
Hadoop與MongoDB整合(Hive篇)
1.背景
公司希望使用MongoDB作為後端業務資料庫,使用Hadoop平臺作為資料平臺。最開始是先把資料從MongoDB匯出來,然後傳到HDFS,然後用Hive/MR處理。我感覺這也太麻煩了,現在不可能沒有人想到這個問題,於是就搜了一下,結果真找到一個MongoDB Connector for Hadoop
2.MongoDB簡介–摘自鄒貴金的《mongodb》一書
NoSQL資料庫與傳統的關係型資料庫相比,它具有操作簡單、完全免費、原始碼公開、隨時下載等特點,並可以用於各種商業目的。這使NoSQL產品廣泛應用於各種大型入口網站和專業網站,大大降低了運營成本。
2010年,隨著網際網路Web2.0網站的興起,NoSQL在國內掀起一陣熱潮,其中風頭最勁的莫過於MongoDB了。越來越多的業界公司已經將MongoDB投入實際的生產環境,很多創業團隊也將MongoDB作為自己的首選資料庫,創造出非常之多的移動網際網路應用。
MongoDB的文件模型自由靈活,可以讓你在開發過程中暢順無比。對於大資料量、高併發、弱事務的網際網路應用,MongoDB可以應對自如。MongoDB內建的水平擴充套件機制提供了從百萬到十億級別的資料量處理能力,完全可以滿足Web2.0和移動網際網路的資料儲存需求,其開箱即用的特性也大大降低了中小型網站的運維成本。
3.Hadoop HA叢集搭建與Hive安裝
4.正式開始
Installation
Obtain the MongoDB Hadoop Connector. You can either build it or download the jars. For Hive, you'll need the "core" jar and the "hive" jar. Get a JAR for the MongoDB Java Driver. The connector requires at least version 3.0.0 of the driver "uber" jar (called "mongo-java-driver.jar"). In your Hive script, use ADD JAR commands to include these JARs (core, hive, and the Java driver), e.g., ADD JAR /path-to/mongo-hadoop-hive-<version>.jar;.
Requirements
Supported Hadoop and Hive versions
As of August 2013, only Hive versions <= 0.10 are stable. Mongo-Hadoop currently supports Hive versions >= 0.9. Some classes and functions are deprecated in Hive 0.11, but they’re still functional.
Hadoop versions greater than 0.20.x are supported. CDH4 is supported, but CDH3 with its native Hive 0.7 is not. However, CDH3 is compatible with newer versions of Hive. Installing a non-native version with CDH3 can be used with Mongo-Hadoop.
1.版本一定要按它要求的來,jar包去
mongo-hadoop-core-1.5.1.jar
mongo-hadoop-hive-1.5.1.jar
mongo-java-driver-3.2.1.jar
2.將jar包拷到
[[email protected] ~]$ hive
Logging initialized using configuration in jar:file:/home/hadoop/opt/apache-hive-1.2.1-bin/lib/hive-common-1.2.1.jar!/hive-log4j.properties
hive> add jar /home/hadoop/opt/hive/lib/mongo-hadoop-core-1.5.1.jar;#三個都加,我這就不寫了。3.Hive Usage有兩種連線方式:
其一MongoDB-based 直接連線hidden節點,使用 com.mongodb.hadoop.hive.MongoStorageHandler做資料Serde
其二BSON-based 將資料dump成bson檔案,上傳到HDFS系統,使用 com.mongodb.hadoop.hive.BSONSerDe
MongoDB-based方式
hive> CREATE TABLE eventlog
> (
> id string,
> userid string,
> type string,
> objid string,
> time string,
> source string
> )
> STORED BY 'com.mongodb.hadoop.hive.MongoStorageHandler'
> WITH SERDEPROPERTIES('mongo.columns.mapping'='{"id":"_id"}')
> TBLPROPERTIES('mongo.uri'='mongodb://username:[email protected]:port/xxx.xxxxxx');
hive> select * from eventlog limit 10;
OK
5757c2783d6b243330ec6b25 NULL shb NULL 2016-06-08 15:00:07 NULL
5757c27a3d6b243330ec6b26 NULL shb NULL 2016-06-08 15:00:10 NULL
5757c27e3d6b243330ec6b27 NULL shb NULL 2016-06-08 15:00:14 NULL
5757c2813d6b243330ec6b28 NULL shb NULL 2016-06-08 15:00:17 NULL
5757ee443d6b242900aead78 NULL shb NULL 2016-06-08 18:06:59 NULL
5757ee543d6b242900aead79 NULL smb NULL 2016-06-08 18:07:16 NULL
5757ee553d6b242900aead7a NULL cmcs NULL 2016-06-08 18:07:17 NULL
5757ee593d6b242900aead7b NULL vspd NULL 2016-06-08 18:07:21 NULL
575b73b2de64cc26942c965c NULL shb NULL 2016-06-11 10:13:06 NULL
575b73b5de64cc26942c965d NULL shb NULL 2016-06-11 10:13:09 NULL
Time taken: 0.101 seconds, Fetched: 10 row(s)
這時HDFS裡是沒有存任何資料的,只有與表名一樣的資料夾
當你處理的時候,它是直接處理mongo裡最新的資料。當然,如果你想存到HDFS裡也可以,用CTAS語句就可以。
hive> create table qsstest as select * from eventlog limit 10;
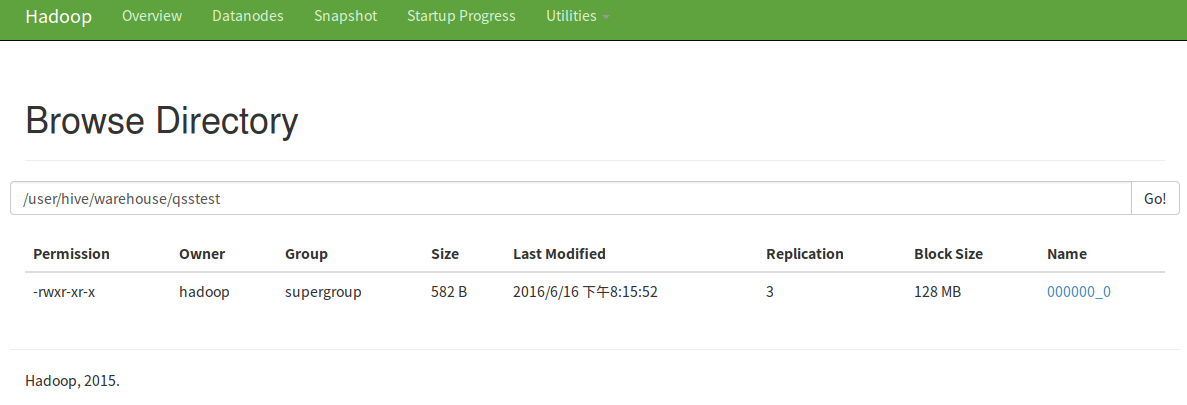
還可以下載下來呢
PS:mongo的使用者要有讀寫許可權,jar包別忘了拷進去!
另一種方式我感覺有點沒必要,沒試,但我找到一篇部落格詳細寫了。
下面轉自:MongoDB與Hadoop技術棧的整合應用
BSON-based方式
BSON-based需要先將資料dump出來,但這個時候的dump與export不一樣,不需要關心具體的資料內容,不需要指定fields list.
mongodump --host=datatask01:29017 --db=test --collection=ldc_test --out=/tmp
hdfs dfs -mkdir /dev_test/dli/bson_demo/
hdfs dfs -put /tmp/test/ldc_test.bson /dev_test/dli/bson_demo/
- 建立對映表
create external table temp.ldc_test_bson
(
id string,
fav_id array<int>,
info struct<github:string, location:string>
)
ROW FORMAT SERDE "com.mongodb.hadoop.hive.BSONSerDe"
WITH SERDEPROPERTIES('mongo.columns.mapping'='{"id":"id","fav_id":"fav_id","info.github":"info.github","info.location":"info.location"}')
STORED AS INPUTFORMAT "com.mongodb.hadoop.mapred.BSONFileInputFormat"
OUTPUTFORMAT "com.mongodb.hadoop.hive.output.HiveBSONFileOutputFormat"
location '/dev_test/dli/bson_demo/';OK,我們先來看下query的結果
0: jdbc:hive2://hd-cosmos-01:10000/default> select * from temp.ldc_test_mongo;
+--------------------+------------------------+-----------------------------------------------------------------+--+
| ldc_test_mongo.id | ldc_test_mongo.fav_id | ldc_test_mongo.info |
+--------------------+------------------------+-----------------------------------------------------------------+--+
| @Tony_老七 | [3,33,333,3333,33333] | {"github":"https://github.com/tonylee0329","location":"SH/CN"} |
+--------------------+------------------------+-----------------------------------------------------------------+--+
1 row selected (0.345 seconds)這樣資料就儲存在一個table,使用中如果需要開啟陣列,可以這樣
SELECT id, fid
FROM temp.ldc_test_mongo LATERAL VIEW explode(fav_id) favids AS fid;
-- 訪問struct結構資料
select id, info.github from temp.ldc_test_mongo//根據不同的資料型別進行反序列操作,複雜型別在內容做element的迴圈,最終呼叫的都是對原子型別的操作.
public Object deserializeField(final Object value, final TypeInfo valueTypeInfo, final String ext) {
if (value != null) {
switch (valueTypeInfo.getCategory()) {
case LIST:
return deserializeList(value, (ListTypeInfo) valueTypeInfo, ext);
case MAP:
return deserializeMap(value, (MapTypeInfo) valueTypeInfo, ext);
case PRIMITIVE:
return deserializePrimitive(value, (PrimitiveTypeInfo) valueTypeInfo);
case STRUCT:
// Supports both struct and map, but should use struct
return deserializeStruct(value, (StructTypeInfo) valueTypeInfo, ext);
case UNION:
// Mongo also has no union
LOG.warn("BSONSerDe does not support unions.");
return null;
default:
// Must be an unknown (a Mongo specific type)
return deserializeMongoType(value);
}
}
return null;
}
// 轉為java的原子型別儲存.
private Object deserializePrimitive(final Object value, final PrimitiveTypeInfo valueTypeInfo) {
switch (valueTypeInfo.getPrimitiveCategory()) {
case BINARY:
return value;
case BOOLEAN:
return value;
case DOUBLE:
return ((Number) value).doubleValue();
case FLOAT:
return ((Number) value).floatValue();
case INT:
return ((Number) value).intValue();
case LONG:
return ((Number) value).longValue();
case SHORT:
return ((Number) value).shortValue();
case STRING:
return value.toString();
case TIMESTAMP:
if (value instanceof Date) {
return new Timestamp(((Date) value).getTime());
} else if (value instanceof BSONTimestamp) {
return new Timestamp(((BSONTimestamp) value).getTime() * 1000L);
} else if (value instanceof String) {
return Timestamp.valueOf((String) value);
} else {
return value;
}
default:
return deserializeMongoType(value);
}
}相關推薦
Hadoop與MongoDB整合(Hive篇)
1.背景 公司希望使用MongoDB作為後端業務資料庫,使用Hadoop平臺作為資料平臺。最開始是先把資料從MongoDB匯出來,然後傳到HDFS,然後用Hive/MR處理。我感覺這也太麻煩了,現在不可能沒有人想到這個問題,於是就搜了一下,結果真找到一個Mon
Spring Data 與MongoDB 整合五:操作篇(分頁)
一.簡介 SpringData MongoDB提供了org.springframework.data.mongodb.core.MongoTemplate對MongoDB的find的操作,我們上一篇介紹了基本文件的查詢,我們今天介紹分頁查詢,分頁查詢
Spring Data 與MongoDB 整合四:操作篇(查詢)
一.簡介 spring Data MongoDB提供了org.springframework.data.mongodb.core.MongoTemplate對MongoDB的CRUD的操作,上一篇我們介紹了對MongoDB的新增和刪除, 今天
輕輕鬆鬆學習SpringBoot2:第二十五篇: Spring Boot和Mongodb整合(完整版)
今天主要講的是Spring Boot和Mongodb整合我們先來回顧一下前面章節的相關內容前面我們講了SpringBoot和mysql整合,並且講了操作資料庫的幾種方式自動生成表資料庫操作操作篇回到正題,mongodb的安裝在這就不累述了,win版本的去官網下載,然後一直下一
【MongoDB】NoSQL Manager for MongoDB 教程(基礎篇)
好的 log 很難 gpo ssi next 破解 情況 eight 前段時間,學習了一下mongodb,在客戶端工具方面,個人認為 NoSQL Manager for MongoDB 是體驗比較好的一個,功能也較齊全。可惜在找教程的時候,發現很難找到比較詳細的
『中級篇』docker之CI/CD持續整合-(終結篇)(77)
>原創文章,歡迎轉載。轉載請註明:轉載自IT人故事會,謝謝!>原文連結地址:『中級篇』docker之CI/CD持續整合-(終結篇)(77) 今天是中級終結篇的最後一次了,想想在二個月的時間,每天的堅持學習和更新收穫還是滿滿的,跟我一起學習的小夥伴不知道你收穫到了嗎? 想說的
框架整合——SpringMVC與MyBatis整合(超詳細)
SpringMVC與MyBatis是我們現在最流行的開發框架組合之一,這裡我來整理一下框架的整合搭建過程 前言 使用IDE:IntelliJ IDEA JDK:1.8 開啟IDEA,新建maven工程 第一步:開啟IDEA,點選Create New Pro
影象腐蝕與影象膨脹(Python篇)
在大學期間積累過一定的影象處理經驗,OCR技術在我的日常工作中偶爾會用到,還是比較重要的。本文介紹影象的膨脹和腐蝕的基本概念及其各自的程式碼實現。 1.膨脹和腐蝕的基本概念 &nb
WebService入門 - CXF與Spring整合 (maven專案)
可參考CXF官網-使用Spring編寫服務文件:http://cxf.apache.org/docs/writing-a-service-with-spring.html 1.新增依賴 <!-- spring與cxf 整合webservice 所需 -->
Memcached客戶端(memcached-Java-client)與 Spring整合(單伺服器)
Memcached客戶端與Spring整合,客戶端使用的是Memcached-Java-Client-release_2.6.3 1. 配置Maven <!-- Memcached client --> <dependency> <g
阿里雲clouder認證—雲資料庫管理與資料遷移(實戰篇)
阿里雲clouder認證—雲資料庫管理與資料遷移 由於關於雲資料庫管理與資料遷移理論知識太多,我已上傳了資源,有需要的可以下載看下 簡單的在這裡說下一些專有名詞: R
spring-cloud與netflixEureka整合(註冊中心)
eureka 集群 uil brush enabled cor scons sta show 基礎依賴 compile(‘org.springframework.boot:spring-boot-starter-actuator‘) compile(‘org.spring
kafka生產者消費者API 與sparkStreaming 整合(scala版)
maven配置檔案 <!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka --> <dependency>
高德APP啟動耗時剖析與優化實踐(iOS篇)
前言最近高德地圖APP完成了一次啟動優化專項,超預期將雙端啟動的耗時都降低了65%以上,iOS在iPhone7上速度達到了400毫秒以內。就像產品們用後說的,快到不習慣。算一下每天為使用者省下的時間,還是蠻有成就感的,本文做個小結。 (文中配圖均為多才多藝的技術哥哥手繪) 啟動階段效能多維度
Hive與HBase整合(例項)
例項1 1.先在Hbase中建立表(三列族): create 'ceshi7', {NAME=>'TIME',VERSIONS=>1,BLOCKCACHE=>true,BLOOMFILTER=>'ROW',COMPRESSION=>'SNA
SpringBoot和hadoop元件Hive的整合(填坑)
說實話,SpringBoot和Hive的整合還是有不少坑的,最主要的坑就是jar包衝突的問題,這個坑我這裡添了我遇到的坑,我提供了原始碼,放在後邊的連結中,以下是部分的程式碼。 1.上maven依賴,如下: <project xmlns="http://maven.
android與C# WebService基於ksoap通信(C#篇)
ldo art fadein length col scripts append hid ldoc 1.打開VS 2013新建項目>>ASP.NET空WEB應用程序(我用的是.net 4.0) 2.在剛建立的項目上加入新建項(Web
【iOS與EV3混合機器人編程系列之二】工欲善其事,必先利其器(準備篇)
style 混合 版權 相同 開發 code 操作系統 圖形 ipa 在上一篇文章中,我們論述了iOS與EV3結合後機器人開發的無限可能。那麽,大家要不要一起來Hacking一把呢?為了能夠完整地完畢我接下來我講的項目。我們須要做下面準備:1、一臺Mac執行MAC OS
XSS的原理分析與解剖:第三章(技巧篇)**************未看*****************
第二章 != chrom 插入 是把 調用 bject innerhtml ats ??0×01 前言: 關於前兩節url: 第一章:http://www.freebuf.com/articles/web/40520.html 第二章:http://www.free
數組與集合(基礎篇)
效率 變量 hset 取出 集合 初始 queue 字符 行為 一、數組 能存放任意多個同類型的數據 1. 數據的聲明與賦值合並書寫:數據類型[] 變量名 = new 數據類型[長度] ① 聲明:數據類型[] 變量名; ② 賦值:變量名 = new 數據類型[長度] 2