
8.HashMap新增的物件為什麼要重寫equals和hashcode
淺談HashMap以及重寫hashCode()和equals()方法
因為,equals()方法只比較兩個物件是否相同,相當於==,而不同的物件hashCode()肯定是不同,所以如果我們不是看物件,而只看物件的屬性,則要重寫這兩個方法,如Integer和String他們的equals()方法都是重寫過了,都只是比較物件裡的內容。使用HashMap,如果key是自定義的類,就必須重寫hashcode()和equals()。
一般先寫hashCode再寫equals。因為它返回的是物件的雜湊值,那麼不同的new出不同的物件,他們雖然名字一樣但是雜湊碼可能會不一樣。
為了闡明其作用,我們先來假設有如下一個Person
1. class Person {
2. public Person(String name, int age) {
3. this.name = name;
4. this.age = age;
5. }
6. private String name;
7. private int age;
8.
9. public String getName() {
10. return name;
11. }
12. public void setName(String name) {
13. this.name = name;
14. }
15.
16. return age;
17. }
18. public void setAge(int age) {
19. this.age = age;
20. }
21. public String toString() {
22. return "{" + name + ", " + age + "}";
23. }
24. }
現在有很多Person類的物件需要儲存,很自然聯想到用HashSet來儲存,於是乎,寫了下面的程式來測試一下:
1. import java.util.*;
2.
3. public
4. public static void main(String[] args) {
5. Collection set = new HashSet();
6. set.add(new Person("張三", 21));
7. set.add(new Person("李四", 19));
8. set.add(new Person("王五", 22));
9. set.add(new Person("張三", 21));
10. sop(set);
11. }
12. private static void sop(Collection set) {
13. Iterator it = set.iterator();
14. while (it.hasNext()) {
15. Person p = it.next();
16. System.out.println(p.toString());
17. }
18. }
19. }
在儲存的時候,我故意存了兩個“21歲的張三”,我的本意是這是同一個人,也就是說set集合裡面只需要出現一個“21歲的張三”,可事實是:
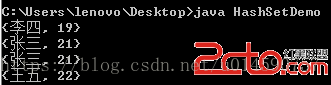
出現了兩個一樣的張三,為什麼會這樣呢?
其實,在往HashSet集合放置元素時,會根據其hashCode來判斷兩個元素是否一樣,如果是一樣,這後者覆蓋前者。而hashCode預設是比較其地址值。於是,對於兩個new 出來的“21歲的張三”,其地址值不一樣,所以HashSet才將兩個均加入其中。
1. class Person {
2.
3. //都一樣,變化的就是下面的
4. publicint hashCode() {
5. return name.hashCode() + age * 10;
6. }
7.
8. publicboolean equals(Object obj) {
9. if (!(obj instanceof Person))
10. thrownew ClassCastException("型別不匹配");
11. Person p = (Person) obj;
12. returnthis.name.equals(p.getName()) && this.age == p.getAge();
13. }
14. }
此時,再執行重寫,結果如下:
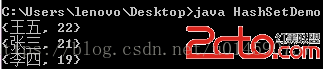
總結:一般對於存放到Set集合或者Map中鍵值對的元素,需要按需要重寫hashCode與equals方法,以保證唯一性!
如果你過載了equals,比如說是基於物件的內容實現的,而保留hashCode的實現不變,那麼很可能某兩個物件明明是“相等”,而hashCode卻不一樣。
這樣,當你用其中的一個作為鍵儲存到hashMap、hasoTable或hashSet中,再以“相等的”找另一個作為鍵值去查詢他們的時候,則根本找不到(因為找的過程中是通過key值對應的hash值去尋找的)。
對於每一個物件,通過其hashCode()方法可為其生成一個整形值(雜湊碼),該整型值被處理後,將會作為陣列下標,存放該物件所對應的Entry(存放該物件及其對應值)。 equals()方法則是在HashMap中插入值或查詢時會使用到。當HashMap中插入值或查詢值對應的雜湊碼與陣列中的雜湊碼相等時,則會通過equals方法比較key值是否相等,所以想以自建物件作為HashMap的key,必須重寫該物件繼承object的hashCode和equals方法。
put的原始碼的關鍵部分
for(Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if(e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
returnoldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
returnnull;
還有一點,位置0上存放的一定是null。
然後在遍歷這個位置上的連結串列的過程中,如果發現在已經存在由equal函式確定的相等的Key,那麼用新的Value替換掉老的Value,並返回老的Value。不然就在連結串列最後新增結點,並返回null。
看一下get的原始碼
public V get(Object key) {
if (key== null)
returngetForNullKey();
Entry<K,V> entry = getEntry(key);
returnnull == entry ? null : entry.getValue();
}
再看getEntry的原始碼
final Entry<K,V> getEntry(Object key) {
if (size== 0) {
returnnull;
}
int hash= (key == null) ? 0 : hash(key);
for(Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if(e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
returnnull;
}
意思很明確,就是先用hash函式確定在哪個位置,然後遍歷這個位置上對應的連結串列,直到找到這個Key,然後返回value 這裡有個地方很關鍵,那就是如何判判斷相等我們看到這裡是靠equal函式來判斷的,equal函式是所有類都會從Object類處繼承的函式,
當我們在HashMap中儲存我們自己定義的類的時候,預設的equal函式的行為可能不能符合我們的要求,所以需要重寫。
總結:
1、如果兩個物件相同(即用equals比較返回true),那麼它們的hashCode值一定要相同;
2、如果兩個物件的hashCode相同,它們並不一定相同(即用equals比較返回false)
先寫hashCode再寫equals
再來一次:
就必須重寫hashCode的原理分析
因為最近在整理Java集合的原始碼, 所以今天再來談談這個古老的話題,因為後面講HashMap會用到這個知識點, 所以重新梳理下。
如果不被重寫(原生Object)的hashCode和equals是什麼樣的?
- 不被重寫(原生)的hashCode值是根據記憶體地址換算出來的一個值。
- 不被重寫(原生)的equals方法是嚴格判斷一個物件是否相等的方法(object1 == object2)。
為什麼需要重寫equals和hashCode方法?
在我們的業務系統中判斷物件時有時候需要的不是一種嚴格意義上的相等,而是一種業務上的物件相等。在這種情況下,原生的equals方法就不能滿足我們的需求了
所以這個時候我們需要重寫equals方法,來滿足我們的業務系統上的需求。那麼為什麼在重寫equals方法的時候需要重寫hashCode方法呢?
我們先來看一下Object.hashCode的通用約定(摘自《Effective Java》第45頁)
- 在一個應用程式執行期間,如果一個物件的equals方法做比較所用到的資訊沒有被修改的話,那麼,對該物件呼叫hashCode方法多次,它必須始終如一地返回 同一個整數。在同一個應用程式的多次執行過程中,這個整數可以不同,即這個應用程式這次執行返回的整數與下一次執行返回的整數可以不一致。
- 如果兩個物件根據equals(Object)方法是相等的,那麼呼叫這兩個物件中任一個物件的hashCode方法必須產生同樣的整數結果。
- 如果兩個物件根據equals(Object)方法是不相等的,那麼呼叫這兩個物件中任一個物件的hashCode方法,不要求必須產生不同的整數結果。然而,程式設計師應該意識到這樣的事實,對於不相等的物件產生截然不同的整數結果,有可能提高散列表(hash table)的效能。
如果只重寫了equals方法而沒有重寫hashCode方法的話,則會違反約定的第二條:相等的物件必須具有相等的雜湊碼(hashCode)。
同時對於HashSet和HashMap這些基於雜湊值(hash)實現的類。HashMap的底層處理機制是以陣列的方法儲存放入的資料的(Node<K,V>[] table),其中的關鍵是陣列下標的處理。陣列的下標是根據傳入的元素hashCode方法的返回值再和特定的值異或決定的。如果該陣列位置上已經有放入的值了,且傳入的鍵值相等則不處理,若不相等則覆蓋原來的值,如果陣列位置沒有條目,則插入,並加入到相應的連結串列中。檢查鍵是否存在也是根據hashCode值來確定的。所以如果不重寫hashCode的話,可能導致HashSet、HashMap不能正常的運作、
如果我們將某個自定義物件存到HashMap或者HashSet及其類似實現類中的時候,如果該物件的屬性參與了hashCode的計算,那麼就不能修改該物件引數hashCode計算的屬性了。有可能會移除不了元素,導致記憶體洩漏。
接著來看一個程式碼片段:

執行這段程式碼發現結果返回的是null。
再來看一下HashMap中的get原始碼:
get的時候會先比較hashCode然後再去比較equals,返回結果為null其實都是hashCode惹的禍。

以Java.lang.Object來理解, JVM每次new一個Object, 都會將Object丟到一個雜湊表中去,這樣的話,下次做Object的比較或者取這個物件的時候, 它會根據物件的hashcode再從Hash表中取這個物件。這樣做的目的是提高取物件的效率。
1.new Object(),JVM根據這個物件的Hashcode值,放入到對應的Hash表對應的Key上,如果不同的物件確產生了相同的hash值,也就是發生了Hash key相同導致衝突的情況,那麼就在這個Hash key的地方產生一個連結串列,將所有產生相同hashcode的物件放到這個單鏈表上去,串在一起。
2.比較兩個物件的時候,首先根據他們的hashcode去hash表中找他的物件,當兩個物件的hashcode相同,那麼就是說他們這兩個物件放在Hash表中的同一個key上,那麼他們一定在這個key上的連結串列上。那麼此時就只能根據Object的equal方法來比較這個物件是否equal。當兩個物件的hashcode不同的話,肯定他們不能equals.