
hadoop叢集的搭建和啟動
Hadoop的叢集搭建
一:JDK裝好
二:配置了免密登陸和主機名對映
三:同步時間和關閉防火牆
四:然後開始搭建hadoop叢集
NAT 方式聯網
配置 h ssh 免密登陸
#生成 ssh 免登陸金鑰
ssh-keygen -t rsa (四個回車)
執行完這個命令後,會生成 id_rsa(私鑰)、id_rsa.pub(公鑰)
將公鑰拷貝到要免密登陸的目標機器上
ssh-copy-id node-02
配置 IP 、主機名 對映
vi /etc/hosts
192.168.33.101 node-1
192.168.33.102 node-2
192.168.33.103 node-3
#關閉防火牆
service iptables stop
#檢視防火牆開機啟動狀態
chkconfig iptables --list
#關閉防火牆開機啟動
chkconfig iptables off
#網路同步時間
ntpdate cn.pool.ntp.org
設定主機名
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=node-1

這個是我們編譯過的hadoop, 如果沒有編譯過的需要先編譯hadoop(耗時50分鐘)
然後開始我們的正式搭建hadoop的叢集
1 上傳我們的安裝包,在主機上上傳 cd /export/server
上傳完畢後解壓我們的安裝包 tar -zxvf 包名
2 hadoop的目錄結構如下

bin:Hadoop 最基本的管理指令碼和使用指令碼的目錄,
etc:Hadoop 配置檔案所在的目錄,包括core-site,xml、hdfs-site.xml、
mapred-site.xml 等從 Hadoop1.0 繼承而來的配置檔案和yarn-site.xml 等
Hadoop2.0 新增的配置檔案。
lib:該目錄包含了 Hadoop 對外提供的程式設計動態庫和靜態庫,與 include 目
錄中的標頭檔案結合使用。
libexec:各個服務對用的 shell 配置檔案所在的目錄,可用於配置日誌輸
出、啟動引數(比如 JVM 引數)等基本資訊。
sbin:Hadoop 管理指令碼所在的目錄,主要包含 HDFS 和 YARN 中各類服務的
啟動/關閉指令碼。
share:Hadoop 各個模組編譯後的 jar 包所在的目錄
3 配置檔案的修改 ,,只需要在直接點上修改之後 然後分發給其他機器
第一個:hadoop-env.sh
cd /export/server/hadoop-2.7.4/etc/hadoop
vi hadoop-env.sh
export JAVA_HOME=/export/server/jdk1.8.0_65

這裡在配置一下java的原因是不管系統配置了沒保證這裡能載入到.
第二個:core-site.xml
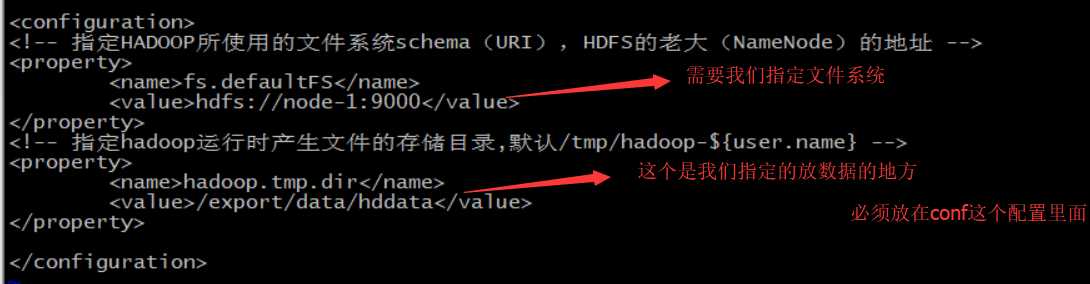
<value>hdfs://node-1:9000</value> 如果是別的檔案系統的話 需要配置對應的schema.
tfs://
file://
gfs://
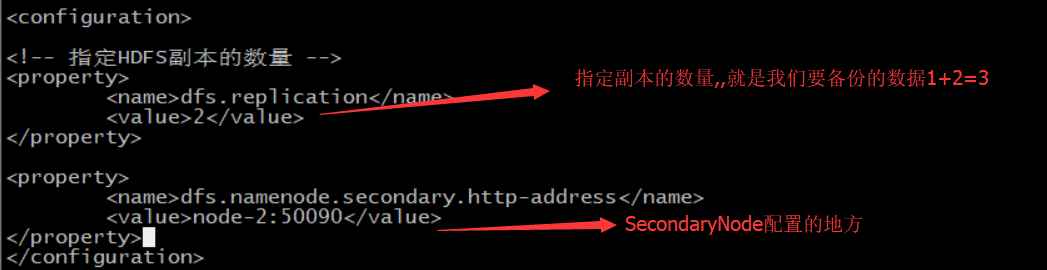
第三個:hdfs-site.xml
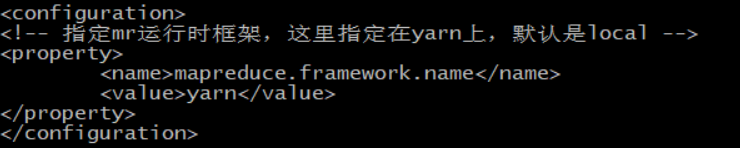
第四個: mapred-site.xml
mv mapred-site.xml.templatemapred-site.xml 修改一下配置檔案的名字
vi mapred-site.xml
這個配置的就是MapReduce執行時交給yarn去計算
第五個:yarn-site.xml

叢集規劃:
結合軟體中各個元件的特性(比如有的佔記憶體,有的需要大量磁碟)以及叢集的硬體設施
合理的把叢集各個元件規劃(把自己的思想體現在機器角色部署上)到合理的機器上,是各個元件不會產生硬體的搶奪..
規劃跟最終的實際匹配,需要配置檔案來約束你的規劃
NameNode 和SecondaryNameNode 需要大量的記憶體
DataNode需要大量的磁碟.所以應該放.
node-01 NameNode DataNode ResourceManager NodeManager
node-02 DataNode NodeManagerSecondaryNameNode
node-03 DataNode NodeManager
叢集的擴容只需要新增DataNode NodeManager(主要放資料和資料管理)
node-04 DataNode NodeManager
node-05 DataNode NodeManager
第六個:slaves檔案,裡面寫上從節點所在的主機名字
vi slaves
node-1
node-2
node-3
將hadoop新增到環境變數
vim /etc/profile
新增以下的命令注意hadoop的位置
exportHADOOP_HOME=/export/server/hadoop-2.7.4
exportPATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

source /etc/profile
然後把我們的安裝包和配置檔案拷貝給其他的機器
scp -r /export/server/hadoop-2.7.4/[email protected]:/export/server/
scp -r /export/server/hadoop-2.7.4/[email protected]:/export/server/
scp -r /etc/profile [email protected]:/etc/
scp -r /etc/profile [email protected]:/etc/
然後是配置生效 source /etc/profile
配置已經全部完成..
格式化namenode(本質是對namenode進行初始化)
namenode格式化 (ps:因為namenode在node-1上,所以在這裡格式化)
1、新叢集初次啟動需要格式化
2、格式化只能進行一次 後續不再格式化
3、格式化也就是初始化操作
因為沒有格式化之前 hdfs在物理上還不存在 初始化一些hdfs執行所需要的初始目錄 檔案等
不同於傳統意義上的格式化(可不是格式化硬碟 U盤的那個格式化)
4、格式化在hdfs主角色namenode 所在的機器上進行
在/export/server/hadoop-2.7.4/etc/hadoop的目錄下 格式化
格式化的命令如下:
hdfs namenode –format
hadoop叢集啟動
第一種:指令碼一鍵啟動(ssh免密了嗎? slaves檔案配置了嗎)
hdfs:start-dfs.sh stop-dfs.sh
yarn:start-yarn.sh stop-yarn.sh
start-all.sh stop-all.sh
第二種:
hdfs hadoop-daemon.sh
yarn yarn-daemon.sh
一鍵啟動hdfs .

此時已經啟動了我們hdfs的叢集
然後是我們的yarn叢集

然後檢視我們的hdfs叢集和yarn叢集
我們的hdfs叢集和yarn叢集配置成功
驗證是否啟動成功
Hdfs的測試 在瀏覽器輸入 node-1:50070 (需要在win上配置hosts,50070是預設埠)

Yarn的測試 在瀏覽器輸入 node-1:8088
相關推薦
hadoop叢集的搭建和啟動
Hadoop的叢集搭建一:JDK裝好二:配置了免密登陸和主機名對映三:同步時間和關閉防火牆四:然後開始搭建hadoop叢集NAT 方式聯網配置 h ssh 免密登陸#生成 ssh 免登陸金鑰ssh-keygen -t rsa (四個回車)執行完這個命令後,會生成 id_rs
本地搭建hadoop叢集--hbase和zookeeper的安裝
zookeeper的安裝 1、解壓tar包 2、修改配置檔案 cd conf cp -a zoo_sample.cfg zoo.cfg vim zoo.cfg 配置 dataDir=/opt/module/zookeeper-3.4.12/data 以
hadoop叢集搭建3之叢集啟動
前面叢集已經成功搭建,現在來嘗試啟動叢集。第一次系統啟動的時候,是需要初始化的 啟動zookeeper 1.啟動zookeeper的命令:./zkServer.sh start|stop|status [[email protected] ~]$3 zkServer.s
Centos7 實現Hadoop-2.9.1分散式叢集搭建和部署(三臺機器)
一、準備三臺虛擬機器hadoop 192.168.131.128 localhost131 192.168.131.131 localhost134 192.168.131.134(以上是我的三臺虛擬機器的hostname 和 ip)hadoop 是 master 的 hos
Hadoop叢集搭建(HDFS和Yarn叢集)
hadoop叢集搭建(HDFS和Yarn叢集) 1.安裝hadoop2.7.4 上傳hadoop的安裝包到伺服器 hadoop-2.7.4-with-centos-6.7.tar.gz 解壓安裝包 tar zxvf hadoop-2.7.4-wit
hadoop學習第二天~Hadoop2.6.5完全分散式叢集搭建和測試
環境配置: 系統 centos7 節點 192.168.1.111 namenode 192.168.1.115 datanode2 192.168.1.116 datanode3 java 環境 :
hadoop叢集搭建之偽分散式和完全分散式
## Hadoop叢集搭建 一、軟體及環境準備 安裝JDK 查詢是否安裝jdk: rpm -qa |grep java 如果安裝版本小於1.7,解除安裝該版本 rpm -e 軟體包 將上傳好的jdk解壓並配置環境變數
maven+eclipse+ssm 環境搭建和啟動
sting pda sta and project ins setting pro load 該類工程環境搭建和啟動方法 --------------------------------------------------------------------------
Hadoop----叢集搭建指南(下卷)
前言 什麼是Hadoop? Apache Hadoop is a framework for running applications on large cluster built of commodity hardware. The Hadoop framewor
Hadoop----叢集搭建指南(中卷)
前言 本文的搭建基於上卷的配置,環境不再一一贅述。網路配置好的5臺節點均可相互ping通,對於節點hadoop1(192.168.20.2)可以ping同其餘四臺hadoop2(192.168.20.3)、hadoop3(192.168.20.4)、hadoop4(192.16
Hadoop----叢集搭建指南(上卷)
前言 閱讀本文,需要具備Linux、計算機網路的基礎知識。所以在文中出現的相關基礎知識,均以連結的形式給出,務必理解該連結的內容後,繼續閱讀本指南。 叢集搭建的環境多種多樣,本文采用VitualBox安裝5臺虛擬機器構建叢集。具體環境: CentOS 6.5 6
CentOS7下靜態ip地址分配(Hadoop叢集搭建)
作業系統是CentOS 在搭建Hadoop過程中,發現每一次啟動虛擬機器,ip地址就會變化。 這是由於一開始安裝CentOS的時候,有一個自動連線乙太網,他會自動給你分配ip地址,但是我們往往需要的是另一個。 首先看我的主機對映, 可以看到131,132,133 對應是,主機,
ReactNative 環境的搭建和啟動(安卓版)
總體步驟一覽: 一、下載 JDK 8.0:新增 %JAVA_HOME% 變數,新增 PATH; 二、下載 Android SDK:修復 SDK Manager.exe 閃退的問題,用 SDK Manager.exe 安裝 Android SDK platform-t
hadoop叢集搭建(docker)
背景 目前在一家快遞公司工作,因專案需要,對大資料平臺做個深入的瞭解。工欲利其器必先利其器,在網上找了許多教程,然後自己搭建一個本地的環境並記錄下來,增加一些印象。 環境搭建 1)Ubuntu docker pull ubuntu:16.04 docker images&nb
Hadoop叢集搭建以及遇到問題詳解
轉載:http://dblab.xmu.edu.cn/blog/install-hadoop-cluster/ centos7單機、分散式、偽分佈:https://blog.csdn.net/qq_40938267/article/details/83416665 有詳細的搭建過程
分散式系統詳解--框架(Hadoop-叢集搭建)
分散式系統詳解--框架(Hadoop-叢集搭建) 前面的文章也簡單介紹了,hadoop的環境搭建分為三種,單機版,偽分
ssh無密登入配置詳解(hadoop叢集搭建)
ssh無密登入原理 注:私鑰和公鑰是每個使用者獨有的,而不是機器或者伺服器的,比如一臺電腦或者伺服器或者虛擬機器,可以同時存在多個使用者,但不同使用者需要遠端登入其他伺服器或者虛擬機器時,都必須配置各自的私鑰和公鑰,而且使用者之間的各不相同 常用命令 ssh ip(遠端登入也可
Hadoop叢集搭建一:Single node cluster
Hadoop叢集搭建一:Single node cluster 本文主要介紹在單個ubantu機器上搭建hadoop叢集。 1.ubuntu虛擬機器安裝 採用Vmware workstation10工具來安裝ubuntu系統,ubuntu使用的是64位的18.04-desktop版本
【大資料技術】1.hadoop叢集搭建
近年來,大資料技術越來越吃香,也是追求高薪的必備技能之一。 近些日子,打算技術轉型,開始研究大資料技術,基於對JAVA、LINUX系統有一定的基礎,完成hadoop叢集搭建(1個master和1個slave)。 一、準備工具 VMvare、centOS6.3、SSH Secure客戶端(
Zookeeper叢集搭建和Kafka叢集的搭建
Zookeeper!!! 一、Zookeeper叢集搭建步驟 0)叢集規劃 在hadoop01、hadoop02和hadoop03三個節點上部署Zookeeper。 1)解壓安裝 (1)解壓zookeeper安裝包到/home/hadoop/insatll/目錄下 [[email