
Android:如何快速對系統重啟問題進行歸類
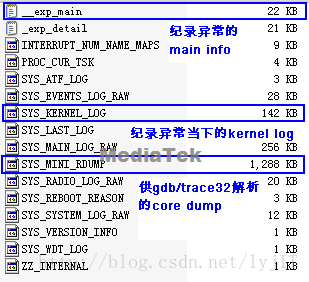
當手機發生系統重啟,即導致kernel重啟的異常時,會在手機中的/data/aee_exp目錄下儲存異常重啟的db。工程師可以通過GAT的bug report功能,或者直接通過adb pull,把對應的db從手機中抓回來。進一步,對於異常重啟的型別,需要通過GAT工具解開db檔案(解開方式參考MTK-online上的文件GAT_User_Guide(Customer).docx之5.1的部分),對裡面的SYS_KERNEL_LOG/SYS_LAST_LOG/SYS_REBOOT_REASON 內容進行解析,才能知道具體的重啟的型別。一般來說,導致kernel重啟的異常重啟,包括Kernel Panic, Watchdog Timeout, Hardware Reboot這三種類型。一個完整的Kernel Panic,其db解開來會包含如下的 檔案:
1. Kernel Panic
即linux kernel發生了無法修復的錯誤,從而導致panic。通過檢視SYS_KERNEL_LOG的內容,kernel Panic進一步可以
分為如下幾類:
a. 普通的data abort。從SYS_KERNEL_LOG中,可以檢索到如下的info:
Unable to handle kernel NULL pointer dereference at virtual addressXXXXXXXX
如上的XXXXXXXX代表某個非法地址。這種型別是最多的。
b. oom 主動觸發的panic。從SYS_KERNEL_LOG中,可以檢索到如下的info:
Kernel panic - not syncing: Out of memory and no killable processes…
此種類型的panic一般是某個process或者APK耗盡了memory資源,從而kernel主動觸發的panic重啟。對於這種型別的重啟,強烈建議工程師把如上的info填寫到eService 的標題中,這樣MTK可以對eService進行一次到位的分配。
c. undefined instruction,未定義指令異常。從SYS_KERNEL_LOG中,可以檢索到如下的info:
Internal error: Oops - undefined instruction
此類異常較為少見,可能是CPU/DRAM 不穩定或者受干擾導致的問題。
d. bad mode異常,即PC處於一個無效的virtual address。從SYS_KERNEL_LOG中,可以檢索到如下的info:
Bad mode in Synchronous Abort handler detected
…
[14820.652408]-(1)[682:VSyncThread_0][] bad_mode+0x78/0xb0
此類異常較為少見,可能的原因是stack錯亂,或者未註冊回撥函式引起。
2.watchdog 超時
a. 底層看門狗超時。從SYS_KERNEL_LOG中,可以檢索到如下的info:
for arm64platformPC is at aee_wdt_atf_info+0x4c8/0x6dc
LR is at aee_wdt_atf_info+0x4c0/0x6dc
for arm32platform
PC is at aee_wdt_irq_info+0x104/0x12c
LR is at aee_wdt_irq_info+0x104/0x12c
此類異常較為常見,多見於底層頻繁irq/bus卡死,導致kicker無法被schedule,從而引起watch dog觸發中斷,引導系統進入FIQ處理流程,最終call到BUG觸發重啟。
b.上層hang_detect 觸發看門狗超時。從SYS_KERNEL_LOG中,可以檢索到如下的info:
[ 2131.086562] (0)[77:hang_detect][Hang_Detect] we should triger HWT …
…
[ 2180.467416]-(0)[77:hang_detect]PC is at aee_wdt_irq_info+0x154/0x170
[ 2180.467426]-(0)[77:hang_detect]LR is at aee_wdt_irq_info+0x154/0x170
…
此異常型別較為常見,多見於GPU/SD卡/eMMC 無法滿足surfacelinger/system_server的通訊需求,從而導致上層卡死,進而主動觸發看門狗超時重啟。對於這種型別的重啟,強烈建議工程師把如上的Hang_Detect關鍵字填寫到eService的標題中,這樣MTK可以對eService進行一次到位的分配。
3. Hardware Reboot
hardware reboot是watch dog直接發出reset訊號,導致整個系統重啟;在重啟之前,並沒有觸發任何異常處理流程。一般情況下,hardware reboot對應的db不會有SYS_KERNEL_LOG 可以排查,只能從SYS_LAST_KMSG獲知異常之前kernel的動作,以及從SYS_REBOOT_REASON 獲知異常時的CPU暫存器值和其它引數。從ZZ_INTERNAL 檔案,可以知道發生了hardware reboot Hardware Reboot,0,0,99,/data/core/,0,,HW_REBOOT,Fri Jul 3 14:31:53 CST 2015,1就上面所羅列的諸多異常重啟,工程師務必把如上黃底部分的log片段拷貝到eService的Description欄位,並把紅色的關鍵字填寫到eService的標題中,這樣,可以大大加快eService的分配流程。