
平行計算中的BSP模型
計算模型
所謂計算模型實際上就是硬體和軟體之間的一種橋樑,我們可以藉助它來設計分析演算法,在其上髙級語言能被有效地編譯且能夠用硬體來實現。在序列計算時,馮•諾依曼機就是一個理想的序列計算模型,在此模型上硬體設計者可設計多種多樣的馮•諾依曼機而無須考慮那些將要被執行的軟體;另一方面,軟體工程師也能夠編寫各種可在此模型上有效執行的程式而無須考慮所使用的硬體。
不幸的是,在平行計算時,尚未有一個類似於馮•諾依曼機的真正通用的平行計算模型。現在流行的計算模型要麼過於簡單、抽象(如PRAM);要麼過於專用(如互連網路模型和VLSI計算模型)。因而急需發展一種更為實用、能夠較真實反映現代並行機效能的平行計算模型。我們在之前的文章中已經討論過PRAM模型。讀者可以參考我的部落格文章
簡而言之,PRAM模型,即並行隨機存取機器,也稱之為共享儲存的SIMD模型,是一種抽象的平行計算模型。在這種模型中,假定存在著一個容量無限大的共享儲存器;同時存在有限(或無限)個功能相同的處理器,且其均具有簡單的算術運算和邏輯判斷功能;在任何時刻各處理器均可通過共享儲存單元相互交換資料。根據處理器對共享儲存單元是否可以同時讀、同時寫的限制, PRAM模型又可分為:EREW、CREW、CRCW等幾種型別。
下面本文將介紹另外一種平行計算模型——BSP模型。
BSP模型
BSP(Bulk Synchronous Parallel)模型,字面的含義是 “大”同步模型,它最早由Leslie和Valiant 在 1990 年提出。作為計算機語言和體系結構之間的橋樑,
- 處理器/儲器模組: A BSP abstract machine consists of a collection of p abstract processors, each with local memory, connected by an interconnection network.
- 執行以時間間隔L為週期的所謂路障同步器:the time to do a barrier synchronization.
- 施行處理器/儲器模組對之間點到點傳遞訊息的選路器: the rate at which continuous randomly addressed data can be delivered
所以BSP模型將並行機的特性抽象為三個定量引數p、g、L,分別對應於處理器數、選路器吞吐率(亦稱頻寬因子)、全域性同步之間的時間間隔。
BSP模型中的計算行為:在BSP模型中,計算過程是由一系列用全域性同步分開的週期為L的超級步(supersteps)所組成的。A (abstract) program consists of
每個superstep都包含:
- a computation where each processor (executing the threads assigned to it) uses only locally held values;
- a global message transmission from each processor to any subset of the others;
- a barrier synchronization.
在superstep結束時,the transmitted messages become available as
local data for the next superstep。下圖是BSP裡一個superstep中的計算模式示意圖:
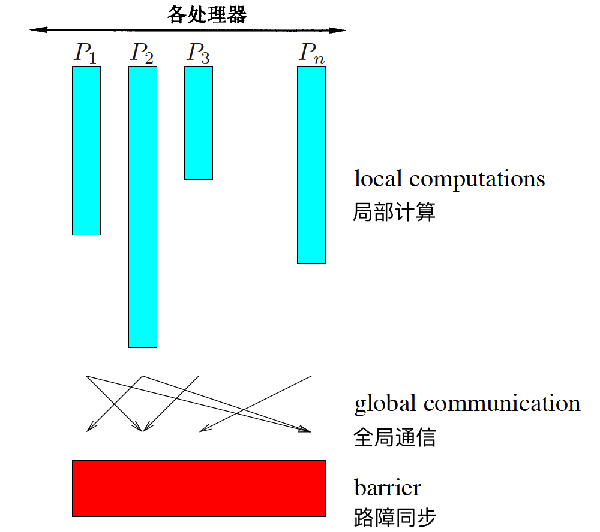
BSP模型的性質和特點:BSP模型是個分佈儲存的MIMD計算模型,其特點是:
- 它將處理器和選路器分開,強調了計算任務和通訊任務的分開,而選路器僅施行點到點的訊息傳遞,不提供組合、複製或廣播等功能,這樣做既掩蓋了具體的互連網路拓撲,又簡化了通訊協議; With the program divided into supersteps it is easier to provide performance guarantees than with unregulated message-passing systems. Because communication all happens together at the end of the computation phase of the superstep, it is possible to perform automatic optimisation of the communications pattern. This is particularly important on machines where the start-up cost of a communication is high: if during a superstep processor i sends two messages to processor j , then it will often be quicker to bundle the messages together and send the bundle from
i to j than it would be to send each message separately. Similarly, the communication pattern can be reshuffled to avoid network congestion, and intelligent routing techniques can be used to detect and avoid hot spots。 - 釆用路障方式的以硬體實現的全域性步是在可控的粗粒度級,從而提供了執行緊耦合同步式並行演算法的有效方式,而程式設計開發人員並無過分的負擔,BSP model eliminates the need for programmers to manage memory, assign communication and perform low-level synchronization. Threads of the program are assigned (typically in a randomized way) by the machine to the processors.;
- 在分析BSP模型的效能時,假定區域性操作可在一個時間步內完成,而在每一個superstep中,一個處理器至多傳送或接收 h 條訊息(稱為h-relation)。 假定
s 是傳輸建立時間,所以傳送 h 條訊息的時間為 gh+s,如果gh≥2s ,則 L 至 少應≥gh 。很清楚,硬體可將L設定儘量小(例如使用流水線或寬的通訊頻寬使 g儘量小),而軟體可以設定L之上限(因為L愈大,並行粒度愈大)。在實際使用中,g可定義為每秒處理器所能完成的區域性計算數目與每秒選路器所能傳輸的資料量之比。如果能合適地平衡計算和通訊,則BSP模型在可程式設計性方面具有主要的優點,它可直接在BSP模型上執行演算法(不是自動地編譯它們),此優點將隨著g 的增加而更加明顯; - 為PRAM模型所設計的演算法,均可釆用在每個BSP處理器上模擬一些PRAM處理器的方法實現之。This leads to optimal efficiency (i.e., within a constant factor performance of the PRAM model) provided the programmer writes programs with sufficient parallel slackness。理論分析證明,這種模擬在常數因子範圍內是最佳的,只要並行寬鬆度(Parallel Slackness),即每個BSP處理器所能模擬的PRAM處理器的數目足夠大(When programs written for p threads are run on n processors and p >> n (e.g. p = n log n) then there is some parallel slackness)。在併發情況下,多個處理器同時訪問分散式的儲存器會引起一些問題,但使用雜湊方法可使程式均勻地訪問分散式儲存器。在 PRAM-EREW情況下,如果所選用的雜湊函式足夠有效,則
L 至少是對數的,於是模擬可達最佳,這是因為我們欲在擁有p 個物理處理器的BSP模型上,模擬v≥plogp 個虛擬處理器,可將v/p≥logp 個虛擬處理器分配給每個物理處理器。在 一個supersetp內,v 次存取請求可均勻攤開,每個處理器大約v/p 次,因此機器執行本次超級步的最佳時間為O(v/p) ,且概率是高的。同祥,在v 個處理器的 PRAM-CRCW模型中,能夠在p 個處理器(如果v=p1+ϵ,ϵ>0 )和L≥logp 的BSP模型上用O(v/p) 的時間也可達到最佳模擬。
BSP成本分析(Computational analysis):Consider a BSP program consisting of S supersteps. Then, the execution time for superstep i is
其中,
Call
參考文獻
【1】陳國良,平行計算——結構 • 演算法 • 程式設計,高等教育出版社,2003
【2】陳國良,並行演算法的設計與分析(第3版),高等教育出版社,2009