
solr7.4 配置ikanalyzer和自帶的中文分詞器
阿新 • • 發佈:2019-01-23
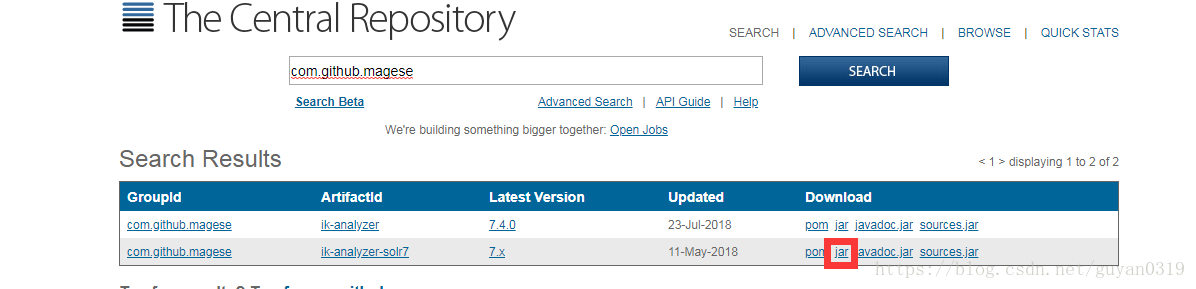
將下載好的jar包放入solr-7.4.0/server/solr-webapp/webapp/WEB-INF/lib目錄中
2、複製新專案的配置檔案
cd /root/tar/solr-7.4.0
mkdir server/solr/ik
cp -r server/solr/configsets/_default/conf server/solr/ik/3、 然後到server/solr/ik/conf目錄中開啟managed-schema檔案,增加如下程式碼
<!-- ik分詞器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer 4、重啟solr
bin/solr restart -force
solr7自帶分詞中文分詞器
1、複製jar包
cp contrib/analysis-extras/lucene-libs/lucene-analyzers-smartcn-7.4.0.jar server/solr-webapp/webapp/WEB-INF/lib 2、複製新專案的配置檔案
cd /root/tar/solr-7.4.0
mkdir server/solr/test
cp -r server/solr/configsets/_default/conf server/solr/test/3、 然後到server/solr/test/conf目錄中開啟managed-schema檔案,增加如下程式碼
<fieldType name="text_hmm_chinese" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>4、重啟solr
bin/solr restart -force
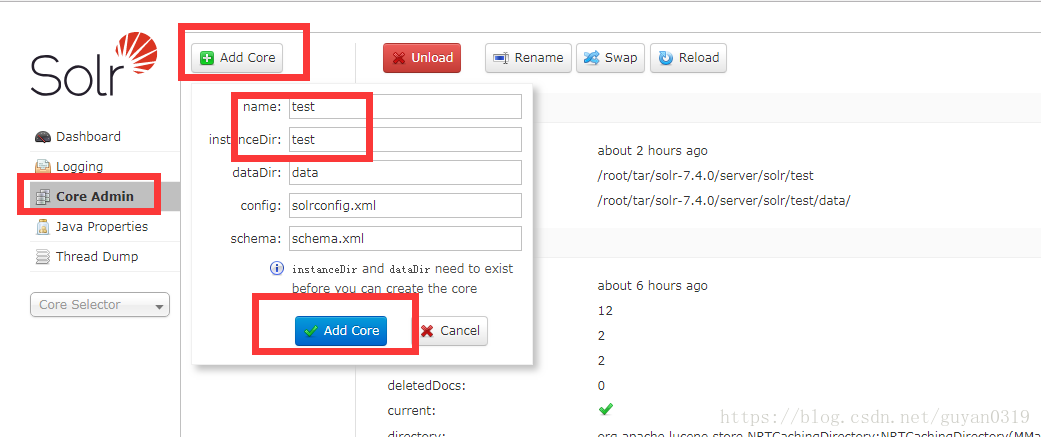
對比兩個分詞的效果
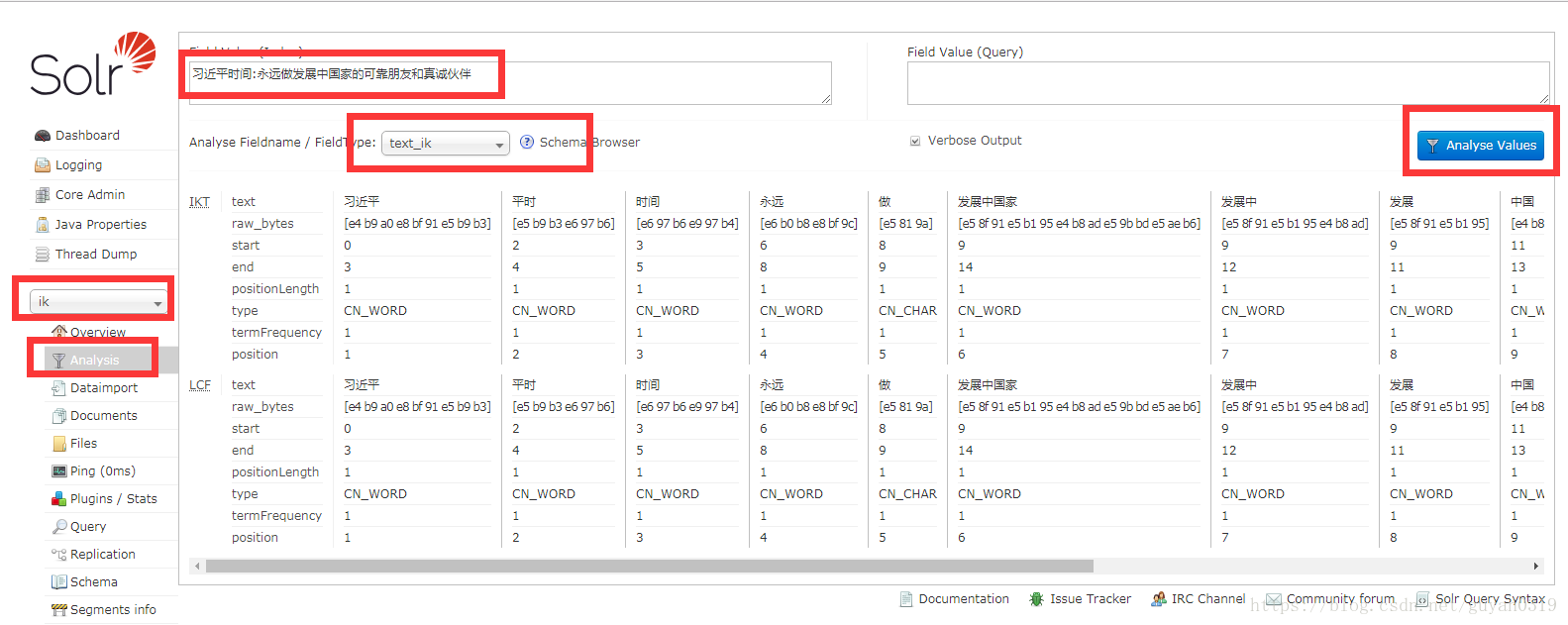
IK分詞器
自帶分詞
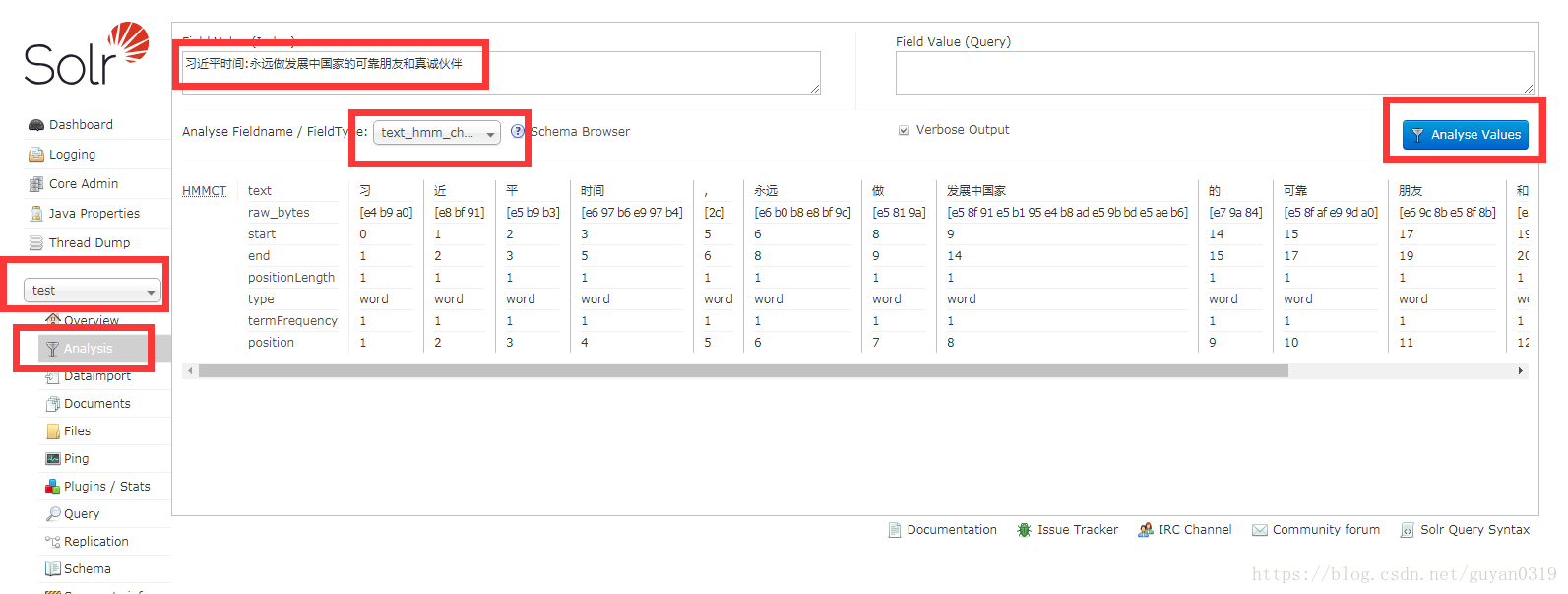
個人感覺IK的語義分析更好些,如有不同意見或建議,歡迎回復。