
linux的awk命令解讀
Qiniu 七牛問題解答

![]()
對於大量的日誌讀取,學會awk是個很好的快速統計的基礎。下面我帶大家來拜讀awk的真面目。本篇文章用的part01原始檔,都是預設用空格作為分隔符的。
awk是行處理器: 相比較螢幕處理的優點,在處理龐大檔案時不會出現記憶體溢位或是處理緩慢的問題,通常用來格式化文字資訊,awk處理過程: 依次對每一行進行處理,處理完成後統計然後輸出。
舉例:這個是最簡單的一個例子。下面我們來認真學習起來。
hdfs dfs -cat /flume/2015-03-25/REQ_IO/15-30/*|awk -F '\t' '$7==401{print $5}' | sort | uniq -c | sort 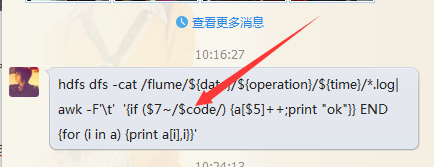
此處不該這樣去寫,應該直接寫具體的字串,否則程式識別不出變數中的值。
命令格式:
awk命令形式:
awk [-F|-f|-v] ‘BEGIN{} //{command1; command2} END{}’ file
[-F|-f|-v] 大引數,-F指定分隔符,-f呼叫指令碼,-v定義變數 var=value
’ ’ 引用程式碼塊
BEGIN 初始化程式碼塊,在對每一行進行處理之前,初始化程式碼,主要是引用全域性變數,設定FS分隔符
// 匹配程式碼塊,可以是字串或正則表示式
{} 命令程式碼塊,包含一條或多條命令
; 多條命令使用分號分隔
END 結尾程式碼塊,在對每一行進行處理之後再執行的程式碼塊,主要是進行最終計算或輸出結尾摘要資訊
特殊要點:
NF 欄位數量變數
NR 每行的記錄號,多檔案記錄遞增
FNR 與NR類似,不過多檔案記錄不遞增,每個檔案都從1開始
\t 製表符
\n 換行符
FS BEGIN時定義分隔符
RS 輸入的記錄分隔符, 預設為換行符(即文字是按一行一行輸入)
~ 匹配,與==相比不是精確比較
!~ 不匹配,不精確比較
== 等於,必須全部相等,精確比較
!= 不等於,精確比較
&& 邏輯與
|| 邏輯或
+ 匹配時表示1個或1個以上
/[0-9][0-9]+/ 兩個或兩個以上數字
/[0-9][0-9]*/ 一個或一個以上數字
FILENAME 檔名
OFS 輸出欄位分隔符, 預設也是空格,可以改為製表符等
ORS 輸出的記錄分隔符,預設為換行符,即處理結果也是一行一行輸出到螢幕
-F’[:#/]’ 定義三個分隔符
下面我們來看怎麼使用吧,手把手教你用起來:
1,列印日誌part01中的內容。
liuhanlindemac:Downloads yishiyaonie$ awk '{print}' part012,列印相同行數多的a行。
liuhanlindemac:Downloads yishiyaonie$ awk '{print "a"}' part01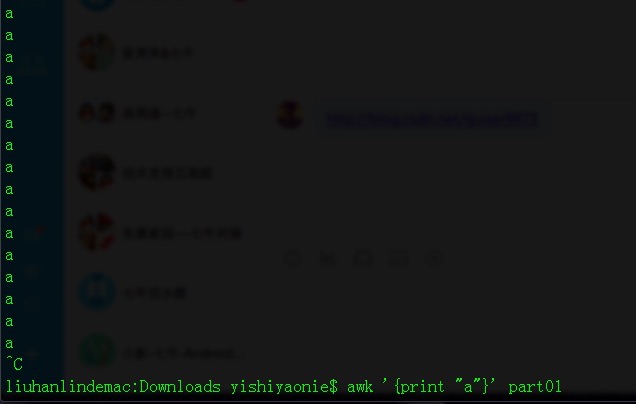
3,-F定義分隔符。預設是用空格來作為分隔符的。
liuhanlindemac:Downloads yishiyaonie$ awk -F'【】' '{print $1}' part01【】處可以是任意的字元。作為段停的一個標記。很好用歐。
4,將欄位分行列印。
liuhanlindemac:Downloads yishiyaonie$ awk '{print $1;print $6}' part01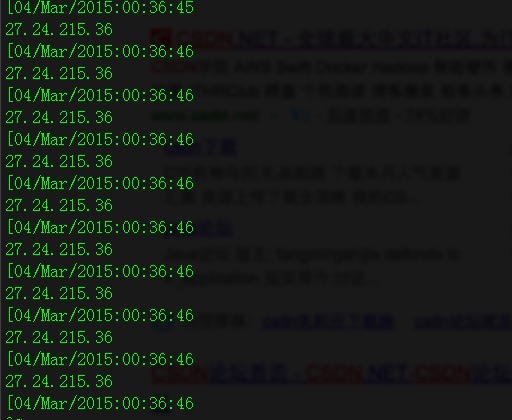
5,輸出資料格式化
liuhanlindemac:Downloads yishiyaonie$ awk '{print $1,$3,$4}' OFS='\t' part01
6,awk呼叫指令碼對檔案執行操作。
指令碼script程式碼:
BEGIN{
FS=":"
}
{print $1}liuhanlindemac:Downloads yishiyaonie$ awk -f script part017,awk自定義輸出:
liuhanlindemac:Downloads yishiyaonie$ awk -F' ' '{print "username:"$1 "\t\t uid: " $4}' part01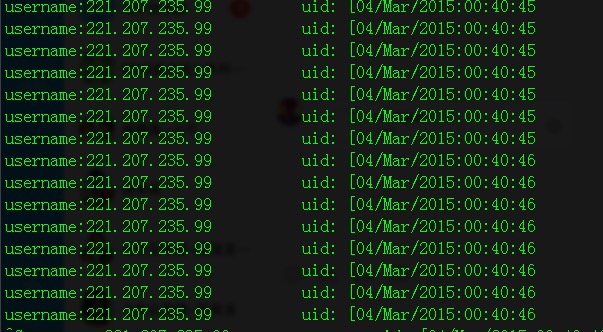
awk '{print $1 $3}' part01 //$1與$3相連輸出,不分隔
awk '{print $1,$3}' part01 //多了一個逗號,$1與$3使用空格分隔
awk '{print $1 " " $3}' part01 //$1與$3之間手動新增空格分隔8,awk對一條記錄欄位數量做判斷的輸出。
awk '{print $NF}' part01 //將每行第NF個欄位的值打印出來
awk 'NF==4 {print }' part01 //顯示只有4個欄位的行
awk 'NF>2{print $0}' part01 //顯示每行欄位數量大於2的行
9,awk對行的處理:
awk '{print NR,NF,$NF,"\t",$0}' part01 //依次列印行號,欄位數,最後欄位值,製表符,每行內容
awk 'NR==5{print}' part01 //顯示第5行
awk 'NR==5 || NR==6{print}' part01 //顯示第5行和第6行
awk 'NR!=1{print}' part01 //不顯示第一行10,匹配字元處理:
//純字元匹配 !//純字元不匹配 ~//欄位值匹配 !~//欄位值不匹配 ~/a1|a2/欄位值匹配a1或a2 awk '/183.198.46.6/' part01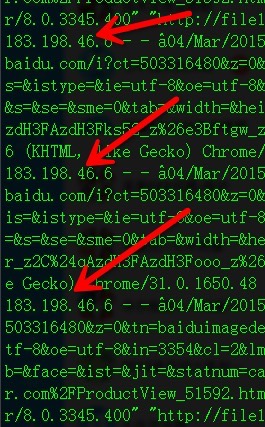
awk '/mail/,/mysql/{print}' /etc/passwd //區間匹配
awk '/[2][7][7]*/{print $0}' /etc/passwd //匹配包含27為數字開頭的行,如27,277,2777...
awk '$1~/mail/{print $1}' /etc/passwd //$1匹配指定內容才顯示
awk '{if($1~/mail/) print $1}' /etc/passwd //與上面相同
awk '$1!~/mail/{print $1}' /etc/passwd //不匹配11,IF語句,必須用在{}中,且比較內容用()擴起來
awk '{if($1~/mail/) print $1}' /etc/passwd //簡寫
awk '{if($1~/mail/) {print $1}}' /etc/passwd //全寫
awk '{if($1~/mail/) {print $1} else {print $2}}' /etc/passwd //if...else...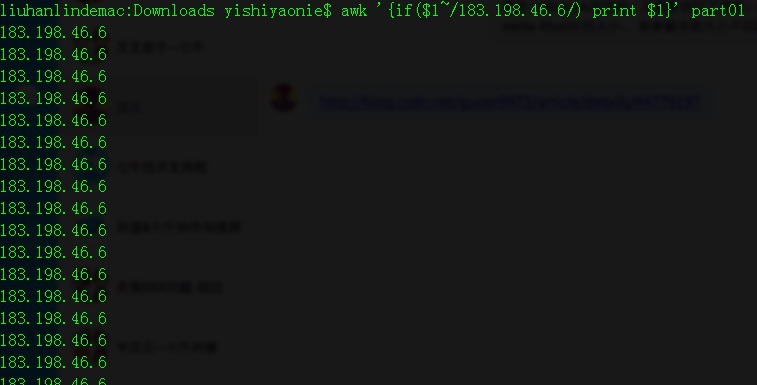
12, 條件表示式 == != > >=
awk '$1=="183.198.46.6"{print $4}' part01
awk '{if($1=="mysql") print $3}' /etc/passwd //與上面相同
awk '$1!="mysql"{print $3}' /etc/passwd //不等於
awk '$3>1000{print $3}' /etc/passwd //大於
awk '$3>=100{print $3}' /etc/passwd //大於等於
awk '$3<1{print $3}' /etc/passwd //小於
awk '$3<=1{print $3}' /etc/passwd //小於等於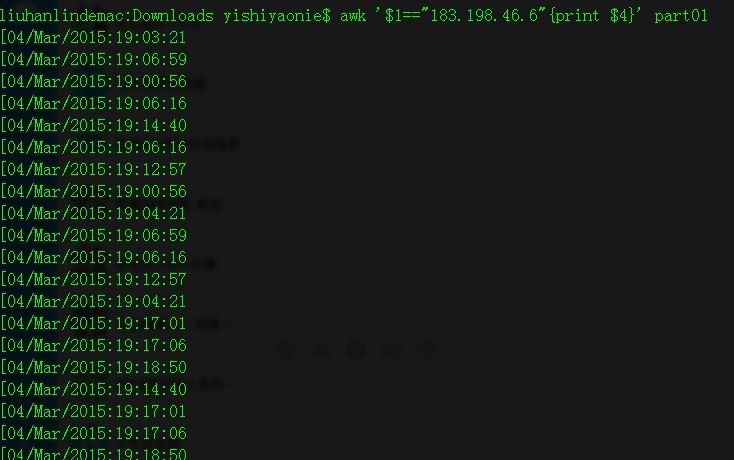
13,邏輯運算子 && ||
awk '$1~/183.198.46.6/ && $4~/2015:19:14:40/ {print$7}' part01
awk '$1~/mail/ && $3>8 {print }' part01 //邏輯與,$1匹配mail,並且$3>8
awk '{if($1~/mail/ && $3>8) print }' /etc/passwd
awk '$1~/mail/ || $3>1000 {print }' /etc/passwd //邏輯或
awk '{if($1~/mail/ || $3>1000) print }' /etc/passwd 
14,數值運算
awk '$3 > 100' /etc/passwd
awk '$3 > 100 || $3 < 5' /etc/passwd
awk '$3+$4 > 200' /etc/passwd
awk '/mysql|mail/{print $3+10}' /etc/passwd //第三個欄位加10列印
awk '/mysql/{print $3-$4}' /etc/passwd //減法
awk '/mysql/{print $3*$4}' /etc/passwd //求乘積
awk '/MemFree/{print $2/1024}' /proc/meminfo //除法
awk '/MemFree/{print int($2/1024)}' /proc/meminfo //取整15,輸出分隔符OFS
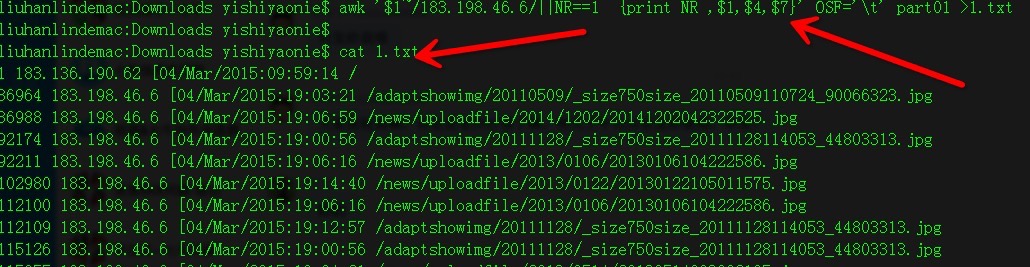
awk '$1~/183.198.46.6/||NR==1 {print NR ,$1,$4,$7}' OSF='\t' part01
//輸出欄位1匹配183.198.46.6的行,其中輸出每行行號,欄位1,4,7,並使用製表符分割欄位
主要是為了顯示好看。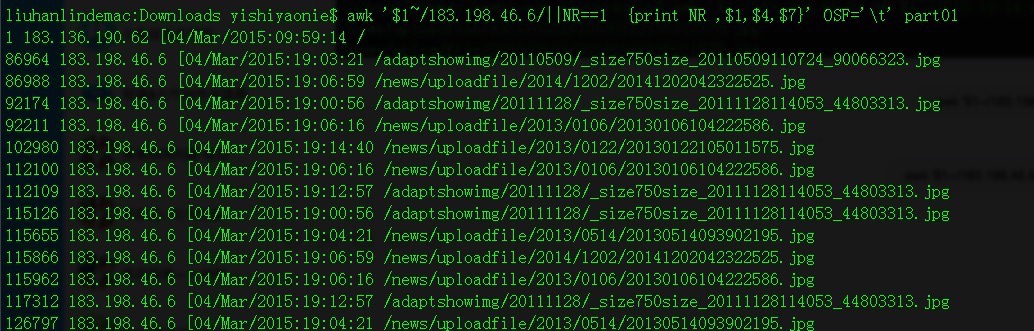
16, 輸出處理結果到檔案
使用重定向進行輸出 awk '$1~/183.198.46.6/||NR==1 {print NR ,$1,$4,$7}' OSF='\t' part01 >1.txt
在命令程式碼塊中直接輸出 awk 'NR!=1{print > "./fs"}'
17,格式化輸出
awk '{printf "%-8d %-8s %-10s\n",$1,$2,$3}' part01
printf表示格式輸出
%格式化輸出分隔符,-8長度為8個數字,s表示字串型別,列印每行前三個欄位,指定第一個欄位輸出字串型別(長度為8),第二個欄位輸出字串型別(長度為8),第三個欄位輸出字串型別(長度為10)
netstat -anp|awk '$6=="LISTEN" || NR==1 {printf "%-10s %-10s %-10s \n",$1,$2,$3}'
netstat -anp|awk '$6=="LISTEN" || NR==1 {printf "%-3s %-10s %-10s %-10s \n",NR,$1,$2,$3}'
18,IF語句
awk '{if ($1~/183.198.46.6/) {print "ok"} else {print "nop"}}' part01
awk 'BEGIN{a=0;b=0} {if($1~/183.198.46.6/) {a++;print "ok"} else {b++;print "nop"}} END {print a,b} OSF='\t\t'' part01 //ID大於100,A加1,否則B
awk '{if($3<100) next; else print}' /etc/passwd //小於100跳過,否則顯示
awk 'BEGIN{i=1} {if(i<NF) print NR,NF,i++ }' /etc/passwd
awk 'BEGIN{i=1} {if(i<NF) {print NR,NF} i++ }' /etc/passwd
另一種形式
awk '{print ($3>100 ? "yes":"no")}' /etc/passwd
awk '{print ($3>100 ? $3":\tyes":$3":\tno")}' /etc/passwd
19,while 語句
awk 'BEGIN{i=1} {while(i<NF) print NF,$i,i++}' part01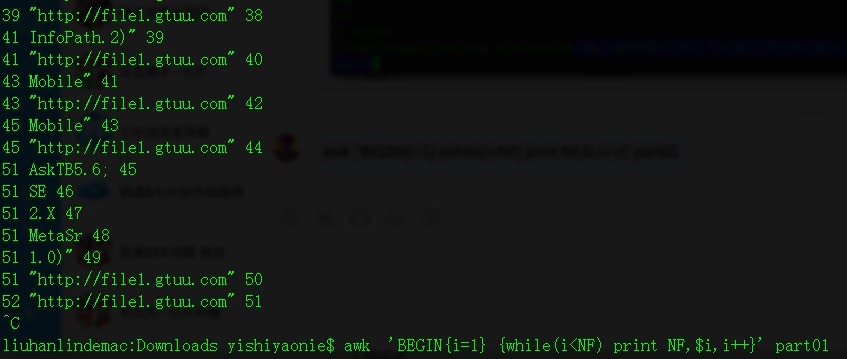
20,陣列
awk 'NR!=1 {a[$1]++} END {for (i in a) {print a[i],"\t",i}}' part01
awk 'NR!=1{a[$6]++} END{for (i in a) printf "%-20s %-10s %-5s \n", i,"\t",a[i]}'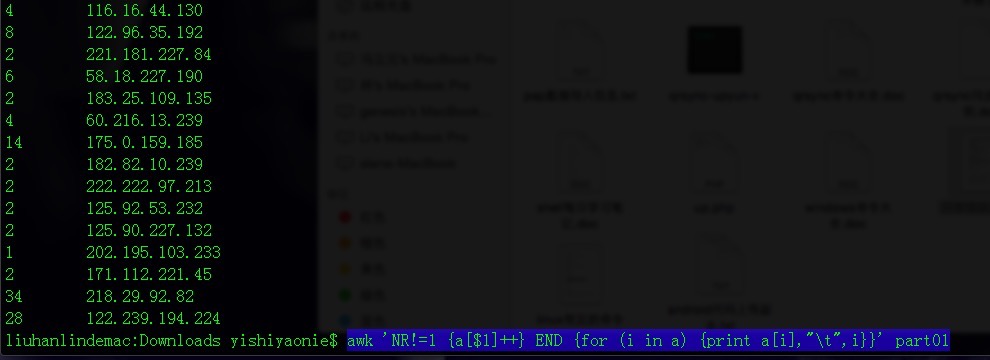
按照第一個欄位做彙總,第一個欄位的重複數量統計。
好了,到目前為止語法差不多了,我們需要更多的實踐來運用awk這個強大的文字統計工具。
應用1
awk -F: '{print NF}' helloworld.sh //輸出檔案每行有多少欄位
awk -F: '{print $1,$2,$3,$4,$5}' helloworld.sh //輸出前5個欄位
awk -F: '{print $1,$2,$3,$4,$5}' OFS='\t' helloworld.sh //輸出前5個欄位並使用製表符分隔輸出
awk -F: '{print NR,$1,$2,$3,$4,$5}' OFS='\t' helloworld.sh //製表符分隔輸出前5個欄位,並列印行號
應用2
awk -F'[:#]' '{print NF}' helloworld.sh //指定多個分隔符: #,輸出每行多少欄位
awk -F'[:#]' '{print $1,$2,$3,$4,$5,$6,$7}' OFS='\t' helloworld.sh //製表符分隔輸出多欄位
應用3
awk -F'[:#/]' '{print NF}' helloworld.sh //指定三個分隔符,並輸出每行欄位數
awk -F'[:#/]' '{print $1,$2,$3,$4,$5,$6,$7,$8,$9,$10,$11,$12}' helloworld.sh //製表符分隔輸出多欄位
應用4
計算/home目錄下,普通檔案的大小,使用KB作為單位
ls -l|awk 'BEGIN{sum=0} !/^d/{sum+=$5} END{print "total size is:",sum/1024,"KB"}'
ls -l|awk 'BEGIN{sum=0} !/^d/{sum+=$5} END{print "total size is:",int(sum/1024),"KB"}' //int是取整的意思
應用5
統計netstat -anp 狀態為LISTEN和CONNECT的連線數量分別是多少
netstat -anp|awk '$6~/LISTEN|CONNECTED/{sum[$6]++} END{for (i in sum) printf "%-10s %-6s %-3s \n", i," ",sum[i]}'
應用6
統計/home目錄下不同使用者的普通檔案的總數是多少?
ls -l|awk 'NR!=1 && !/^d/{sum[$3]++} END{for (i in sum) printf "%-6s %-5s %-3s \n",i," ",sum[i]}'
mysql 199
root 374
統計/home目錄下不同使用者的普通檔案的大小總size是多少?
ls -l|awk 'NR!=1 && !/^d/{sum[$3]+=$5} END{for (i in sum) printf "%-6s %-5s %-3s %-2s \n",i," ",sum[i]/1024/1024,"MB"}'
應用7
輸出成績表
awk 'BEGIN{math=0;eng=0;com=0;printf "Lineno. Name No. Math English Computer Total\n";printf "------------------------------------------------------------\n"}{math+=$3; eng+=$4; com+=$5;printf "%-8s %-7s %-7s %-7s %-9s %-10s %-7s \n",NR,$1,$2,$3,$4,$5,$3+$4+$5} END{printf "------------------------------------------------------------\n";printf "%-24s %-7s %-9s %-20s \n","Total:",math,eng,com;printf "%-24s %-7s %-9s %-20s \n","Avg:",math/NR,eng/NR,com/NR}' test0
日誌查詢系統
#! /bin/bash
echo "example:" "--------./log.sh 404 2015-04-01 REQ_IO 15-00---------------------------------------------------------------------------------"
code=$1
echo "the code is ${code} "
date=$2
echo "the date is ${date}"
operation=$3
echo "the operation is ${operation}"
time=$4
echo "the time is ${time}"
if [ "$operation" = "REQ_IO" -a "$code" = "401" ];
then
echo "searching code 401............waiting for a while"
hdfs dfs -cat /flume/${date}/${operation}/${time}/*.log|awk '{if ($7~/401/) {a[$5" UID:" substr($0, index($0, "uid") + 5, 10)]++}} END {for (i in a) {print a[i],i}}'| sort -rn | head
fi
if [ "$operation" = "REQ_IO" -a "$code" = "404" ];
then
echo "searching code 404............waiting for a while"
hdfs dfs -cat /flume/${date}/${operation}/${time}/*.log|awk '{if ($7~/404/) {a[$5]++}} END {for (i in a) {print a[i],i}}'| sort -rn | head
fi
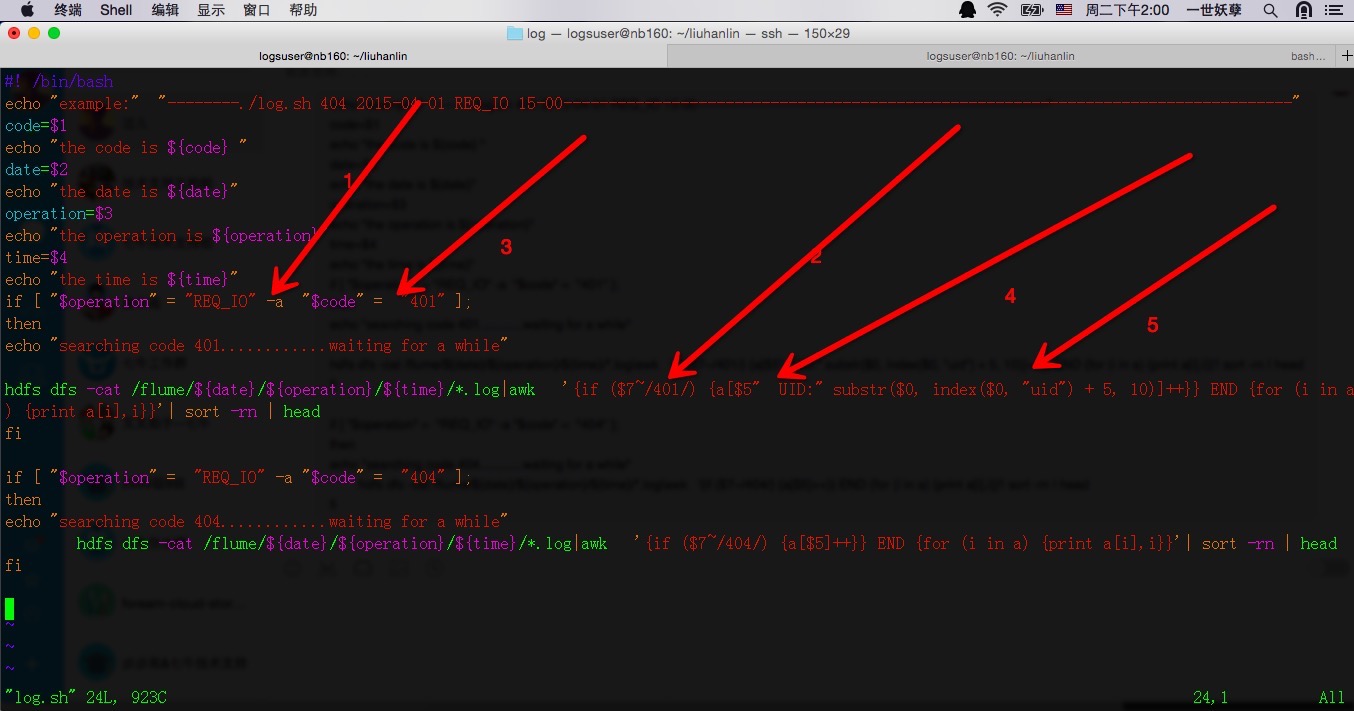
部分地方的空格一定要注意,主要是一些書寫格式規範和用法的注意點我這裡都標註出來了。還有就是第四和第五的用法,將一條記錄中的若干內容拼接到一起來作為一個數據項。這個是不是很厲害呢。
關於substr以及index的用法請參考:linux awk 內建函式詳細介紹(例項)
http://www.cnblogs.com/chengmo/archive/2010/10/08/1845913.html