
ddyyxx的程式設計師之路
KMP演算法是一種線性時間複雜度的字串匹配演算法,它是對BF(Brute-Force,最基本的字串匹配演算法)的改進。對於給定的原始串S和模式串T,需要從字串S中找到字串T出現的位置的索引。KMP演算法由D.E.Knuth與V.R.Pratt和J.H.Morris同時發現,因此人們稱它為Knuth--Morris--Pratt演算法,簡稱KMP演算法。在講解KMP演算法之前,有必要對它的前身--BF演算法有所瞭解,因此首先將介紹最樸素的BF演算法。
一:BF演算法簡介

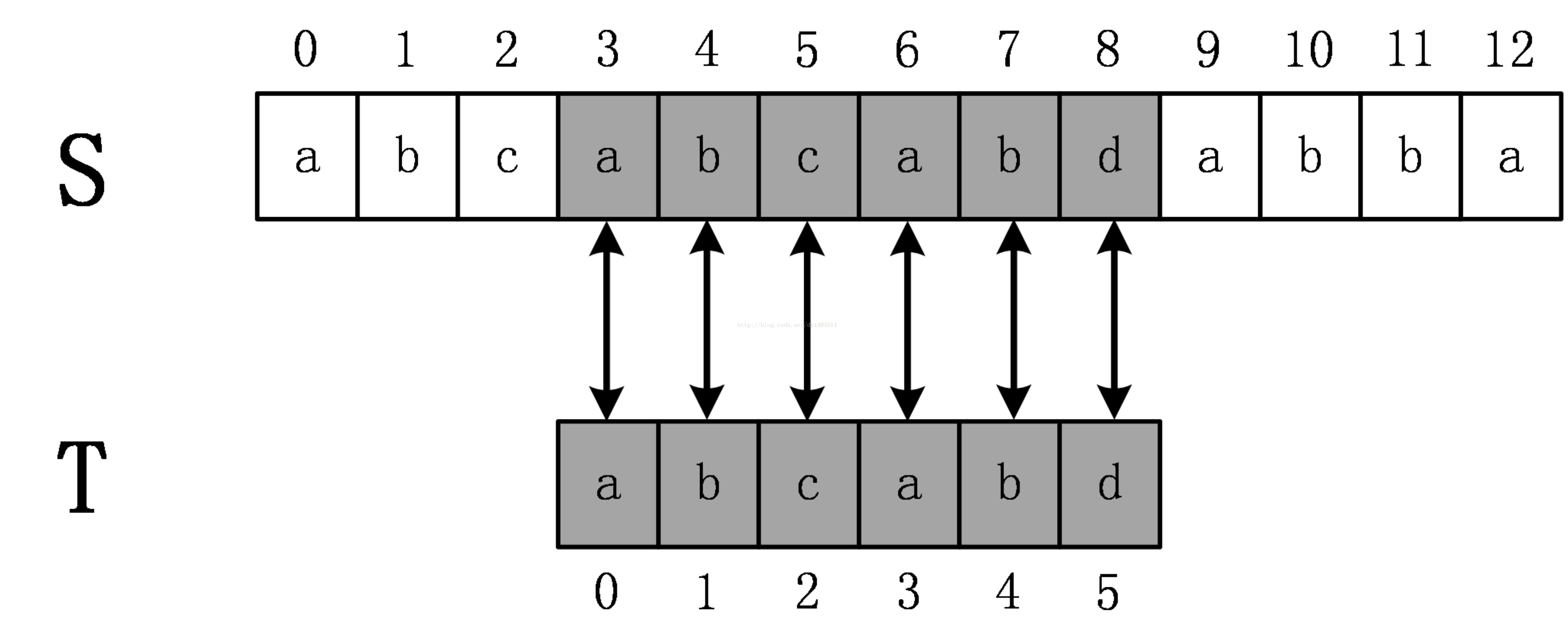
如上圖所示,原始串S=abcabcabdabba,模式串為abcabd。(下標從0開始)從s[0]開始依次比較S[i] 和T[i]是否相等,直到T[5]時發現不相等,這時候說明發生了失配,在BF演算法中,發生失配時,T必須回溯到最開始,S下標+1,然後繼續匹配,如下圖所示:

這次立即發生了失配,所以繼續回溯,直到S開始下表增加到3,匹配成功。
容易得到,BF演算法的時間複雜度是O(n*m)的,其中n為原始串的長度,m為模式串的長度。BF的程式碼實現也非常簡單直觀,這裡不給出,因為下一個介紹的KMP演算法是BF演算法的改進,其時間複雜度為線性O(n+m),演算法實現也不比BF演算法難多少。
二:KMP演算法
前面提到了樸素匹配演算法,它的優點就是簡單明瞭,缺點當然就是時間消耗很大,既然知道了BF演算法的不足,那麼就要對症下藥,設計一種時間消耗小的字串匹配演算法。
KMP演算法就是其中一個經典的例子,它的主要思想就是:
在匹配匹配過程中發生失配時,並不簡單的從原始串下一個字元開始重新匹配,而是根據一些匹配過程中得到的資訊跳過不必要的匹配,從而達到一個較高的匹配效率。
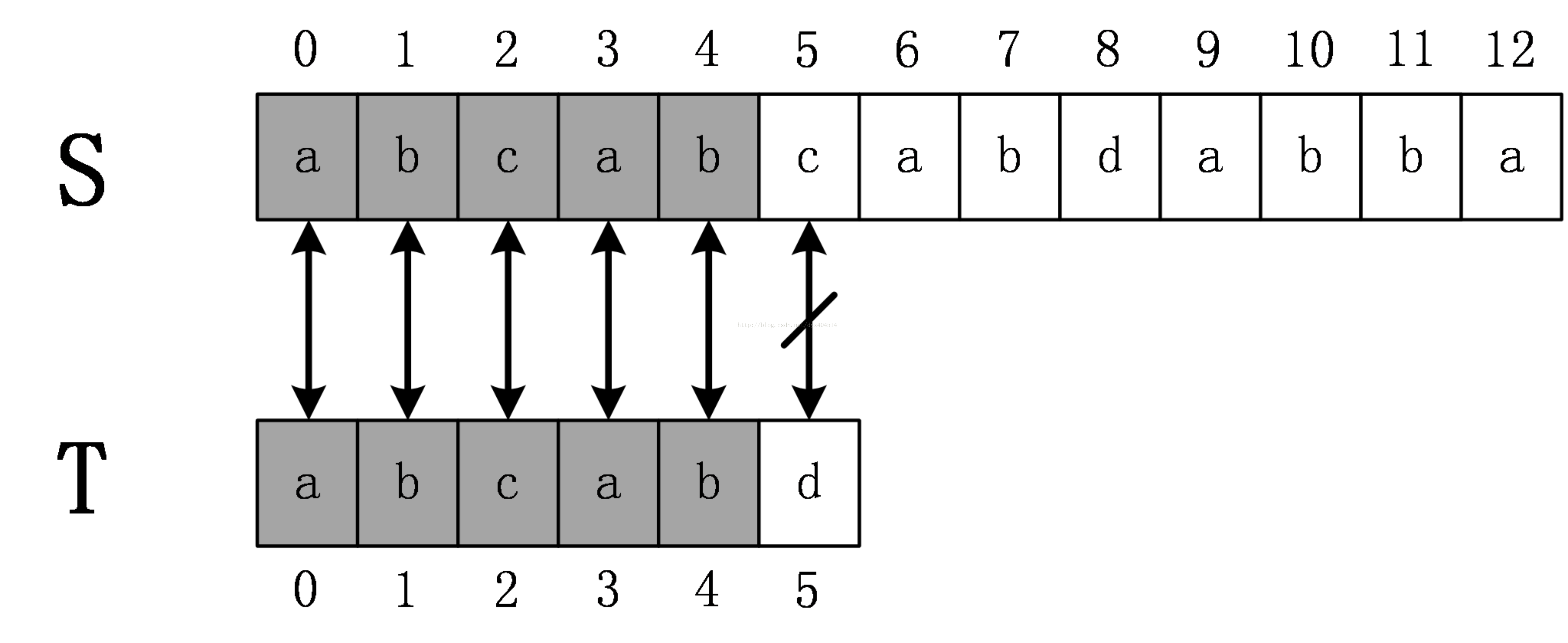
還是前面的例子,原始串S=abcabcabdabba,模式串為abcabd。當第一次匹配到T[5]!=S[5]時,KMP演算法並不將T的下表回溯到0,而是回溯到2,S下標繼續從S[5]開始匹配,直到匹配完成。
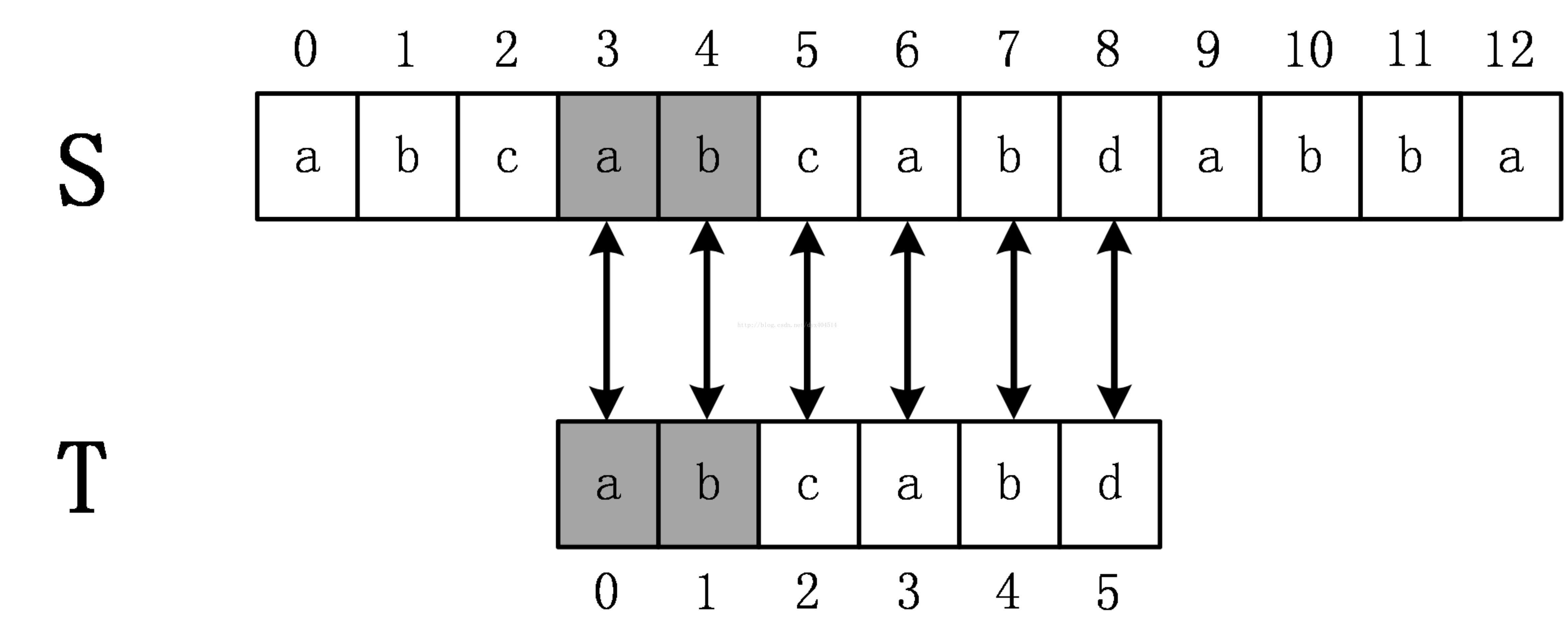
那麼為什麼KMP演算法會知道將T的下標回溯到2呢?前面提到,KMP演算法在匹配過程中將維護一些資訊來幫助跳過不必要的檢測,這個資訊就是KMP演算法的重點 --next陣列。(也叫fail陣列,字首陣列)。
1:next陣列
(1)next陣列的定義:
設模式串T[0,m-1],(長度為m),那麼next[i]表示既是是串T[0,i-1]的字尾又是串T[0,i-1]的字首的串最長長度(不妨叫做前後綴),注意這裡的字首和字尾不包括串T[0,i-1]本身。
如上面的例子,T=abcabd,那麼next[5]表示既是abcab的字首又是abcab的字尾的串的最長長度,顯然應該是2,即串ab。注意到前面的例子中,當發生失配時T回溯到下表2,和next[5]陣列是一致的,這當然不是個巧合,事實上,KMP演算法就是通過next陣列來計算髮生失配時模式串應該回溯到的位置。
(2)next陣列的計算:
這裡介紹一下next陣列的計算方法。
設模式串T[0,m-1],長度為m,由next陣列的定義,可知next[0]=next[1]=0,(因為這裡的串的字尾,字首不包括該串本身)。
接下來,假設我們從左到右依次計算next陣列,在某一時刻,已經得到了next[0]~next[i],現在要計算next[i+1],設j=next[i],由於知道了next[i],所以我們知道T[0,j-1]=T[i-j,i-1],現在比較T[j]和T[i],如果相等,由next陣列的定義,可以直接得出next[i+1]=j+1。
如果不相等,那麼我們知道next[i+1]<j+1,所以要將j減小到一個合適的位置po,使得po滿足:
1)T[0,po-1]=T[i-po,i-1]。
2)T[po]=T[i]。
3)po是滿足條件(1),(2)的最大值。
4)0<=po<j(顯然成立)。
如何求得這個po值呢?事實上,並不能直接求出po值,只能一步一步接近這個po,尋找當前位置j的下一個可能位置。如果只要滿足條件(1),那麼j就是一個,那麼下一個滿足條件(1)的位置是什麼呢?,由next陣列的定義,容易得到是next[j]=k,這時候只要判斷一下T[k]是否等於T[i],即可判斷是否滿足條件(2),如果還不相等,繼續減小到next[k]再判斷,直到找到一個位置P,使得P同時滿足條件(1)和條件(2)。我們可以得到P一定是滿足條件(1),(2)的最大值,因為如果存在一個位置x使得滿足條件(1),(2),(4)並且x>po,那麼在回溯到P之前就能找到位置x,否則和next陣列的定義不符。在得到位置po之後,容易得到next[i+1]=po+1。那麼next[i+1]就計算完畢,由數學歸納法,可知我們可以求的所有的next[i]。(0<=i<m)
注意:在回溯過程中可能有一種情況,就是找不到合適的po滿足上述4個條件,這說明T[0,i]的最長前後綴串長度為0,直接將next[i+1]賦值為0,即可。
//計算串str的next陣列
int GETNEXT(char *str,int next)
{
int len=strlen(str);
next[0]=next[1]=0;//初始化
for(int i=1;i<len;i++)
{
int j=next[i];
while(j&&str[i]!=str[j])//一直回溯j直到str[i]==str[j]或j減小到0
j=next[j];
next[i+1]=str[i]==str[j]?j+1:0;//更新next[i+1]
}
return len;//返回str的長度
}2.KMP匹配過程
有了next陣列,我們就可以通過next陣列跳過不必要的檢測,加快字串匹配的速度了。那麼為什麼通過next陣列可以保證匹配不會漏掉可匹配的位置呢?
首先,假設發生失配時T的下標在i,那麼表示T[0,i-1]與原始串S[l,r]匹配,設next[i]=j,根據KMP演算法,可以知道要將T回溯到下標j再繼續進行匹配,根據next[i]的定義,可以得到T[0,j-1]和S[r-j+1,r]匹配,同時可知對於任何j<y<i,T[0,y]不和S[r-y,r]匹配,這樣就可以保證匹配過程中不會漏掉可匹配的位置。
同next陣列的計算,在一般情況下,可能回溯到next[i]後再次發生失配,這時只要繼續回溯到next[j],如果不行再繼續回溯,最後回溯到next[0],如果還不匹配,這時說明原始串的當前位置和T的開始位置不同,只要將原始串的當前位置+1,繼續匹配即可。
下面給出KMP演算法匹配過程的程式碼:
//返回S串中第一次出現模式串T的開始位置
int KMP(char *S,char *T)
{
int l1=strlen(S),l2=GETNEXT(T);//l2為T的長度,getnext函式將在下面給出
int i,j=0,ans=0;
for(i=0;i<l1;i++)
{
while(j&&S[i]!=T[j])//發生失配則回溯
j=next[j];
if(S[i]==T[j])
j++;
if(j==l2)//成功匹配則退出
break;
}
if(j==l2)
return i-l2+1;//返回第一次匹配成功的位置
else
return -1;//若匹配不成功則返回-1
}3.時間複雜度分析
前面說到,KMP演算法的時間複雜度是線性的,但這從程式碼中並不容易得到,很多讀者可能會想,如果每次匹配都要回溯很多次,是不是會使演算法的時間複雜度退化到非線性呢?
其實不然,我們對程式碼中的幾個變數進行討論,首先是kmp函式,顯然決定kmp函式時間複雜度的變數只有兩個,i和j,其中i只增加了len次,是O(len)的,下面討論j,因為由next陣列的定義我們知道next[j]<j,所以在回溯的時候j至少減去了1,並且j保證是個非負數。另外,由程式碼可知j最多增加了len次,且每次只增加了1。簡單來說,j每次增加只能增加1,每次減小至少減去1,並且保證j是個非負數,那麼可知j減小的次數一定不能超過增加的次數。所以,回溯的次數不會超過len。綜上所述,kmp函式的時間複雜度為O(len)。同理,對於計算next陣列同樣用類似的方法證明它的時間複雜度為O(len),這裡不再贅述。對於長度為n的原始串S,和長度為m的模式串T,KMP演算法的時間複雜度為O(n+m)。
到這裡,KMP演算法的實現已經完畢。但是這還不是最完整的的KMP演算法,真正的KMP演算法需要對next陣列進行進一步優化,但是現在的演算法已經達到了時間複雜度的下線,而且,現在的next陣列的定義保留了一些非常有用的性質,這在解決一些問題時是很有幫助的。
對於優化後的KMP演算法,有興趣的朋友可以自行查閱相關資料。