
Hbase與Oracle比較(列式資料庫與行式資料庫)
1 主要區別
1.1、Hbase適合大量插入同時又有讀的情況
1.2、 Hbase的瓶頸是硬碟傳輸速度,Oracle的瓶頸是硬碟尋道時間。
Hbase本質上只有一種操作,就是插入,其更新操作是插入一個帶有新的時間戳的行,而刪除是插入一個帶有插入標記的行。其主要操作是收集記憶體中一批資料,然後批量的寫入硬碟,所以其寫入的速度主要取決於硬碟傳輸的速度。Oracle則不同,因為他經常要隨機讀寫,這樣硬碟磁頭需要不斷的尋找資料所在,所以瓶頸在於硬碟尋道時間。
1.3、Hbase很適合尋找按照時間排序top n的場景
1.4、索引不同造成行為的差異。
1.5、Oracle 既可以做OLTP又可以做
2 Hbase的侷限:
1、只能做簡單的Key value查詢,複雜的sql統計做不到。
2、只能在row key上做快速查詢。
3 傳統資料庫的行式儲存
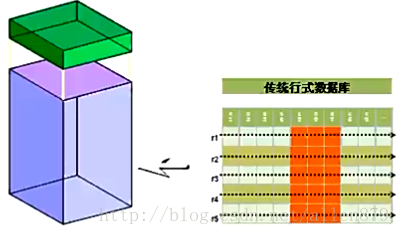
在資料分析的場景裡面,我們經常是以某個列作為查詢條件,返回的結果經常也只是某些列,不是全部的列。行式資料庫在這種情況下的I/O效能會很差,以Oracle為例,Oracle會有一個很大的資料檔案,在這個資料檔案中,劃分了很多block,然後在每個block中放入行,行是一行一行放進去,擠在一起,然後把block塞滿,當然也會預留一些空間,用於將來update。這種結構的缺點是:當我們讀某個列的時候,比如我們只需要讀紅色標記的列的時候,不能只讀這部分資料,我必須把整個block
3.1 B+索引
Oracle中採用的資料訪問技術主要是B數索引:
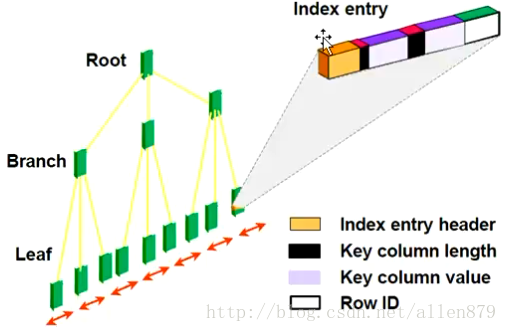
從樹的跟節點出發,可以找到葉子節點,其記錄了key值對應的那行的位置。
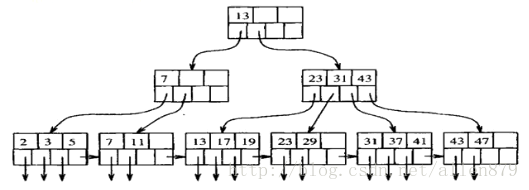
對B樹的操作:
B樹插入——分裂節點
B數刪除——合併節點
4 列式儲存
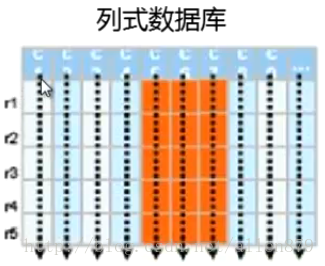
同一個列的資料會擠在一起,比如擠在block裡,當我需要讀某個列的時候,值需要把相關的檔案或塊讀到記憶體中去,整個列就會被讀出來,這樣
同一個列的資料的格式比較類似,這樣可以做大幅度的壓縮。這樣節省了儲存空間,也節省了I/O,因為資料被壓縮了,這樣讀的資料量隨之也少了。
行式資料庫適合OLTP,反倒列式資料庫不適合OLTP。
4.1 BigTable的LSM(Log Struct Merge)索引
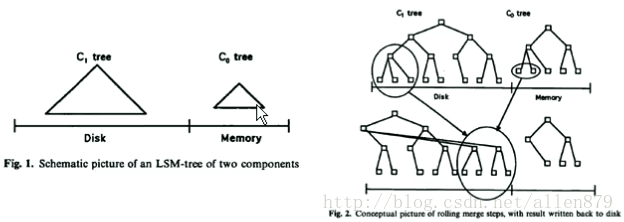
在Hbase中日誌即資料,資料就是日誌,他們是一體化的。為什麼這麼說了,因為Hbase的更新時插入一行,刪除也是插入一行,然後打上刪除標記,則不就是日誌嗎?
在Hbase中,有Memory Store,還有Store File,其實每個Memory Store和每個Store File就是對每個列族附加上一個B+樹(有點像Oracle的索引組織表,資料和索引是一體化的), 也就是圖的下面是列族,上面是B+樹,當進行資料的查詢時,首先會在記憶體中memory store的B+樹中查詢,如果找不到,再到Store File中去找。
如果找的行的資料分散在好幾個列族中,那怎麼把行的資料找全呢?那就需要找好幾個B+樹,這樣效率就比較低了。所以儘量讓每次insert的一行的列族都是稀疏的,只在某一個列族上有值,其他列族沒有值,