ 程勳
我要講的最後一個場景是,您正在自動化的程式從一個檔案中獲取輸入,並將其輸出轉儲到另一個檔案中。當然,您的場景可能是這裡討論的三種場景的組合——您的場景可能涉及到輸入/輸出的固定檔名,或者指定的使用者(通過stdin或命令列引數)。無論你的情況如何,你都可以應用這裡的東西。
輸入輸出儲存在檔案中
因此,第一步是將主程式變成類似於檔案的程式。如果您看一下 cpp/standalone_flex_file,我已經建立了一個主程式的第三個入口點,它可以在命令列中接受輸入/輸出檔名。輸入檔案被假定為在第一行中簡單地有 “under” 。輸出檔案將收到與之前的stdin相同的結果行。
#include <iostream>
#include <stdio.h>
#include "prime_sieve.h"
using namespace std;
// Simulating a legacy app that reads
// it's input from a user-specified file via command line
// arguments, and outputs to a similarly specified file.
int main(int argc, char ** argvs) {
FILE * in = fopen(argvs[1], "r");
int i;
fscanf (in, "%d", &i);
fclose(in);
FILE * out = fopen(argvs[2], "w");
generate_primes(i, out);
fprintf(stdout, "Output saved in %s\n", argvs[2]);
fclose(out);
}
我們可以通過 node-gyp configure build 配置構建cpp/standalone_flex_file.這個C++程式。這將產生一個我們可以從node使用的目標可執行檔案。
深入瞭解web檔案讀寫
在進入 Node.js之前,對於這個場景,我們來討論一下基於檔案的程式所涉及的挑戰。大多數應用程式從來沒有為web服務,它會讀取指定的輸入檔案,並將其寫入輸出檔案,就好像應用程式是唯一執行的一樣。就好像它不是和同一個程式的另一個例項一起執行!當這些應用程式是手動執行的時候,這是有意義的——但是如果您將它們放在web上,您可以很容易地同時發出多個併發請求(來自不同的瀏覽器)。重要的是,這些同步執行的遺留C++程式不會相互衝突——您需要確保它們正在讀取和寫入它們自己的不同檔案!
當您無法訪問遺留原始碼時,這可能是說比做容易,特別是如果應用程式不允許使用者指定檔案(也就是說,它們在程式中是硬編碼的!)如果它們是硬編碼的,但是相對的檔案路徑,那麼您可以使用當前的工作目錄來玩操作,或者在每個傳入的web請求的臨時目錄中建立可執行檔案的副本(或連結到它)。這是一項昂貴的開銷,但它確實有效。如果檔案路徑硬編碼到絕對路徑,那麼您就有一個問題(找到程式碼!)
我模擬了最簡單(但最常見的)情況,其中輸入和輸出檔案可以由使用者指定(在本例中,通過命令列引數)。我們所需要做的就是確保啟動C++應用程式的每個web請求都選擇唯一的檔名——我通常通過在每個web請求上建立臨時目錄來實現這一點,將輸入/輸出檔案放在臨時目錄中。這將保護每個正在執行的例項,同時保持輸入/輸出名稱的一致性。
現在讓我們跳過Node.js 的路由。在 web/routes/standalone_file.js的頂部,我需要這個引入temp 模組,我用它來處理臨時目錄和檔案的建立。它會在適當的位置放置你的平臺的臨時位置。
var temp = require('temp');
下面是在 web/routes/standalone_file.js中實現的路由程式碼。
router.post('/', function(req, res) {
var execFile = require('child_process').execFile
var program =
"../cpp/standalone_flex_file/build"+
"/Release/standalone_flex_file";
var under = parseInt(req.body.under);
// Create a temporary directory, with
// node_example as the prefix
temp.mkdir('node_example', function(err, dirPath) {
// build full paths for the input/output files
var inputPath = path.join(dirPath, 'input.txt');
var outputPath = path.join(dirPath, 'output.txt');
// write the "under" value to the input files
fs.writeFile(inputPath, under, function(err) {
if (err) throw err;
// once the input file is ready, execute the C++
// app with the input and output paths
// specified on the command line
var primes = execFile(program,
[inputPath, outputPath], function(error) {
if (error ) throw error;
fs.readFile(outputPath, function(err, data) {
if (err) throw err;
var primes = data.toString().split('\n')
.slice(0, -3)
.map(function (line) {
return parseInt(line);
});
res.setHeader('Content-Type', 'application/json');
res.end(JSON.stringify({
results: primes
}));
exec('rm -r ' + dirPath, function(error) {
if (error) throw error;
console.log("Removed " + dirPath);
})
});
});
});
});
});
上面的程式碼首先建立臨時目錄。然後,它編寫輸入檔案,並以輸入和輸出檔案路徑作為命令列引數啟動子程序。一旦流程完成,我們將讀取輸出檔案以獲得結果,並像以前一樣將其返回給瀏覽器。最後,我們通過刪除父目錄來清理臨時檔案。這一點很重要,因為即使臨時模組允許跟蹤和自動刪除臨時檔案,它只會在程序終止時清除這些檔案。由於這是一個web應用程式,我們將(希望!)等待很長一段時間才會發生這種情況。
正如您所看到的,這段程式碼將受益於更好的控制流模式(async, promises, etc)。我試著堅持最低限度,我把這個留給你們:)。
除了上面的route 之外,我已經將這個最終場景新增到 web/index.js的 types陣列中,你可以啟動你的web應用程式,並像其他的一樣測試這個。
Node.js直接呼叫已經存在的C++ DLL
本節將完全集中於將您的C++編譯成一個共享庫或DLL,並從Node.js呼叫該程式碼。使用 FFI。我還將討論在嘗試將遺留C++應用程式轉換成可呼叫共享庫時遇到的一些常見問題。
當使用automation一個C++應用程式時,您有一個優勢,那就是在JavaScript和C++之間進行真正的分離。automation還允許您與幾乎所有的程式語言進行整合——只要它可以通過stdin/stdout或輸入和輸出檔案實現automation。一個缺點是,實際上只有一個入口點到你的C++-main。您當然可以在C++和節點應用程式之間開發複雜的協調,但是當您只想向C++傳送一些輸入並等待結果時,automation是最有效的。
通常您需要細粒度控制和協調 Node.js和c++。你希望能夠通過函式呼叫C++,而不僅僅是一個可執行的入口點。此外,您希望能夠從這些函式中獲得輸出作為返回值(或參考引數),而不是從stdout或某個輸出檔案中獲取輸出。
在這種情況下,共享庫(或DLL)是一個很好的解決方案。如果您的C++已經在一個DLL中,那麼您可以立即開始——但是如果不是,您通常可以很容易地將您的遺留程式碼編譯成一個DLL——您只需要知道您希望向呼叫者公開哪些方法/函式。一旦您有了一個DLL,就可以通過 Node.js很簡單使用介面(繼續讀下去!)
當automation過於繁瑣時,將遺留的C或C++應用程式轉換為DLL是一個很好的整合選擇。它還可以讓您避免使用V8 API開發Node的複雜性,這並不總是微不足道的。
對於這個特定的部分,請簽出dll標籤
一旦您簽出了程式碼,請花一點時間來檢查我設定的目錄結構。在/cpp 目錄中,我將所有為automation示例開發的C++應用程式都放在了這裡,在 /cpp/prime4standalone單機中使用了素數生成的共享源。現在,我們需要修改質數程式碼,使其能夠很好地作為一個DLL,我將把程式碼放入 /cpp/prime4lib中。與前面的情況一樣,示例web應用程式在 web中。我們將在這篇文章中新增一條路由(ffi))——用於共享庫實現。
C++ 動態庫
如果您試圖將現有的共享庫整合到Node.js中,然後你可以跳過這部分——你都準備好了!如果您有一些遺留的C++程式碼,它最初是一個獨立的應用程式(或者一部分),那麼您需要先準備好程式碼作為共享庫。這樣做的主要考慮是定義您的API——由主機程式碼(在我們的例子中,node.js)可以呼叫的一系列函式。也許您的C++已經組織好了,這些功能已經準備好了——但是您可能需要進行一些重組。
另一個主要考慮因素是如何獲得C++程式碼的輸出。例如,在automation時,我從Node運行了一堆獨立的primesieve應用程式,每個應用程式都可以直接輸出到標準輸出或輸出檔案。不過,我們不希望共享庫——我們希望輸出返回給呼叫者。要做到這一點,你可能需要有點創意——我將向你展示我在下面這一節中是如何做到的。
這是我想要共享庫支援的API。實際上,它並不是一個API——它只是一個函式!
int getPrimes(int under, int primes[]);
第一個引數表示最大值——這樣我們就能找到這個值下的所有質數。質數將被塞進第二個引數——一個數組。假設這個陣列有足夠的空間來儲存所有生成的質數(under 是一個好的”maximum”大小)。這個函式會返回實際找到的質數數目。
捕捉輸入
現在讓我們看一下自動化示例中的程式碼。在 /cpp/prime4standalone中, primesieve.c 檔案有一個主要功能:
int generate_args(int argc, char * argv[], FILE * out)
它還有一個介面卡功能,可以用 under.替換argc/argv引數。在這兩種情況下,請注意輸出是通過 fprintf把結果寫進引用型別引數out 。對於我們的API,我們希望將輸出放在一個數組中。
一種方法可能是開始對底層的primesieve實現進行修改,用一些程式碼替換 fprintf 呼叫來載入一個數組。這是可以工作的(特別是如果這是新的C++程式碼,或者至少是C++,這是相當簡單的),但是它不是特別可伸縮的(如果您需要執行一些更復雜的操作來捕獲輸出呢?)我發現對遺留程式進行修改是最好的,當您保持簡單的更改時——這就是我在這裡要做的。
資料型別C++轉換類
就像生活中的大多數事情一樣,保持一件簡單的事情往往會讓事情變得更復雜。我的目標是在現有的primeseive程式碼中替換每個 fprintf 語句,並使用一個類似的簡單函式:
void pass(int prime);
我希望傳送函式能夠將素數新增到一個數組中,陣列是從呼叫的Node.js中傳送過來的。
// called from Node.js - calls to send should add prime to primes
int getPrimes(int under, int primes[]);
這看起來很簡單,我們可以通過傳送一個物件的成員方法來獲得這樣的東西,該物件可以引用陣列。不過,primeseive是直接的C程式碼,這讓事情變得複雜起來。
讓我們從交換的資料交換類 exchange.h:
#define _exchangeclass
#include <iostream>
#include <functional>
using namespace std;
class exchange {
public:
exchange(const std::function<void (void * )> & c) {
this->callback = c;
}
void send(int data){
this->callback(&data);
}
private:
std::function<void (void * )> callback;
};
#include "c_exchange.h"
您首先要注意的是,該類本身並不包含對陣列的引用。為了保持它的一般化,我只是讓它擁有一個回撥函式——它將負責在本例中儲存給定值給陣列,但是可以做任何事情。
注意最後一行——我包括一個單獨的標頭檔案,叫做 c_exchange.h。send 成員不能從C程式碼(primesieve)中呼叫,您可能已經猜到了, c_exchange.h 包含一個函式來解決這個問題。讓我們看看裡面:
#ifdef _exchangeclass
extern "C" {
#endif
void pass(void * exchanger, int data);
#ifdef _exchangeclass
}
#endif
首先,這個頭將被C++和C程式碼包含進來。 exchange.h它宣告交換類定義了交換器符號——所以第一行就是exchangeclass標識是否已經定義。如果是,將從C呼叫的 pass function 包裝在一個 extern 塊中。
pass 函式接受一個指向交換物件的指標((void *,因為 exchange 類對C呼叫者是不可見的)。在定義中,找到 exchange.cpp,我們看到這個指標被轉換回一個exchange 物件,send方法被呼叫:
void pass(void * exchanger, int data) {
exchange * xchg = (exchange * ) exchanger;
xchg->send(data);
}
這有點複雜,但是 exchange 類和它的獨立 pass 助手函式可以被放入幾乎任何現有的C++或C遺留程式中,只要將一個指標指向一個 exchange物件到遺留程式碼,並通過 pass替換輸出呼叫即可。讓我們用 primesieve.c來做這個。
修改質數分解服務
在 /cpp/prime4lib 中有一個修改過的 primesieve.h和 primesieve.c。 old primesieve.h定義了以下兩個函式:
// primeseive.h for standalone programs
int generate_args(int argc, char * argv[], FILE * out);
int generate_args(int under, FILE * out);
現在我用下面的簽名替換了這些簽名:
// primesieve.h for library calls
int generate_args(int argc, char * argv[], void * out);
int generate_args(int under, void * out);
primeseive.c 內部。舊的獨立程式碼有一個 #define設定來使用fprintf,在第43行(注意,我不是原始的 l primsieve code 的作者——我不知道這個複雜的列印方案背後的歷史或意圖。和大多數傳統應用一樣,有時候這些問題最好還是沒有被要求!)我們現在用一個 pass(out, x)呼叫來替換 fprintf(out, UL"\n",x) 。
動態庫入口
現在我們有了一個primesieve.h/primeseive.c 使用 pass的c實現,我們只需要建立一個C++入口點來建立一個 exchange 物件並呼叫primesieve程式碼。我已經在/cpp/lib4ffi/primeapi.h 和 /cpp/lib4ffi/primeapi.cpp中完成了這個任務。
primeapi.h 是共享庫入口點,它有我想要的庫API函式的宣告:
extern C {
int getPrimes(int under, int primes[]);
}
實現使用 exchange 類,lambda函式作為回撥函式。正如您所看到的,lambda函式會將傳送到陣列的任何資料新增到陣列中。
int getPrimes(int under, int primes[]) {
int count = 0;
exchange x(
[&](void * data) {
int * iptr = (int * ) data;
primes[count++] = * iptr;
}
);
generate_primes(under, (void*)&x);
return count;
}
現在,當我們呼叫 primesieve.h中定義的 generate_primes。我們把我們的exchange作為參考。在 primesieve.c 中 out是對exchange 物件的引用。在 primesieve.c 中所有 pass(out, x) 呼叫都是通過out物件為 exchange物件(在 exchange.cpp)中,並且回撥(lambda)被觸發。最終的結果是,primesieve計算的所有值都在素數陣列中找到。
通過gyp連結C++動態度
我們現在需要構建我們的共享庫。幸運的是,我們習慣使用的工具集—— node-gyp ——也可以幫助我們。在 /cpp/lib4ffi 中,您將找到另一個名為binding.gyp的配置檔案。它與自動化示例中的獨立示例中的gyp檔案非常相似,但是它連結了 /cpp/prime4lib中的primesieve檔案,而不是 /cpp/prime4standalone ,