
爬蟲小記:利用cookies跳過登陸驗證碼
前言
在爬取某些網頁時,登陸介面時經常遇到的一個坎,而現在大多數的網站在登陸時都會要求使用者填寫驗證碼。當然,我們可以設計一套機器學習的演算法去破解驗證碼,然而,驗證碼的形式多種多樣,稍微變一下(有些甚至是手機簡訊驗證),整套演算法可能就完全無效了,所以去強行破解驗證碼是一個吃力不討好的活。本文會以知乎網站為例,利用python中的request模組進行的一個模擬登陸,其中用到了reqeust.session下的cookies來跳過登陸這一環節。
方案詳述
下面以模擬登陸知乎為例,利用python3.6進行詳細的過程敘述,建議使用pycharm作為IDE。
首先,我們要將headers給設定好
agent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"
headers = {
"HOST": "www.zhihu.com",
"Referer": "http://www.zhihu.com",
"User-Agent": agent
}接著,用賬號成功登陸一次知乎,並按下“F12”(Chrome瀏覽器),找到Resources下的Cookies,將顯示的Cookies全都複製下來,即下圖紅框中的”Name”和”Value”。
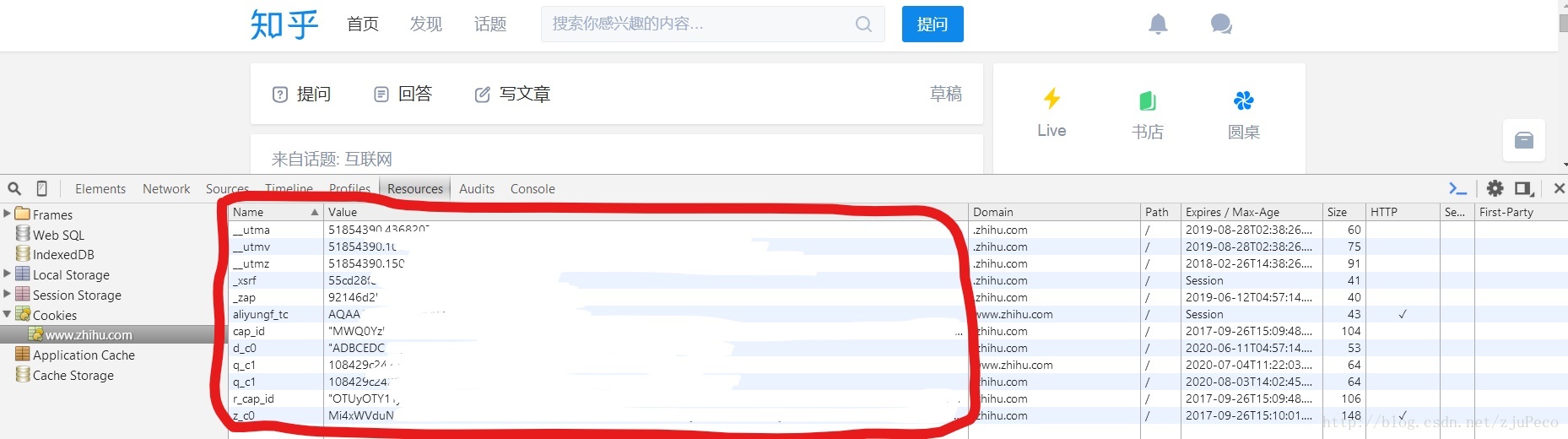
圖中一些個人隱私資訊已經擦去,圖可能有點看不清,但應該能看明白,湊合一下吧~
將複製下來的Cookies寫成字典的形式由於隱私問題,下面是不完整的Cookies。
cookies = {
"cap_id" : "MWQ0Yzk4NGI1Y2M4NG*********",
"r_cap_id" : "OTUyOTY1YjFjMDQ5NGEx*********",
"z_c0" : "Mi4xWVduN0FRQUFB**********",
"q_c1" : "108429c2422245a0********",
"d_c0" : "ADBCEDC-5guPTr*********" 然後建立一個session物件,將headers和cookies賦給session
import Requests
session = Requests.session()
session.headers = headers
requests.utils.add_dict_to_cookiejar(session.cookies, cookies)其中,值得注意的是,session.headers可以是dict,所以直接賦值沒問題,而session.cookies必須是<class ‘requests.cookies.RequestsCookieJar’>,所以要利用requests.utils.add_dict_to_cookiejar進行賦值。
好了,現在我們已經完事具備了,可以直接訪問知乎了,就是這麼簡單。
url = "https://www.zhihu.com/"
response = session.get(url)比如這個時候,我們想把訪問到的頁面給儲存下來,我們就可以這麼幹。
with open("test.html", "wb") as f:
f.write(response.text.encode('utf-8'))登陸進去了之後,就是想怎麼來,就怎麼來了~
這裡還要補充一點就是,我們如果覺得把cookies寫在原始碼中不太雅觀的話,可以將其儲存到本地檔案當中
import json
def save_cookies(cookies):
cookies_file = 'export.json'
with open(cookies_file, 'w') as f:
json.dump(cookies, f)儲存成Json格式之後,可以在cookies過期之後,直接在檔案當中修改cookies,要讀取cookies也很方便
def load_cookies():
cookie_json = {}
try:
with open('export.json', 'r') as cookies_file:
cookie_json = json.load(cookies_file)
except:
print ("Json load failed")
finally:
return cookie_json值得注意的是,這個時候出來的cookies也是dict型別的,別忘了轉換成cookiejar。
完整程式碼
我們可以把上面的程式碼整理一下,寫成下面這樣
檔案1:用來儲存cookies
import json
def save_cookies(cookies):
cookies_file = 'export.json'
with open(cookies_file, 'w') as f:
json.dump(cookies, f)
def main():
cookies = {
"cap_id" : "MWQ0Yzk4NGI1Y2M4NG*********",
"r_cap_id" : "OTUyOTY1YjFjMDQ5NGEx*********",
"z_c0" : "Mi4xWVduN0FRQUFB**********",
"q_c1" : "108429c2422245a0********",
"d_c0" : "ADBCEDC-5guPTr*********",
"aliyungf_tc" : "AQAAAAaQE*************",
"_zap" : "92146d2b-**********",
"_xsrf" : "01124268-4638-***************",
"__utmz" : "51854390.15038440***********",
"__utmv" : "51854390.000**************",
"__utma" : "51854390.4***********"
}
save_cookies(cookies)
if __name__ == '__main__':
main()檔案2:用來模擬登陸
import requests
def load_cookies():
cookie_json = {}
try:
with open('export.json', 'r') as cookies_file:
cookie_json = json.load(cookies_file)
except:
print ("Json load failed")
finally:
return cookie_json
def main():
agent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"
headers = {
"HOST": "www.zhihu.com",
"Referer": "http://www.zhihu.com",
"User-Agent": agent
}
session = requests.session()
session.headers = headers
requests.utils.add_dict_to_cookiejar(session.cookies, load_cookies())
url = "https://www.zhihu.com/"
response = session.get(url)
with open("test.html", "wb") as f:
f.write(response.text.encode('utf-8'))
print ("Done")
if __name__ == '__main__':
main()注意本文創作時間,如果閱讀時已經過了很久,程式碼可能不起效。
如有不足,還請指正~