
阿里雲上部署java8和hadoop3.0、spark、hive及Mahout
阿新 • • 發佈:2019-01-23
1.安裝JDK1.8
到oracle官網:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 安裝及配置參考http://blog.csdn.net/rchm8519/article/details/48721913/usr/jdk就是一個連結目錄。實際的java目錄為/usr/java
2.安裝Hadoop3.0
到hadoop官網:http://hadoop.apache.org/releases.html這裡我選擇的是最新版Hadoop3.0 alpha3 binary版本。注 意source版本是需要自己編譯的,而binary是已經編譯好,可以直接執行的。 下面是binary版本的下載地址: http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.0.0-alpha3/hadoop-3.0.0-alpha3.tar.gz
將解壓目錄移動到/usr/local,並重命名:tar -xzvf hadoop-3.0.0-alpha3.tar.gz
mv /download/hadoop-3.0.0-alpha3 /usr/local/hadoop接下來就修改hadoop配置檔案: http://www.cnblogs.com/hehaiyang/p/4477626.html#label_2
檔案路徑為/usr/local/hadoop/etc/hadoop/,配置hadoop-env.sh。

中間3行export是我新增的。 然後再次修改/etc/profile,
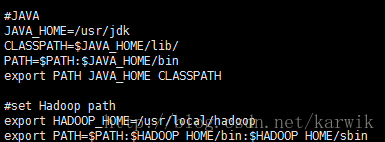
新增下面的兩句。 OK。 然後設定免密登陸,生成ssh金鑰。
ssh-keygen -t rsassh-copy-id localhost 此時會顯示hadoop文件 對於要偽分散式執行,要配置core-site.xml和hdfs-site.xml檔案,參考:hadoop
core-site.xml <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://Master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> </configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>嘗試偽分散式執行,出錯提示: ERROR: Attempting to launch hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting launch.
按如下網站方法解決: https://www.vastyun.com/bloger/179.html成功執行。